 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
人工智能将“吞噬”数据
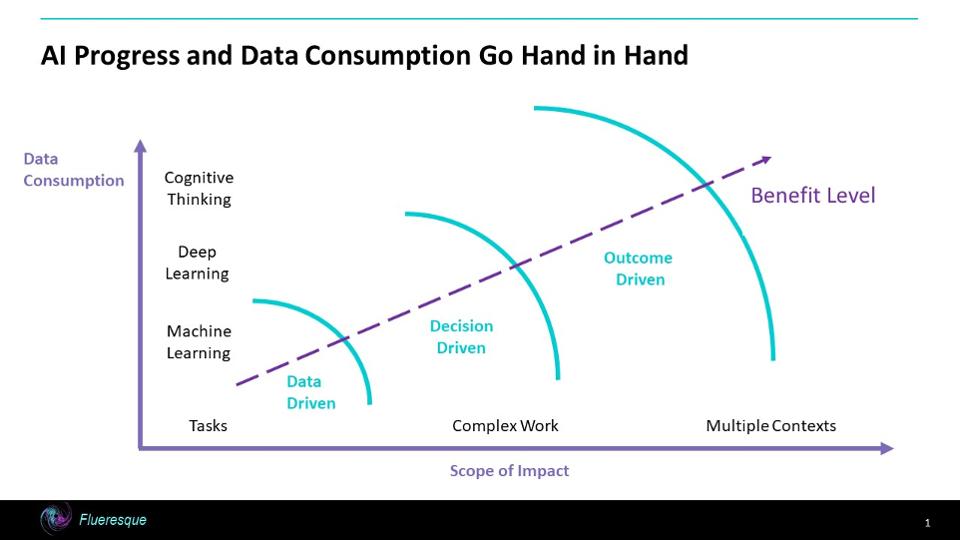
那些从事机器学习(ML)项目的人都知道机器学习需要大量数据来训练算法。有的人会说数据永远不嫌多。数据量和生成的机器学习模型的复杂程度之间通常存在着正相关性。随着人工智能向着新的领域发展,用到的人工智能功能变得愈加复杂,这种对数据的饥渴只会变得更加强烈。除了人工智能的复杂性,其他一些趋势也在加剧这一问题,因此组织面前就出现了这样一个问题:“他们是否拥有适当的数据以成功推动人工智能项目?”如果他们没有足够的资源,他们是否应该为人工智能盛宴做更多的准备?
图1:人工智能/数据连续性
组织已经收集的所有大数据不太可能都是正确的数据,但是了解人工智能的发展方向能够让组织获得“立足点”,在未来几十年人工智能的发展过程中筛选和收集更多正确的数据。
人工智能的发展改变了数据游戏
这又导致对数据的更多需求,在某些情况下,从本质上而言,这些需求可能是迫切或者实时的。
从数据驱动到结果驱动的转变
这只是推动数据使用量需求的源动力之一。
不断变化的问题范围影响数据需求
这些场景中的每一个都可能以不同的速率变化和变形,因此,也就会需要更多的数据。
总结
它将改变或拓展数据管理策略、方法和技术。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站


Queen's大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官
Queen's大学研究团队提出结构化智能体软件工程框架SASE,重新定义人机协作模式。该框架将程序员角色从代码编写者转变为AI团队指挥者,建立双向咨询机制和标准化文档系统,解决AI编程中的质量控制难题,为软件工程向智能化协作时代转型提供系统性解决方案。

医疗AI的"显微镜革命":西北工业大学团队发布首个超声影像专用智能助手EchoVLM
西北工业大学与中山大学合作开发了首个超声专用AI视觉语言模型EchoVLM,通过收集15家医院20万病例和147万超声图像,采用专家混合架构,实现了比通用AI模型准确率提升10分以上的突破。该系统能自动生成超声报告、进行诊断分析和回答专业问题,为医生提供智能辅助,推动医疗AI向专业化发展。

上海AI实验室突破自回归图像生成瓶颈:ST-AR让AI"先理解再创造"
上海AI实验室团队发现自回归图像生成模型存在局部依赖、语义不一致和空间不变性缺失三大问题,提出ST-AR训练方法。该方法通过掩码注意力、跨步骤对比学习和跨视角对比学习,让AI"先理解再生成"。实验显示,ST-AR将LlamaGen模型的图像理解准确率提升一倍以上,图像生成质量提升42-49%,为构建更智能的多模态AI系统开辟新路径。

数据中心的智算挑战,英特尔要如何应对?

Queen's大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官

医疗AI的"显微镜革命":西北工业大学团队发布首个超声影像专用智能助手EchoVLM

上海AI实验室突破自回归图像生成瓶颈:ST-AR让AI"先理解再创造"
