 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
利用AI技术评估电视节目中人物的情绪

深度学习通过人脸估算情绪的能力已经愈发强大——具体来讲,只需要查看图像内容,其即可将其中人们的快乐或悲伤心情整理出来。那么我们是否能够将这项技术应用于电视新闻,从而评估一周内新闻中所有出镜者的整体情绪倾向?虽然基于AI技术的人脸情绪评估仍是一个年轻且正在快速发展的研究领域,但通过本次利用谷歌云AI对互联网档案馆内电视新闻归档中的一周电视新闻报道进行分析,我们发现即使是单纯利用现有工具方案,也足以从新闻内容当中提出出大量可见情绪元素。

为了更好地理解电视内容,我们选择对CNN、MSNBC以及福克斯新闻网以及来自旧金山的其它媒体分支机构——KGO(ABC)、KPIX(CBS)、KNTV(NBC)以及KQED(PBS)——的早晚播出新闻内容进行情绪识别,具体时段为今年4月15日至4月22日。作为分析对象的电视新闻总时长为812小时。我们选择利用谷歌的Vision AI图像理解API进行分析,并启用了其中的所有功能,包括人脸检测。
人脸检测与人脸识别存在着很大差异。前者只计算图像当中存在的人脸,而并不会尝试分辨此人究竟是谁。总体来讲,谷歌的可视化API仅提供人脸检测功能,而并不提供人脸识别功能。
以谷歌API为例,对于每一张脸,它还会估计其正在表达的以下四种情绪的各自可能性,包括喜悦、惊讶、悲伤与愤怒。
为了探索电视新闻中的面部情绪世界,我们将总长812小时的电视新闻转换为1 fps预览图像序列,并通过Vision AI API加以运行,总计得出1261万2428脸-秒(即总帧数乘以各帧当中能够检测出的清晰人脸数量)。
其中,3.25%展现出喜悦的情绪,0.58%表现出惊讶,0.03%表现出悲伤,0.004%表现出愤怒。
可以看出,谷歌的Vision AI API在处理在线新闻图像时,认为喜悦与惊讶情绪的出现比例要远远高于愤怒与悲伤我们还无法确定这究竟只是一种整体性的分析错误,还是新闻图像中确实存在这样的基本情绪表达趋势,或者说谷歌的算法对于喜悦与惊讶这两种情绪的识别能力更强。无论如何,即使谷歌算法确实对于某些特定情绪拥有着更高的敏感度,但这种倾向对各家新闻站点而言仍然是公平的,因此我们可以直接对七大站点中的四种面部情绪表达做出比较。
下图所示为这一周时间之内七个新闻站点当中全部人脸图像呈现出四种情绪中任意一种的各自占比。其中ABC、CBS与NBC似乎面部情感表达最为活跃,其次是福克斯新闻网、MSNBC与CNN,最后是PBS与CNN。
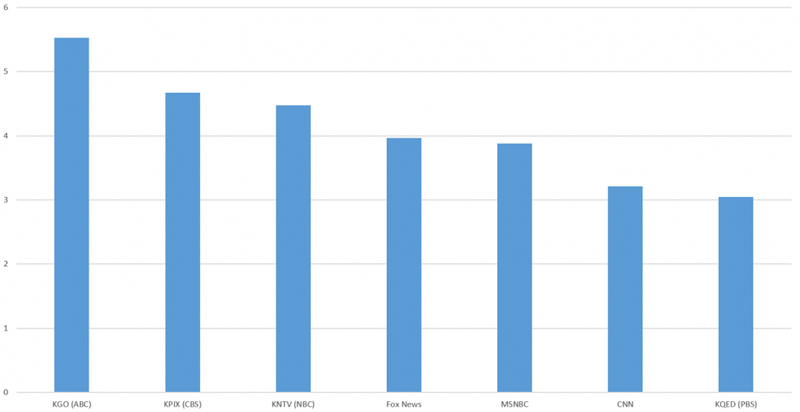
由谷歌的Vision AI API分析得出,清晰的人脸图像在2019年4月15日至4月22日期间表达喜悦、惊讶、悲伤或愤怒情绪的百分比。
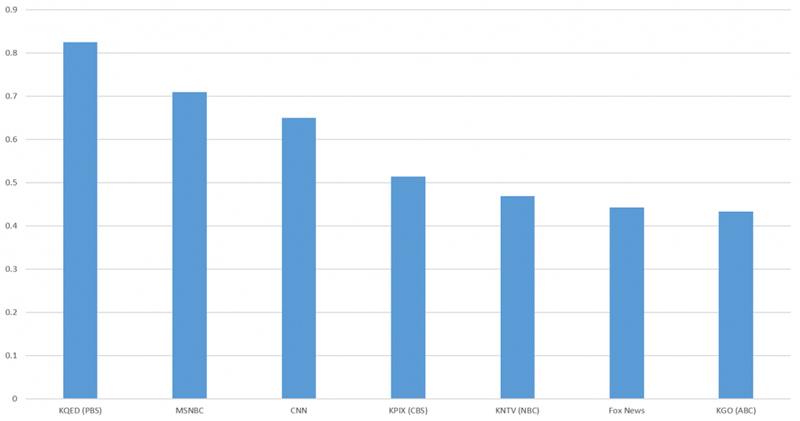
在这份排名当中,喜悦情绪占据的比例最高,具体如下图所示。

由谷歌的Vision AI API分析得出,清晰的人脸图像在2019年4月15日至4月22日期间表达“喜悦”情绪的百分比。
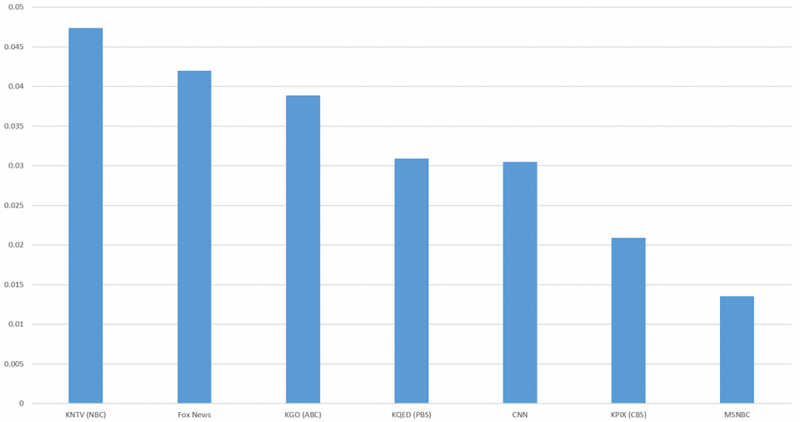
下面来看关于惊讶的情绪,其排名在不同电视站点上出现了全面倒转。PBS的惊讶情绪密度最高,CBS居中,ABC落在最后。
但考虑到这四种情绪之间并非完全隔离,因此ABC的喜悦情绪密度更高,并不代表着其惊讶识别率就一定更低。
由谷歌的Vision AI API分析得出,清晰的人脸图像在2019年4月15日至4月22日期间表达“惊讶”情绪的百分比。
悲伤是一种相对不太常见的情绪,但在各站点之间仍然存在着明确的分层。其中NBC中包含的悲伤情绪比MSNBC多了三倍半。
由谷歌的Vision AI API分析得出,清晰的人脸图像在2019年4月15日至4月22日期间表达“悲伤”情绪的百分比。
最后是愤怒,这种强烈的情绪在各家新闻站点当中的出现机率最低。尽管如此,其仍然表现出明确的分层趋势。福克斯新闻网当中的愤怒情绪比位列第二的PBS多出1.5们中,而且几乎达到比例最低的NBC的十倍。
事实上,福克斯新闻网中出现的愤怒面孔比MSNBC和CNN加起来还多。

由谷歌的Vision AI API分析得出,清晰的人脸图像在2019年4月15日至4月22日期间表达“愤怒”情绪的百分比。
最重要的是,AI对于人脸面部表情这类复杂且存在细微差别的事物进行判断的能力,目前尚处于早期发展阶段,而且仍是一大非常活跃的研究领域。因此,这里公布的结果恐怕无法被视为对各个新闻站点主流情绪表达的确定性结论。相反,我们可以将其看成是深度学习技术在帮助我们立足更深层次进行维度探索的初步尝试。
综上所述,深度学习开辟了我们理解视觉世界的新领域。立足大规模电视新闻中的对象与活动进行编目,我们终于开始对原本根本无法想象的新维度进行评估——例如本次案例中的面部表情。
最后,正如当下文本情感分析已经变得司空见惯一样,相信终有一天,视觉情感分析也将得到新兴的高级视觉深度学习算法的支持,从而为我们带来前所未有的宏观解读能力。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站


Queen's大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官
Queen's大学研究团队提出结构化智能体软件工程框架SASE,重新定义人机协作模式。该框架将程序员角色从代码编写者转变为AI团队指挥者,建立双向咨询机制和标准化文档系统,解决AI编程中的质量控制难题,为软件工程向智能化协作时代转型提供系统性解决方案。

医疗AI的"显微镜革命":西北工业大学团队发布首个超声影像专用智能助手EchoVLM
西北工业大学与中山大学合作开发了首个超声专用AI视觉语言模型EchoVLM,通过收集15家医院20万病例和147万超声图像,采用专家混合架构,实现了比通用AI模型准确率提升10分以上的突破。该系统能自动生成超声报告、进行诊断分析和回答专业问题,为医生提供智能辅助,推动医疗AI向专业化发展。

上海AI实验室突破自回归图像生成瓶颈:ST-AR让AI"先理解再创造"
上海AI实验室团队发现自回归图像生成模型存在局部依赖、语义不一致和空间不变性缺失三大问题,提出ST-AR训练方法。该方法通过掩码注意力、跨步骤对比学习和跨视角对比学习,让AI"先理解再生成"。实验显示,ST-AR将LlamaGen模型的图像理解准确率提升一倍以上,图像生成质量提升42-49%,为构建更智能的多模态AI系统开辟新路径。

数据中心的智算挑战,英特尔要如何应对?

Queen's大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官

医疗AI的"显微镜革命":西北工业大学团队发布首个超声影像专用智能助手EchoVLM

上海AI实验室突破自回归图像生成瓶颈:ST-AR让AI"先理解再创造"
