 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
大模型应用开发,CPU如何发光发热?

2025年,具备深度思考能力的DeepSeek的问世,让大模型在商业落地过程中,有了处理复杂任务的能力。
然而,面对大模型技术的日新月异,当越来越多开发者、开发团队着手基于大模型开发应用,乃至AI智能体时,如何用较低成本、开发出符合这个时代的AI智能体,就成了当下大多数开发者不得不面对的问题。
也是在这样的背景下,基于英特尔至强6性能核的火山引擎第四代计算实例g4il提出了“一杯咖啡的成本,在云上构建专属大模型知识库”,似是有意解决这一问题。
近日,我们与英特尔技术专家进行了一次技术交流。
据英特尔技术专家透露,“英特尔已经基于火山引擎第四代计算实例g4il进行了一系列测试,我们现在已经能够做到在一个云实例里,仅使用CPU就可以运行14B的大模型,这个门槛最低可以降到16vCPU或32vCPU,16vCPU在火山引擎官网的定价仅约3.8元/小时。”
这让基于云计算的大模型应用开发颇具诱惑力,也为大模型步入真正具备落地能力的Agentic AI时代奠定了基础。

01 DeepSeek带来的高效开发启示
年初DeepSeek的出现,不仅在各项能力上持续刷新业界对大模型潜能的认知上限,更以其独特的“深度思考”能力,为大模型应用开发带来了新思路。
DeepSeek的显著特性之一是其高效的“蒸馏”技术。
通过这种技术,即使是参数量相对较小(如7B或14B参数)的大模型,也能够展现出媲美甚至超越许多先前大模型的推理能力,这一点在DeepSeek-R1模型上得到了充分体现。
这种“小模型撬动大智慧”的特性,使得DeepSeek在学习和开发阶段具有极高的性价比,为更广泛的开发者和研究者提供了接触和使用先进AI技术的机会。
面对大模型技术的飞速迭代,许多开发者和企业都感受到了前所未有的机遇与挑战。
英特尔技术专家指出,“面对这股不可逆转的趋势,与其在大模型本身研发上进行‘内卷’,不如将目光投向大模型应用开发这一更广阔的赛道。”

因为大模型本身往往需要与具体的应用场景相结合,才能真正落地并发挥其价值。
投身大模型应用开发,不仅是缓解技术焦虑的有效途径,更是提升自身价值、抓住时代机遇的关键一步。
然而,对于普通开发者而言,进入大模型应用开发领域并非易事,RAG、MCP、A2A等技术名词层出不穷,技术栈的演进速度也令人眼花缭乱,许多人因此望而却步。
一方面认为门槛过高,另一方面则苦于不知从何处入手,这种困境是当前AI普惠化过程中亟待解决的现实问题。
DeepSeek的成功也为模型架构的创新提供了启示。
DeepSeek采用的MoE混合专家架构虽然并非首创,但却有力地验证了该架构的有效性。
MoE架构的特点在于,虽然模型总参数量可能大幅增加,但实际在推理过程中被激活的“有效参数”数量相对较少,这种机制使得模型能够在不显著增加算力需求的前提下,提升了性能和容量,实现了对计算资源的更高效利用。
英特尔技术专家特别指出,更值得关注的是DeepSeek所展现的“深度思考”能力,这意味着模型在处理复杂任务时,不再仅仅是简单地根据输入生成输出,而是在内部经历“规划”和“思考”阶段,然后再给出结果。
这种机制显著提升了模型在复杂问题解决和逻辑推理能力,也为接下来大模型的应用普及奠定了基础。
然而,如何解决大模型在开发、测试、验证过程中的算力开销,降低大模型应用的开发成本,依然是开发者不得不三思的问题。
前不久,火山引擎云基础团队官方表示,基于英特尔至强6性能核的火山引擎第四代计算实例g4il,已经可以实现“一杯咖啡的成本,在云上构建专属大模型知识库”。
这为大模型应用开发者们带来了一个低成本选项。
02 异构计算趋势下,CPU如何发光发热?
同样是做AI推理,如何比较CPU和GPU的性能差异?
这是大模型应用开发者面临的一个问题,也是英特尔这样的算力供应商需要考虑的问题。
英特尔技术专家指出,“本质上CPU可以理解为一把‘瑞士军刀’,是一个通用型计算设备,能够执行多种任务,我们也对英特尔至强6性能核的AI推理进行了加强,使其相比其他CPU有了专门做矩阵运算的AI加速器,GPU则更像一个专注于并行计算和AI加速的‘专家工具’。”
不过,英特尔技术专家也指出,“当前业界的普遍趋势是采用异构计算方案,即根据任务特性,让CPU和GPU协同工作,各展所长。”
CPU的优势在于其低成本、易获得性,以及能够满足多数场景下的基本AI推理需求,特别是在GPU资源有限或不易获取,或者仅需进行小规模模型推理及特定AI场景应用时。

即便在GPU资源充足的情况下,CPU依然可以与GPU协同工作,承担数据预处理、任务调度、部分轻量级模型推理等任务,而非简单的替代关系。
CPU与GPU协同的异构计算方案,实际上已经是当下技术发展的主流方向。
大模型应用的生命周期通常包括开发、验证和大规模生产部署三个阶段,在对算力性能要求相对较低的开发和验证阶段,CPU的低成本和易获得性使其成为理想的选择。
正因如此,基于英特尔至强6性能核的火山引擎第四代计算实例g4il意在充分发挥CPU的这些优势,火山引擎联合因特尔共同打造了面向大模型应用的开发环境,并整合了丰富的应用镜像,将其包装成一个完整的解决方案,旨在降低开发者入门的门槛。
英特尔技术专家指出,进行大模型应用开发需要具备三大要素:
用于验证和练习的硬件环境,主流软件栈的兼容支持,以及一个好老师。
为了帮助开发者跨越这“第一步”,英特尔与火山引擎致基于g4il实例就三大要素进行了如下布局:
硬件环境方面,火山引擎g4il实例搭载了先进的英特尔至强6处理器,内置AMX AI加速器,通过AMX的硬件加速能力,用户在配置更低、更经济的虚拟机上也能获得流畅的大模型应用体验。
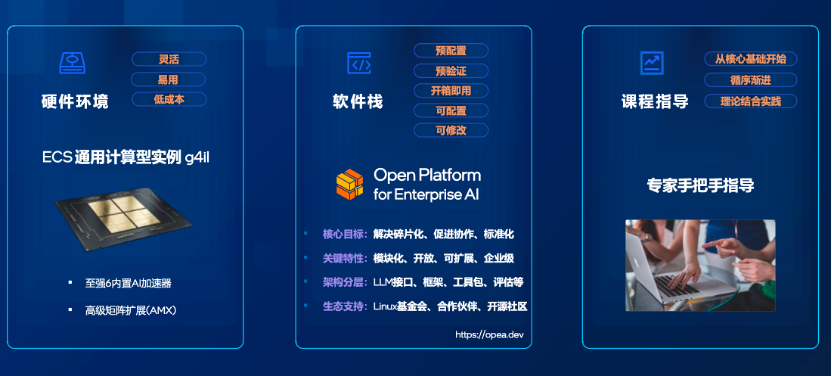
例如,针对DeepSeek的7B、14B参数的小尺寸模型,通过软硬件协同优化,可以在不依赖GPU的情况下,仅使用CPU(如16vCPU或32vCPU的g4il实例)即可实现每秒7个token以上的流畅输出速度。
据悉,基于英特尔至强6性能核的g4il实例已经正式发售。
在火山引擎官网上,一个16vCPU的g4il实例定价约为每小时3.8元,极大地降低了开发者的硬件成本。

软件栈方面,英特尔发起的OPEA开源社区致力于利用开放架构和组件化、模块化的思想,旨在为企业打造可扩展的AI应用部署基础。
OPEA社区积累了大量经过预先验证和优化的开源应用范例,可供用户参考。
英特尔与火山引擎将这些范例和必要的软件栈打包成虚拟机镜像,用户在火山引擎控制台选择g4il实例后,可以直接选用预置的知识库问答等AI应用镜像,实现一键部署。
据英特尔技术专家透露,“通过一键部署,原本可能需要数天才能完成的环境搭建过程,如今可以缩短至3分钟左右。”
课程指导方面,英特尔准备了丰富的演示课程和技术文档,内容涵盖从基础环境搭建、代码开发环境配置,到模型调优、性能优化等各个环节。
这些课程旨在帮助基础相对薄弱的用户补齐知识短板,理解技术原理,掌握实际操作技能,从而真正实现能力的进阶。
据悉,这些课程在英特尔官网上免费开放给所有用户。
正是基于这三大要素的构建,火山引擎云基础团队有了提出“一杯咖啡的成本,在云上构建专属大模型知识库”的底气,也为开发者提供了一条云上新路径,一条高效通向Agentic AI的路径。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

openGauss熊伟:oGRAC+超节点,AI数据库的下一个五年
openGauss的目标是探索oGRAC和超节点深度融合的可能,打造超节点原生数据库。

清华团队让机器学会"透视眼":用视频AI破解透明物体深度估计难题
清华团队开发DKT模型,利用视频扩散AI技术成功解决透明物体深度估计难题。该研究创建了首个透明物体视频数据集TransPhy3D,通过改造预训练视频生成模型,实现了准确的透明物体深度和法向量估计。在机器人抓取实验中,DKT将成功率提升至73%,为智能系统处理复杂视觉场景开辟新路径。

ByteDance推出全新混合专家模型训练法:让AI专家团队各司其职,大幅提升大语言模型性能
字节跳动研究团队提出了专家-路由器耦合损失方法,解决混合专家模型中路由器无法准确理解专家能力的问题。该方法通过让每个专家对其代表性任务产生最强响应,同时确保代表性任务在对应专家处获得最佳处理,建立了专家与路由器的紧密联系。实验表明该方法显著提升了从30亿到150亿参数模型的性能,训练开销仅增加0.2%-0.8%,为混合专家模型优化提供了高效实用的解决方案。

上海AI实验室创造"无限视频世界",用键盘就能探索!
上海AI实验室团队开发的Yume1.5是一个革命性的AI视频生成系统,能够从单张图片或文字描述创造无限可探索的虚拟世界。用户可通过键盘控制实时探索,系统8秒内完成生成,响应精度达0.836,远超现有技术。该系统采用创新的时空通道建模和自强制蒸馏技术,支持文本控制的事件生成,为虚拟现实和内容创作领域开辟了新的可能性。

openGauss熊伟:oGRAC+超节点,AI数据库的下一个五年

清华团队让机器学会"透视眼":用视频AI破解透明物体深度估计难题

ByteDance推出全新混合专家模型训练法:让AI专家团队各司其职,大幅提升大语言模型性能

上海AI实验室创造"无限视频世界",用键盘就能探索!

金旺
主编
