 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
使用机器学习前,企业需要做的10项准备工作
并非每一个问题都可以通过机器学习来解决,也并不是每个企业都为AI的应用做好了准备。
比如,企业要确定具体的应用场景、是否有足够的数据进行分析、要建立预测模型、要有定义模型和训练模型的人员和工具......等等。
为此,本文将具体阐述使用人工智能、深度学习和机器学习时,企业需要做的10项准备工作。
那么,企业到底需要多少数据?无论是进行普通的统计预测,还是机器学习或者深度学习,要考虑的因素越多,所需的数据就越多。总的来说,机器学习比统计预测需要更多的数据,而深度学习所需的数据更是成倍的。
以销售预测问题为例,由于零售行业的季节性很强,这就要求企业积累多年具有统计学意义的重要月度数据,以便能够校正每月的周期性变化并建立年度趋势,从而用于标准的时间序列分析模型。
比如,企业可以通过统计模型来分析5年内全国范围连锁店的每月衬衫销售额,并基于此预测下个月的衬衫总销售量,以及诸如某地女衬衫销售额占全国总销售额的百分比、蓝色短袖衬衫的销售额占衬衫总销售额的百分比等更具体的数字。当然,在这个过程中,企业还需要特别注意实际结果与模型预之间的差距。
而如果还要考虑外部因素,例如天气和时尚趋势。企业还可以把历史气象数据引入到模型中进行测试。当然,在时间序列统计模型中这么做可能比较困难,但可以尝试使用决策树回归模型来实现。
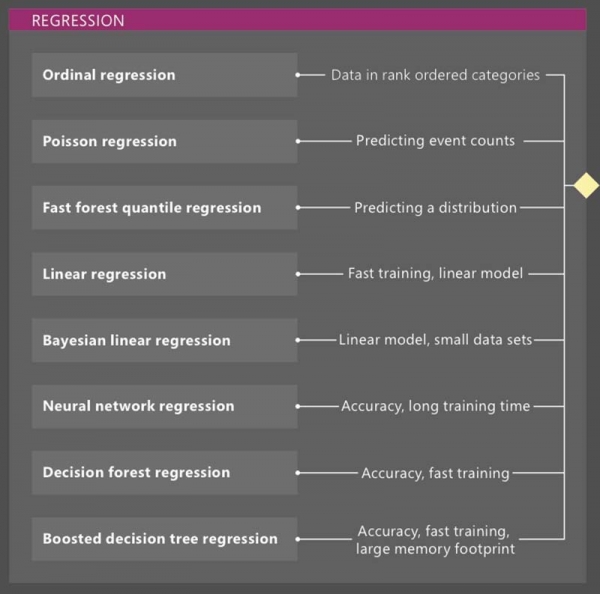
如上图,企业可以通过尝试其它7种用于回归的机器学习模型,然后把每种模型的“成本”(归一化误差函数)与去年的实际结果进行比较,从而找出最佳模型。
例如,当企业想知道下个月海军蓝色的衣服比去年同期卖得更好还是更差?就可以查看海军蓝服装的所有月度销售额并预测年度时尚趋势,也可以将其引入到机器学习模型中进行分析。除此之外,企业也可以根据时尚媒体上获取的信息,对模特进行手动更正。
在这一过程中,通过创建一个深度神经网络,能够让预测效果更好。你甚至会发现,对于添加的每个隐藏层,都可以将回归误差提高几个百分点,直到增加下一层再也无法改善效果为止。其中,收益递减的关键,可能是因为模型中没有更多功能可以识别,或者也有可能是因为没有足够的数据来支持更多的提升空间。
-2- 数据科学家
当然,企业必须要有一个能够建立上面提到的所有模型的人。他需要足够的经验、直觉、编程能力和统计学背景。
即便当前很多机器学习的产品和服务提供商都表示,“任何人”或“任何商业角色”都可以使用他们预先训练好的应用机器学习模型。但现实情况是,企业的数据可能并不适用现有模型。因此,还需要数据分析师和数据科学家来指导和帮助对模型进行训练。
-3- 追踪和采集重要的相关变量数据
此外,企业还需要具有相关变量的数据,从多个维度采集和使用数据,从而避免统计上所说的“不明原因的方差”。
当然,某些独立变量(如天气观测)的测量和采集是很难、不切实际或者高成本的。以化学领域为例,当你将铅电镀到铜上时,就可以测量氟硼酸电镀液的温度和浓度,并记录正极上的电压。但这要求溶液中含有的肽是适量的,从而获得良好的粘附性。否则,你无法知道这关键催化剂的数量,也无法使用其他变量解释电极板质量的变化。
-4- 找到清理和转换数据的方法
通常情况下,数据都非常复杂,其质量也常常参差不齐。比如,在采集过程中,可能缺少一个或多个值,个别值也可能超出范围或与其他值不一致,回答问题的人可能不了解问题或者会编造答案等等。
而这,则意味着分析过程中的数据过滤需要花费最多的精力,这甚至可能占到总分析时间的80%到90%。如果在ETL(提取、转换和加载)过程中将所有数据保留在数据仓库或数据湖中,就可能让无关的或者质量不高的数据也被保存下来。
当然,即使是经过精确过滤的数据也可能需要进一步转换,才能对其进行良好的分析。与统计方法类似,当每个可能状态的参数相似时,即当所有变量的范围都归一化时,机器学习模型的效果最好。因此,企业必须找到能够更好地清理和转换数据的方法。
-5- 重新审视所有变量数据及其相关性
下一步,我们需要退后一步,再看看所有的变量及其相关性。
探索式数据分析可以快速显示所有变量的范围和分布,不管相关变量之间是相互依赖的还是独立的、集群在哪里、哪里可能有异常值。当企业拥有高度相关的变量时,通常从分析中删除一个或者多个变量是有用的。企业还可以执行类似于逐步多元线性回归的方法来确定最佳的变量选择。
然而,这一并不意味着最终模型是线性的,只是在引入更多复杂因素之前,需要尝试一下简单线性模型;如果企业的模型中有太多的专业术语,最终得到的将会是一个由多种因素决定的系统模型。
-6- 通过反复尝试寻找最佳模型
如果企业的目标是针对一个探索性很强但具有挑战性的领域(例如图片特征识别和语言识别),就可能只会尝试某个所谓“最佳”的模型。然而,这些模型通常是计算密集度最高的深度学习模型,例如,在图像识别的情况下具有卷积层以及用于语音识别的长期短期记忆(LSTM)层。如果企业需要训练这些深度神经网络,就需要比办公环境更高的计算能力。
-7- 拥有训练深度学习模型所需的计算能力
数据集越大,深度学习模型中的层就越多,训练神经网络所需的时间也就越长。
关于训练时间的问题,有一个方法就是使用通用图形处理单元(GPU)来解决。一个K80 GPU配合CPU,其训练速度通常可以达到仅使用CPU的5到10倍。如果企业可以将网络的整个“内核”整合到GPU的本地内存中,那么训练速度甚至可以达到仅使用CPU的100倍。
除了单个GPU之外,企业还可以设置协调的CPU和GPU网络,以便在更短的时间内解决更大的问题。除非你愿意花一整年时间来训练深度学习模型,并拥有庞大的预算,否则你会发现,在云上租用GPU是最具成本效益的选择。包括CNTK、MXNet和TensorFlow在内的几种深度学习框架都支持CPU和GPU的并行计算,并且具有合理的缩放系数,可用于支持GPU的超大型虚拟机(VM)实例网络。
-8- 学会调整或者尝试不同的方法
简单的统计模型考验通过机器学习和深度学习为企业的模型等运作制定标准。但如果你不能用给定的模型来提高分析水平,就应该调整或者尝试一种不同的方法,比如,可以在超参数调整算法的控制下并行设置多个模型训练,并使用最佳结果指导下一个阶段。
-9- 部署预测模型
最终,训练好的模型可以部署和运行在服务器上、云中、个人计算机上或者手机上,以供企业实时地应用。深度学习框架提供了将模型嵌入到Web和移动应用中的各种选择。亚马逊、谷歌和微软也都展示了自己在这方面的实践,甚至有可以通过语音识别操作的消费电子设备和智能手机应用。
-10- 定期更新模型
当然,你可能还会发现,即便是训练好的模型,由于数据会随着时间的推移而变化,因此模型的错误率也会随着时间的推移而增加。比如,企业的销售模式会发生变化,竞争对手会发生变化,款式会发生变化,经济形势会发生变化……
为此,大多数深度学习框架都可以选择对旧数据进行再训练,并用新模型替换原来的预测服务。如果你每月都能定期更新的话,基本上就能够保持与时俱进。否则,最终你的模型就会变得太过时而不可靠。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来
韩国KAIST开发的Vector Prism系统通过多视角观察和统计推理,解决了AI无法理解SVG图形语义结构的难题。该系统能将用户的自然语言描述自动转换为精美的矢量动画,生成的动画文件比传统视频小54倍,在多项评估中超越顶级竞争对手,为数字创意产业带来重大突破。

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
华为诺亚方舟实验室提出VersatileFFN创新架构,通过模仿人类双重思维模式,设计了宽度和深度两条并行通道,在不增加参数的情况下显著提升大语言模型性能。该方法将单一神经网络分割为虚拟专家并支持循环计算,实现了参数重用和自适应计算分配,为解决AI模型内存成本高、部署难的问题提供了全新思路。

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
