 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
IBM的AutoAI让数据科学家更高效,但可怕的是它变得太智能了

和数据科学。
“自动化对人工智能和机器学习生命周期的影响”这个话题很感兴趣,并与Amini博士集中讨论了AutoAI的下一代功能。
AutoAI自动执行高度复杂的任务,为数据寻找并优化最好的机器学习模型、特征和模型超参数。AutoAI完成了原本需要专业数据科学家团队和其他专业资源才能完成的工作,且速度要快得多。

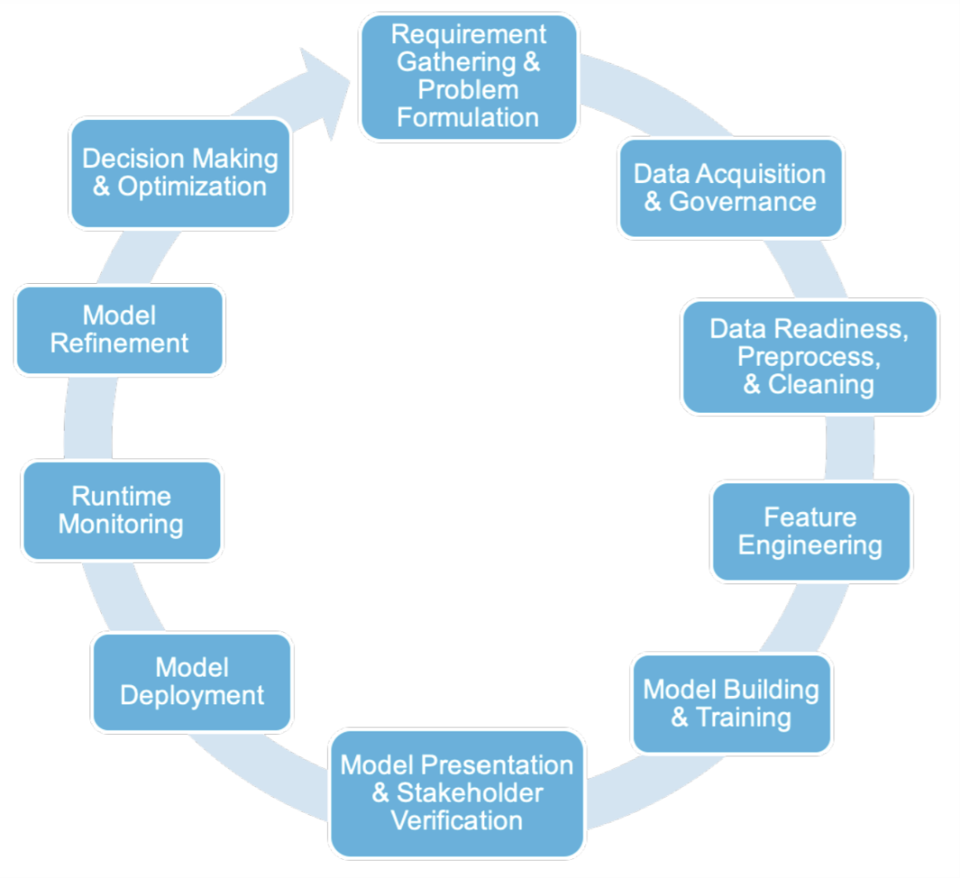
图:“数据科学家想要多自动化?”(图片来源/IBM)
在模型训练开始之前,必须获取、评估数据,并对其进行预处理,以识别并纠正数据质量问题。
它需要一个训练有素的资源团队,他们要了解数据科学,还要有了解模型目的和输出的主题专家。
理和建模阶段进行无数次优化调整。
管道的高度复杂性使其成为自动化的首要对象。
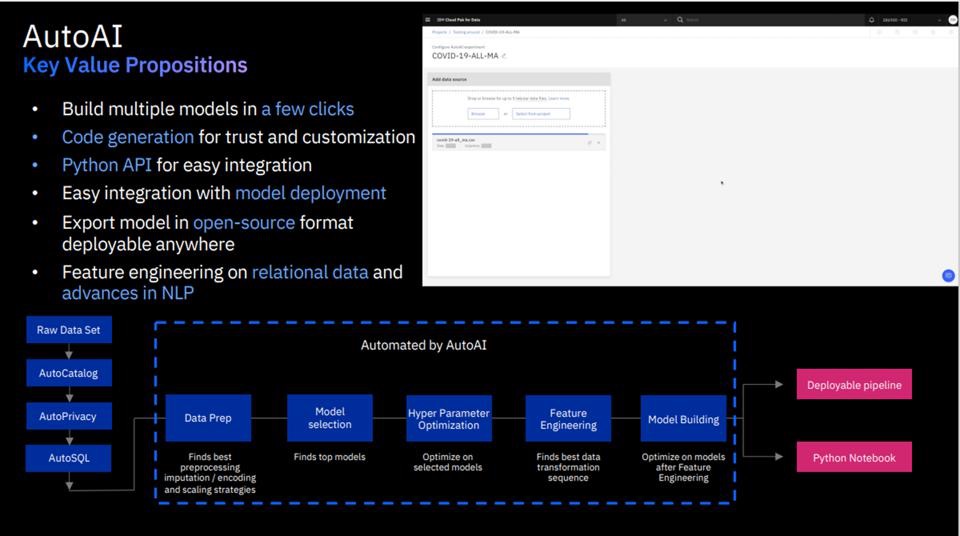
自动化功能包括数据准备、模型开发、特征工程和超参数优化。
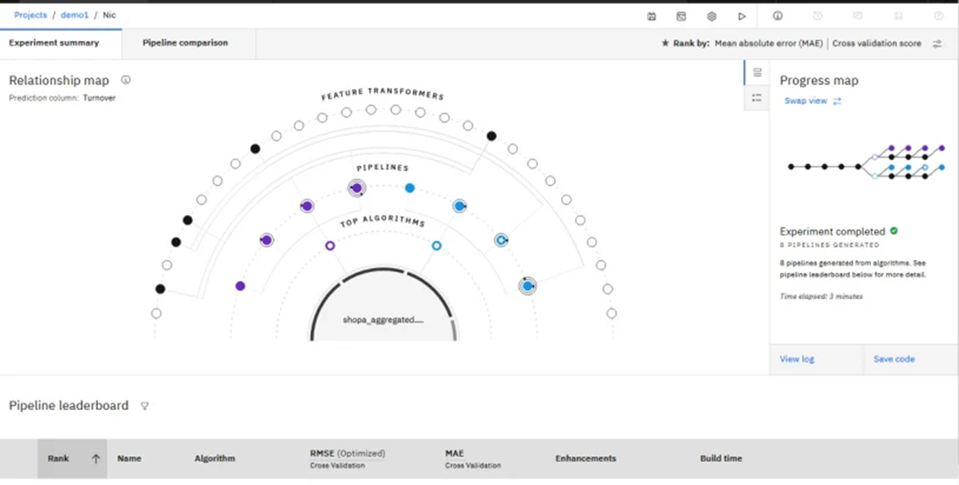
图片来源/IBM
以下是AutoAI的部分功能列表:
-
自动分析数据,并针对预测建模问题自动生成个性化的模型管道。
-
、算法和参数设置时迭代创建的。
-
结果显示在排行榜上,并根据问题优化目标,对自动生成的模型管道进行排名。
-
从数据准备,到算法选择,再到模型创建,流程的每个阶段都提供可视化。
-
用户只需单击鼠标,即可轻松部署模型,或为任何管道生成Python notebook。
-
用于持续模型改进的自动化任务,可以在需要时,将AI模型API集成到应用程序中。
只需点击几下鼠标,即使是只有基本数据科学技能的人,也可以使用自定义数据自动选择、训练并调优高性能机器学习模型。
无需从头开始编写管道代码。
未来的人工智能自动化项目
IBM Research正在开展多个下一代人工智能自动化项目,例如处理新数据类型的下一代算法,实现新的自动化质量和公平性,并显著提高规模和性能。
AutoAI for Decisions和Semantic Data Science。
用于改进决策的AutoAI
数据集的时间维度使分析变得困难并且需要更高级的数据处理。

-
为训练准备数据集
-
根据数据类型确定需要哪种模型,例如分类还是回归
-
将适当的插补转换器置入管道中以处理丢失的数据
-
通过确定哪些数据列能够最好地支持问题来进行特征选择
-
测试各种超参数调整选项以获得最佳结果
-
根据准确性和精确度等因素生成管道并对其排名。
Amini博士解释说,在许多环境中,创建时间序列预测之后,下一步是利用预测来改进决策。
例如,数据科学家可能会建立一个“时间序列预测模型”预测产品需求,但是该模型也可以作为库存补货决策的输入,通过减少成本、高昂的大量库存积压、或者避免由于库存告罄造成的销售损失,实现利润最大化。
在另一些情况下,我们会用被称为“决策优化”的更系统性方法来构建规范性模型,以补充时间序列预测模型。
然而,像AutoAI生成预测模型那样直接根据数据自动化生成决策优化管道的产品,目前还不存在。
多模型管道
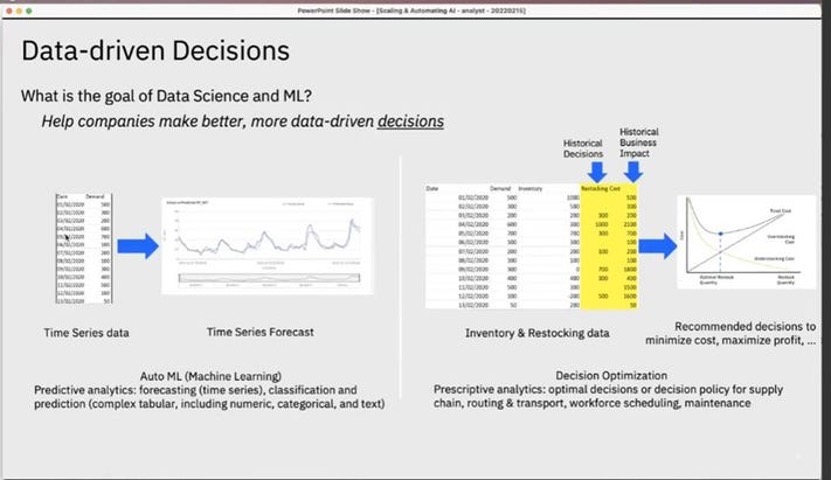
这样的产品同样需要资源协作。
深度强化学习自动化
因此,它们需要大量的专业知识和手动工作对它们进行调整,以适应特定的问题和数据集。
它还可以使用高级搜索策略,为模型选择最佳的超参数配置。
该系统支持各种类型的强化学习,包括在线和离线学习以及无模型和基于模型的算法。
自动扩展人工智能
强化学习自动化解决了在企业中扩展人工智能的两个紧迫问题。
首先,它为顺序决策问题提供了自动化,在这类问题中,不确定性可能会削弱启发式甚至是不使用历史数据的正规优化模型。
其次,它为具有挑战性的强化学习模型构建领域带来了一种自动化、系统化的方法。
Semantic Data Science(语义数据科学)
自动化方法目前依靠统计技术来探索特征空间。
例如,如果数据是关于汽车的,则特征空间可能是福特、特斯拉、宝马。
尽管如此,要知道哪些特征和转换是相关的,用户必须具备足够的技术技能来破译和翻译代码和文档。
数据科学家的新语义能力
一旦AutoAI检测到正确的语义概念,程序就会使用这些概念广泛搜索现有代码、数据和文献中可能存在的相关特征和特征工程操作。
AutoAI可以使用这些新的、语义丰富的特征来提高生成模型的准确性,并通过这些生成的特征提供可供人类阅读的解释。

但是,想要理解发现的语义概念,可以使用Semantic Feature Discovery(语义特征发现)可视化资源管理器来探索发现的关系。
用户只需单击Sources超链接,即可直接从可视化资源管理器进入新功能生成的Python代码或文档,如下图所示。
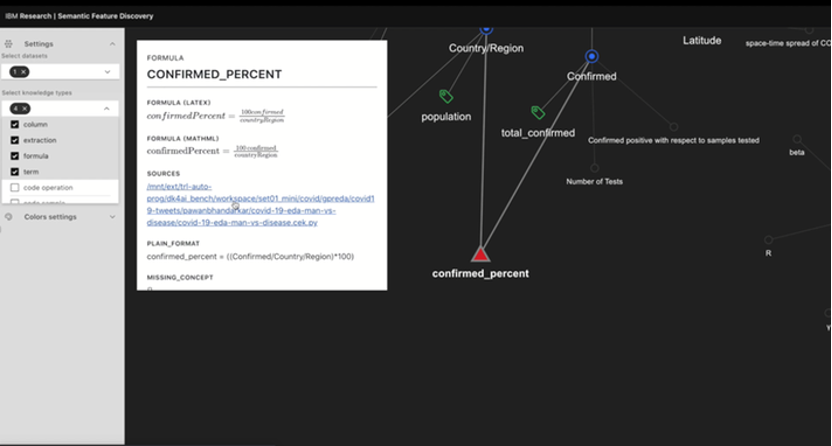
甚至可以在IBM的API Hub上试用其中一些功能。
Amini博士用一句话总结了IBM对AutoAI投入的大量研究工作,并以此结束了我们的谈话:
”
要点总结
- 使用AutoAI可以快速大规模地生成模型。
- 它还将增加部署并投入运营的企业模型的数量。
- AutoAI for Decisions将自动生成管道可以解决的问题类型,扩展到需要在不确定性和强化学习下进行决策优化的问题。
- 它将充当专家资源广泛收集并整合难以找到的、各种类型和来源的信息,从而提高在建模型的质量。
- AutoAI是IBM Watson Studio的一部分。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

openGauss熊伟:oGRAC+超节点,AI数据库的下一个五年
openGauss的目标是探索oGRAC和超节点深度融合的可能,打造超节点原生数据库。

清华团队让机器学会"透视眼":用视频AI破解透明物体深度估计难题
清华团队开发DKT模型,利用视频扩散AI技术成功解决透明物体深度估计难题。该研究创建了首个透明物体视频数据集TransPhy3D,通过改造预训练视频生成模型,实现了准确的透明物体深度和法向量估计。在机器人抓取实验中,DKT将成功率提升至73%,为智能系统处理复杂视觉场景开辟新路径。

ByteDance推出全新混合专家模型训练法:让AI专家团队各司其职,大幅提升大语言模型性能
字节跳动研究团队提出了专家-路由器耦合损失方法,解决混合专家模型中路由器无法准确理解专家能力的问题。该方法通过让每个专家对其代表性任务产生最强响应,同时确保代表性任务在对应专家处获得最佳处理,建立了专家与路由器的紧密联系。实验表明该方法显著提升了从30亿到150亿参数模型的性能,训练开销仅增加0.2%-0.8%,为混合专家模型优化提供了高效实用的解决方案。

上海AI实验室创造"无限视频世界",用键盘就能探索!
上海AI实验室团队开发的Yume1.5是一个革命性的AI视频生成系统,能够从单张图片或文字描述创造无限可探索的虚拟世界。用户可通过键盘控制实时探索,系统8秒内完成生成,响应精度达0.836,远超现有技术。该系统采用创新的时空通道建模和自强制蒸馏技术,支持文本控制的事件生成,为虚拟现实和内容创作领域开辟了新的可能性。

openGauss熊伟:oGRAC+超节点,AI数据库的下一个五年

清华团队让机器学会"透视眼":用视频AI破解透明物体深度估计难题

ByteDance推出全新混合专家模型训练法:让AI专家团队各司其职,大幅提升大语言模型性能

上海AI实验室创造"无限视频世界",用键盘就能探索!

海外来电
科技行者编辑部
