 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
“重复”内容识别:一场人类与机器间的智能竞赛
有时候,人类与机器在判断哪些内容属于“重复内容”时会产生某些分歧。
机器学习与基于算法的智能系统虽然拥有令人印象深刻的表现,但同时也缺少人类天然存在的一种能力:常识。
众所周知,在多个页面上放置相同的内容会产生重复内容。但是,如果我们打算在多个页面内生成关于相似事物的内容,又会发生怎样的情况?算法会将其标记为“重复”,但人类则能够轻松区分这些页面:
-电子商务:具有多种变体或关键差异的类似产品。
-旅游:酒店分店、目的地套餐、内容相似。
-分类:相同项目的详尽清单。
-企业:本地分支机构的页面,在不同地区提供相同的服务。
为什么会出现这些问题?我们该如何发现此类问题?又应怎样解决这些问题?
重复内容的风险
在用户进行搜索时,重复内容会通过以下方式影响您的网站对用户的可见性:
-因无意中存在相同关键词而失去唯一匹配网页的排名。
-由于谷歌只会选择其中一个网页作为规范化,因此无法对群组中的网页进行排名。
-由于内容被严重简化,因此失去网站权威性。
机器如何识别重复内容
谷歌公司利用多种算法确定两个页面或者页面中的多个部分是否存在内容重复,谷歌将根据相关结果将内容判定为“明显相似”。
谷歌公司的相似性检测基于其专利Simhash算法。这种算法能够分析网页当中的内容块,而后将每个内容块计算为唯一标识符,最终为各个页面生成一个散列,或者称为“指纹”。
由于网页数量巨大,因此可扩展性至关重要。目前,Simhash是唯一可行的大规模重复内容查找方法。
Simhash指纹拥有以下特性:
-计算成本低廉。其以目标页面的单一爬取结果为生成基础。
-由于长度固定,因此不同指纹间易于比较。
-能够找到具有高重复可能性的内容。与其它多种算法不同,Simhash能够将页面上的微小变化体现为散列中的微小变化。
最后一点意味着任何两个指纹之间的差异都可以通过算法进行衡量,并表示为百分比形式。为了降低每个页面的评估成本,谷歌公司采用了以下技术:
-聚类:将多组具有一定相似度的页面分于同一群组。由于其它所有不同分类的指纹都已经被排除,因此只需要比较该群组内的指纹,即可得出相对正确的结论。
-评估:对于规模极为庞大的聚类,在计算一定数量的指纹之后利用平均相似性进行判断。

比较页面指纹。图片来源:用于网络爬取的近重复文档检测(归谷歌所有)
最后,谷歌方面利用加权相似率排除具有相同内容的特定内容块(样板:标题、导航、侧边栏、页脚;免责声明等)。其会考虑到页面主题,并利用n-gram分析来确定页面上出现频率最高的词语,同时结合站点上下文判断这些词语的重要性。
利用Simhash分析重复内容
我们将利用Simhash查看被标记为相似的内容聚类图。此图表来自OnCrawl,其中涵盖了对重复内容聚类中重复内容策略的分析过程。
OnCrawl的内容分析还包括相似率、内容聚类以及n-gram分析。OnCrawl也在开发一款实验性热图,希望直接覆盖在网页之上表示各个内容块的相似性。
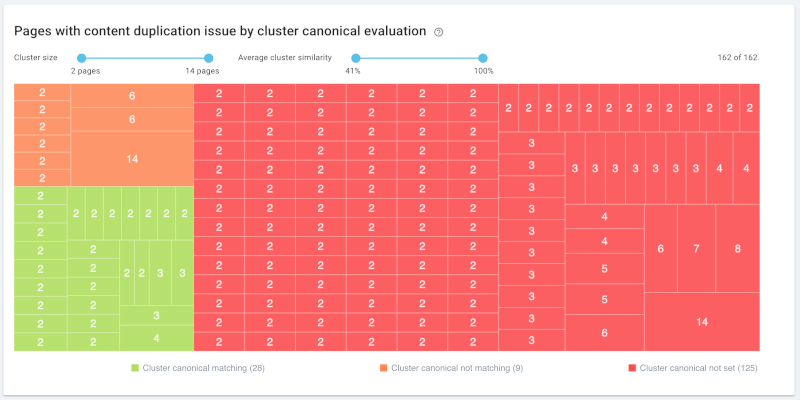
按内容相似性进行网站绘图。其中每个块代表具有类似内容的聚类,不同颜色则表示每个聚类间规范化化策略的一致性。资源来源:OnCrawl。
利用规范化进行聚类验证
利用规范化URL指示一组相似页面当中的主页面,使得我们能够主动对大量页面进行聚类。在理想情况下,以规范化为基础建立的聚类应该与由Simhash建立的聚类完全相同。

规范化聚类与相似性聚类(绿色部分)间的匹配结果。结论:有6页内容为100%相似,这意味着您的规范化策略与谷歌的Simhash分析以同样的方式对其进行处理。
如果结果与上图不符,则通常意味着您的网站之上不存在规范化策略:
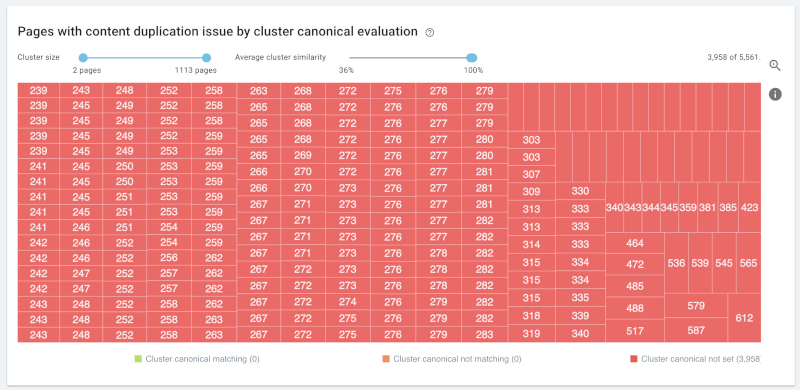
无规范化声明:各个包含成百上千个页面的聚类之间,拥有着99%到100%的平均相似度。谷歌公司可能会采用规范URL。您无法控制哪些页面参与排名,哪些不参与。
或者,由于您的规范化策略与谷歌在类似内容的聚类处理方法之间存在冲突:
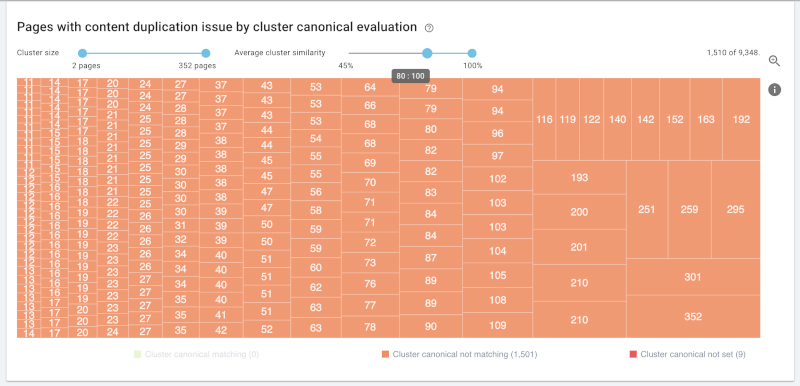
规范化问题:相似性超过80%且各聚类拥有多个标准URL的大型聚类。谷歌公司会强制使用自己的标准URL,或者将您希望保留的重复页面索引排除在搜索索引之外。
您网站的聚类与以上聚类不同。您已经遵循了重复内容的最佳处理实践,包含相同内容的URL(例如可打印/移动版本或CMS生成的备用网址)会声明正确的规范URL。

在规范化处理后绘制出的相似性聚类。
过滤掉由规范化策略正确处理的重复内容。其余的非规范化URL即为您希望进行排名的页面。
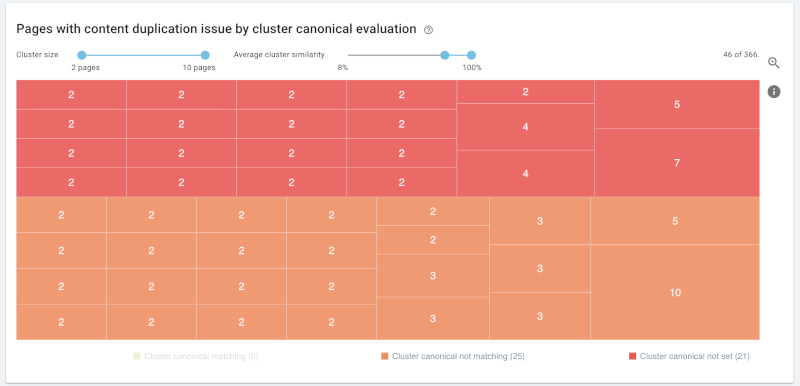
以原有映射图为基础,移除已验证(绿色)聚类以及相似性低于80%的聚类。其余46个聚类中,大部分只包含2个页面。
仍然出现在基于Simhash与语义分析聚类中的URL,即为您与谷歌认为存在重复问题的页面。
解决唯一内容的内容重复问题
目前还没有真正令人满意的方法,能够纠正机器对于看似重复、实则唯一页面的错误判断:我们无法改变谷歌识别重复内容的具体方式。但是,仍有一些解决方案能够帮助我们与谷歌保持相同的唯一内容判断结论……同时继续根据您选定的关键词进行排名。
以下是适合您网站的五种具体策略。
一、解决边缘情况
首先查看边缘情况,即具有极低或者极高相似率的聚类。
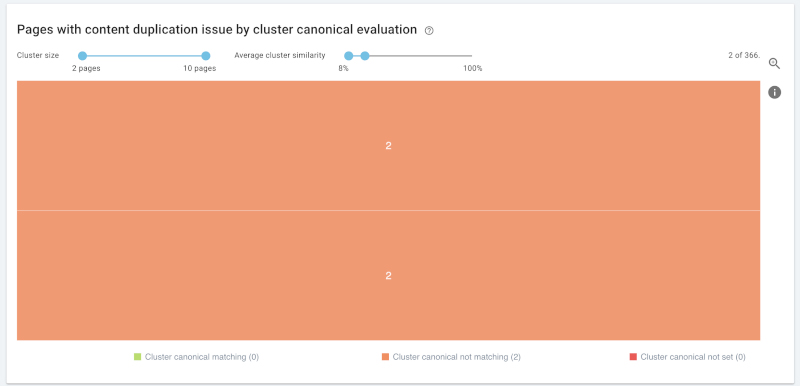
相似度低于20%:相似,但并非高度相似。您可以利用页面中的不同锚文本链接聚类内的各页面,从而通知谷歌将其视为不同的页面。

最大相似度:找出潜在问题。您需要进一步丰富内容以区分不同页面,或者将多个页面合并为同一页面。
二、减少facet数
如果您的重复页面与facet相关,则可能存在 索引问题。保留已经排名的facet,同时限制您允许谷歌进行索引的facet数量。
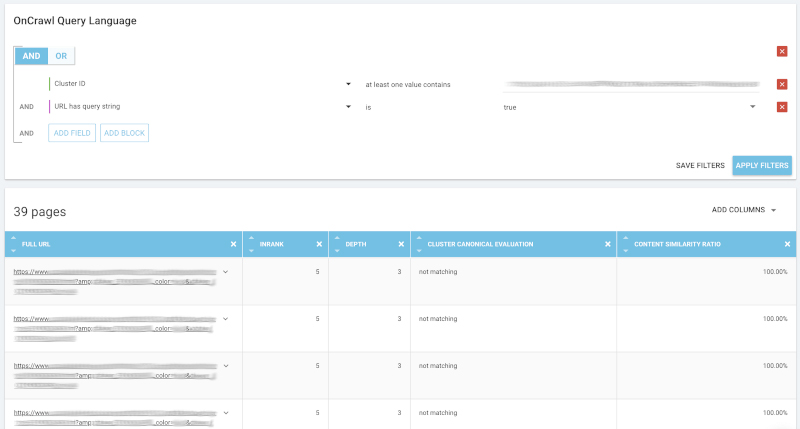
由基于可排名facet的相同页面构成的聚类。资料来源:OnCrawl。
三、提升页面唯一性
请记住:内容的微小差异亦会在Simhash指纹中产生细微的差别。您需要对页面上的内容进行重大更改,而非做出小幅调整。
丰富页面内容:
-向页面内添加文本内容。
- 添加不同的图像描述。
- 包含完整的客户评论。(如果评论适用于多个页面,请合并页面!)
- 添加其它信息。
- 添加相关信息。
-使用不同的图像。
-使用明显不同的锚文本链接至不同页面,并测试实际效果。
-减少相似页面之间的共同源代码量。
-提高页面的语义密度。
- 增加与主题相关的词语量,同时减少填充符。

四、创建排名引用页面
如果无法丰富页面内容,或者当前页面不适合进行丰富,请考虑创建一个替代所有 “重复”页面的单一引用页面。此策略的核心,是在符合内容主旨的前提下将从个关键词融入同一主页面,并将主页面作为推广载体。这种方法特别适合需要将多个版本的产品作为彼此独立的单一页面进行维护的情况。
这项策略还可用于创建针对性需求或者季节性业务的网页。其可提供更为强大的语义与排名,从而改善页面体系。
此策略还适用于广告网站、招聘网站以及其它通常包含大量相似清单的网站。引用页面应按单一特征对各清单进行分组,在这方面位置(城市)是一类广泛适用的分类指标。

如何操作:
1、创建一个引用页面,汇集所有 “重复”产品页面的语义内容。其中应包含您所要使用的全部关键词,并链接至所有 “重复”页面。
2、为引用页面中的每个“重复”页面设置标准URL,同时也为引用页面自身设置标准URL。链接各“重复”页面。
3、优化网站导航以推广引用页面。
4、立足“重复”页面、规范化声明以及组合内容对链接进行强化,从而降低引用页面的排名难度。
五、合并页面
您可能一直在利用相同的内容丰富页面?您可能无法解释为什么要将其全部保留下来?要解决这个问题,页面合并可能是最好的选择。
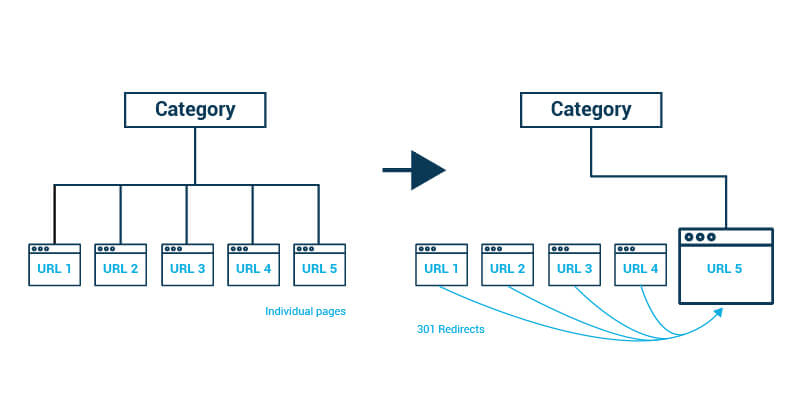
如果您决定将多个页面合并为一个:
-保留执行表现最佳的URL。
-将您正在移除的全部页面重新定向(301)至您要保留的页面。
-将您正在移除的全部页面中的内容,添加至您决定保留并面向聚类中全部关键词进行排名优化的页面当中。
未来的重复内容处理方法
谷歌公司对页面内容的理解能力正在不断发展。随着其样本识别能力以及页面意图区分水平的不断提升,将唯一内容错认为重量内容的状况终将成为历史。
但在达到这样的效果之前,大家仍然有必要思考自己的内容为何会被谷歌算法视为重量内容,并想办法说服算法改变结论——这将成为相似页面实现成功SEO的关键所在。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站


Queen's大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官
Queen's大学研究团队提出结构化智能体软件工程框架SASE,重新定义人机协作模式。该框架将程序员角色从代码编写者转变为AI团队指挥者,建立双向咨询机制和标准化文档系统,解决AI编程中的质量控制难题,为软件工程向智能化协作时代转型提供系统性解决方案。

医疗AI的"显微镜革命":西北工业大学团队发布首个超声影像专用智能助手EchoVLM
西北工业大学与中山大学合作开发了首个超声专用AI视觉语言模型EchoVLM,通过收集15家医院20万病例和147万超声图像,采用专家混合架构,实现了比通用AI模型准确率提升10分以上的突破。该系统能自动生成超声报告、进行诊断分析和回答专业问题,为医生提供智能辅助,推动医疗AI向专业化发展。

上海AI实验室突破自回归图像生成瓶颈:ST-AR让AI"先理解再创造"
上海AI实验室团队发现自回归图像生成模型存在局部依赖、语义不一致和空间不变性缺失三大问题,提出ST-AR训练方法。该方法通过掩码注意力、跨步骤对比学习和跨视角对比学习,让AI"先理解再生成"。实验显示,ST-AR将LlamaGen模型的图像理解准确率提升一倍以上,图像生成质量提升42-49%,为构建更智能的多模态AI系统开辟新路径。

数据中心的智算挑战,英特尔要如何应对?

Queen's大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官

医疗AI的"显微镜革命":西北工业大学团队发布首个超声影像专用智能助手EchoVLM

上海AI实验室突破自回归图像生成瓶颈:ST-AR让AI"先理解再创造"
