 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
来自ISSCC的七个关于人工智能的新想法
一位谷歌的工程经理呼吁采用新的人工智能架构,包括一种保护数据隐私的分布式方法。在他的演讲之后,在ISSCC(国际固态电路会议)上,有超过六篇学术论文描述了机器学习的新方法。
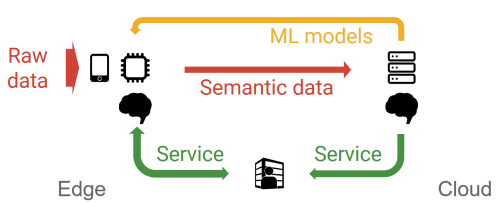
几篇ISSCC论文将计算和存储合并起来,这是一种长期以来追求的研究思想,一些人认为机器学习最终可以带来广泛的商业用途。就谷歌而言,该公司正在探索一种混合方法,让最终用户保留他们的数据,只是将神经网络权重发送到云中的参数服务器进行处理。
最终,谷歌及其同行需要在计算能力方面实现巨大突破,才能实现人工智能在其数据中心的前景。Olivier Temam是这家搜索巨头一项未指明的人工智能计划的经理,Temam表示,机器学习支持的谷歌图片搜索完成一个任务的一个循环就需要110亿次/秒的操作
Temam呼吁采用分布式的方法,这样边缘设备和云服务可以协作训练神经网络。设备在本地使用原始数据进行一些训练,然后将他称为语义数据的更改或神经网络权重发送到云端,神经网络模型在其中会进一步训练和完善。
Temam表示:“出于非常容易理解的原因,人们或公司不想将他们的数据发送到云端,所以我们已经表明可以创建联合学习的模型。”
一位观察者指出,这种方法可能会吸引黑客试图从语义数据中推断出原始数据。
 谷歌呼吁边缘设备和云服务合作进行神经网络培训
谷歌呼吁边缘设备和云服务合作进行神经网络培训
谷歌同意在这里向数百名芯片设计师发表演讲,希望能为更强大的人工智能加速器产生新的点子。设计这种芯片的一个挑战是处理器和神经网络需要的大量内存之间的瓶颈。
搜索巨头需要的内存带宽在100TB/秒的范围。Temam表示,今天的高带宽存储器堆栈的速度慢了两个数量级,而SRAM则太过昂贵而且非常耗电。
一些学者描述了将计算嵌入到内存中的方法。由于各种专用存储器——包括记忆电阻、ReRAM等——的兴起,以及有时会使用大容量存储器或者模拟阵列的、受到大脑启发的计算机设计的影响,这一领域目前非常热门。
麻省理工学院副教授Vivienne Sze在2016年与人合著了一篇关于Eyeriss架构的论文,该架构可以解决这个问题。Vivienne Sze表示:“我们发现神经网络绝大部分能量都耗费在数据移动之中。”她表示:“你需要管理大量的数据和权重,所以数据移动消耗掉的能源比计算还要多。”
她在麻省理工学院的小组现在正在研究的灵活架构可以运行越来越多种类的神经网络,包括开始出现的许多简化。他们还在探索在机器人和无人机相机等应用上单位功率可以完成多少神经网络加速。
谷歌的Temam表示,只要实用而且成本低廉,该公司就可以接受所有新想法。Temam表示:“我们希望不断降低成本,以便更大规模地部署,并最终实现最佳性能。”
后面的几页扼要介绍了六篇关于人工智能加速器的ISSCC论文。其中大部分论文的目标都是降低推理工作的能耗,其中有一些支持一些培训工作。
使用TSV和电感耦合来堆叠SRAM

来自日本两所大学的Quest处理器使用通孔过孔和电感耦合将八个层中的96 MB SRAM堆叠起来。另外,它的24个内核每一个都有自己专用的4Mb的SRAM缓存。
韩国加速1到16位的CNN和RNNs

KAIST的研究人员为卷积和递归网络设计了一种加速器,分辨率为1至16位。它使用了均衡功能加载器(AFL),最大限度地减少了对片外存储访问的需求。
神经网络分类器采用了SRAM阵列
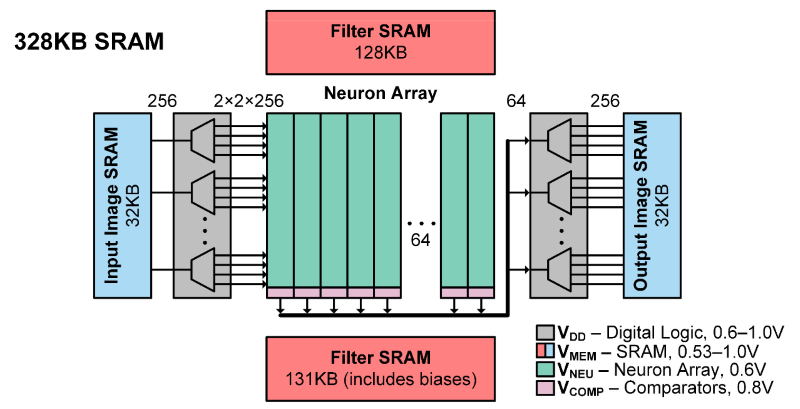
斯坦福大学和Imec的研究人员描述了一款28-nm分类器,芯片上包含了所有必需的存储器。它能够以中等的准确度,以每个任务3.79微焦的能耗处理任务,能做到这一点,部分的原因是针对卷积网络使用了约束BinaryNet算法。
SRAMs 存储权重,而ADCs负责计算它们
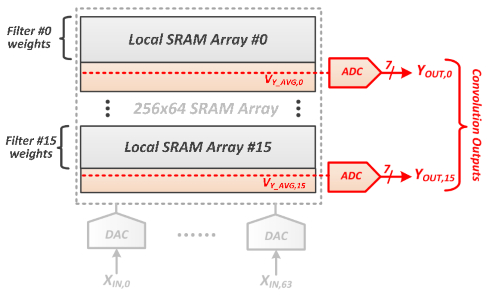
麻省理工学院的研究人员将神经网络权重存储在SRAM阵列中,以消除外部存储器非常耗电的读取操作。每个阵列上的模数转换器计算部分卷积。
低功耗阵列处理推理,培训
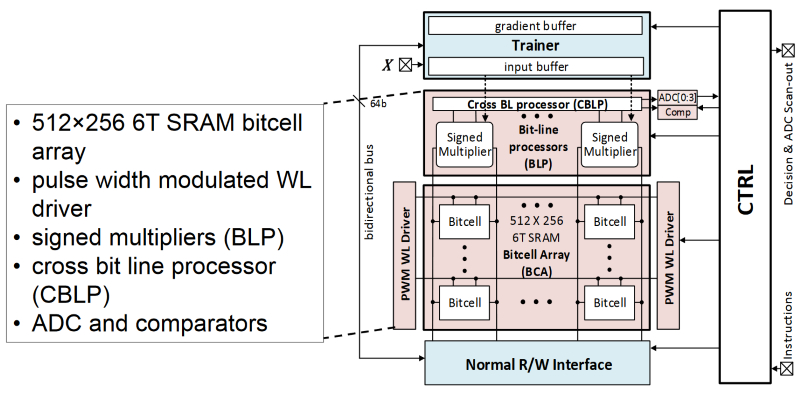
伊利诺斯大学的内存中分类器达到了42皮焦耳/决定。其SRAM阵列具有推理和训练模式。
碳纳米管遇到电阻式RAM单元

伯克利、麻省理工学院和斯坦福大学的一批资深研究人员使尽浑身解数,采用整体3D工艺创造了一种基于1952个碳纳米管FET和224个电阻式RAM单元的新型器件。这个所谓的超维计算纳米系统处理语言翻译任务的准确率达到了98%。
编译:科技行者>


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

Snowflake AI挑战传统语言学:万千茫茫文字中,LLM真的只是"随机鹦鹉"吗?
这项由Snowflake AI Research发表的研究挑战了传统语言学对大型语言模型的批评,通过引入波兰语言学家Mańczak的理论框架,论证了LLM的成功实际上验证了"频率驱动语言"的观点。研究认为语言本质上是文本总和而非抽象系统,频率是其核心驱动力,为重新理解AI语言能力提供了新视角。

Yale大学团队推出"免费博士劳工":让AI研究助手像真人团队一样工作的革命性框架
freephdlabor是耶鲁大学团队开发的开源多智能体科研自动化框架,通过创建专业化AI研究团队替代传统单一AI助手的固化工作模式。该框架实现了动态工作流程调整、无损信息传递的工作空间机制,以及人机协作的质量控制系统,能够自主完成从研究构思到论文发表的全流程科研工作,为科研民主化和效率提升提供了革命性解决方案。

德国马普所团队发明"智能大脑重新布线"技术:让AI专家模型学会即时调整自己
德国马普智能系统研究所团队开发出专家混合模型的"即时重新布线"技术,让AI能在使用过程中动态调整专家选择策略。这种方法无需外部数据,仅通过自我分析就能优化性能,在代码生成等任务上提升显著。该技术具有即插即用特性,计算效率高,适应性强,为AI的自我进化能力提供了新思路。

聊天机器人怎么不在线聊天中"迷路"?Algoverse AI研究团队的熵值导航新突破
Algoverse AI研究团队提出ERGO系统,通过监测AI对话时的熵值变化来检测模型困惑程度,当不确定性突然升高时自动重置对话内容。该方法在五种主流AI模型的测试中平均性能提升56.6%,显著改善了多轮对话中AI容易"迷路"的问题,为构建更可靠的AI助手提供了新思路。

Snowflake AI挑战传统语言学:万千茫茫文字中,LLM真的只是"随机鹦鹉"吗?

Yale大学团队推出"免费博士劳工":让AI研究助手像真人团队一样工作的革命性框架

德国马普所团队发明"智能大脑重新布线"技术:让AI专家模型学会即时调整自己

聊天机器人怎么不在线聊天中"迷路"?Algoverse AI研究团队的熵值导航新突破
