 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
从对抗到协同:一种结合逻辑和采样的全新大语言模型水印框架
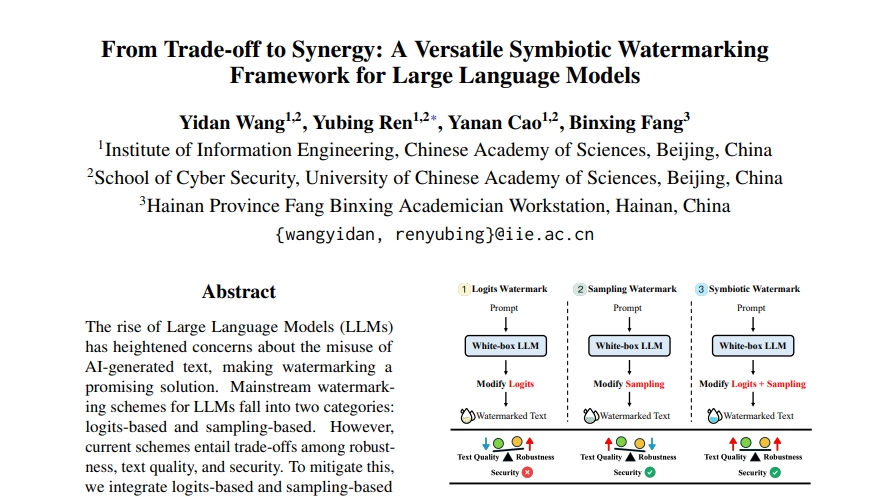
最近,来自中国科学院信息工程研究所的王一丹、任煜兵、曹亚男和方滨兴院士提出了一种创新的大语言模型水印框架,将传统的水印技术从"权衡取舍"提升到了"协同增效"的新境界。这项研究以《从权衡到协同:大型语言模型的多功能共生水印框架》(From Trade-off to Synergy: A Versatile Symbiotic Watermarking Framework for Large Language Models)为题,发表于2025年5月的arXiv预印本平台,论文链接为:https://github.com/redwyd/SymMark。
随着大语言模型(LLMs)如LLaMA和OPT系列的迅猛发展,它们在创意内容生成和自动写作等领域的应用越来越广泛。这些技术的普及大大降低了AI生成内容的使用门槛,带来了显著好处的同时,也引发了一系列挑战,包括LLM可能被滥用于生成恶意内容、侵犯知识产权以及传播虚假信息。为应对这些风险,水印技术成为了一种有前途的解决方案,可以确保LLM生成内容的可追溯性、真实性和责任归属。
目前主流的LLM水印方案分为两大类:基于逻辑的和基于采样的。基于逻辑的水印(如KGW家族)会修改模型输出的逻辑值,引导模型更倾向于生成特定的"绿色"标记,这种方式检测效果好但容易降低文本质量。而基于采样的水印(如AAR)则通过改变采样过程嵌入水印,保持了更好的文本质量但检测效果和安全性可能较弱。可以把这想象成烹饪中的两种调味方法:一种改变原料本身(逻辑),一种改变烹饪手法(采样)。
研究团队敏锐地发现,现有的水印方法都面临着鲁棒性、文本质量和安全性之间的根本性权衡,就像一个永远只能选择两个的三角难题。他们提出了一个大胆的问题:我们能否让鲁棒性、文本质量和安全性协同工作,而不是相互冲突?
受自然生态系统中共生关系的启发,研究团队提出了名为"SymMark"的多功能共生水印框架,它将传统的权衡取舍转变为协同增效。就像共生生物彼此获益一样,SymMark结合了基于逻辑和基于采样的水印方法各自的优势,提供了一种即使在对抗条件下也能确保鲁棒性、文本质量和安全性的创新解决方案。
一、SymMark的三种协同策略
基于这种共生视角,SymMark探索了三种整合基于逻辑和基于采样水印的策略。
首先是串行共生水印(Series)。这种方法在每个生成的标记中都嵌入两种水印,确保极高的可检测性。想象一下,这就像在一块饼干上同时加入两种不同的特殊香料,无论从哪个角度检测都能辨别出来。然而,过于强烈的双重水印可能会降低文本质量,就像过度调味会影响食物原本的风味。
其次是并行共生水印(Parallel)。这种方法在标记级别交替使用两种方法,在奇数位置使用基于逻辑的水印,在偶数位置使用基于采样的水印。这样做能够平衡鲁棒性和文本质量,就像在烹饪中交替使用两种烹饪技巧,既保留了食物的原味,又增添了特殊的风味。不过,这种方法缺乏灵活性,无法为每个标记自适应地选择最佳水印策略。
为了解决这些问题,研究团队提出了第三种也是主要的配置:混合共生水印(Hybrid)。这种方法应用两种水印方法的非线性组合,根据标记的上下文自适应地选择最合适的策略。这可能涉及同时应用两种水印、仅应用一种,或完全跳过水印,取决于标记的特性。通过基于标记熵和语义熵动态选择最佳策略,Hybrid增强了水印的安全性、韧性和流畅性。
二、基于熵的自适应水印决策
在Hybrid方法中,两个关键的熵指标驱动了水印策略的动态决策:标记熵和语义熵。
标记熵源自香农熵,衡量当前时间步骤中标记逻辑分布的不确定性。简单来说,它反映了模型在生成特定标记时的信心程度。想象一下,当你在玩"猜下一个词"的游戏时,有些情境下几乎只有一个合理的词(低熵),而在其他情境下可能有多个合理选择(高熵)。
当标记熵较高时,模型展现出更大的不确定性,逻辑分布中有多个竞争的候选项。由于标记选择本身就不稳定,修改逻辑对文本质量的干扰最小,同时确保有效的水印嵌入。这就像在一道多种配料都可行的食谱中改变一种配料,不会显著影响最终的味道。
语义熵则衡量当前时间步中前k个候选标记在语义含义上的多样性。研究团队使用K-means聚类算法将top-k标记的嵌入分为n组,然后计算这些语义群组的熵。
当语义熵较低时,意味着顶级候选标记具有相似的语义含义,用一个替换另一个对文本解释的影响很小。此时添加采样水印不太可能改变生成内容的语义,就像在同一个蔬菜家族中替换一种蔬菜不会根本性地改变菜肴的风味。而当语义熵较高时,顶级候选标记在语义上差异明显,改变采样过程可能会扰乱句子的预期含义,此时不适合使用采样水印。
这种基于双重熵的自适应方法使Hybrid策略能够在保持高检测率的同时尽可能地保证文本质量和语义保真度。
三、统一的检测算法
研究团队还提出了一种统一算法,能够有效、高效地检测所有三种策略。这种检测方法利用了一个简单但强大的原则:如果检测到任何水印信号(无论是基于逻辑还是基于采样的),则认为文本包含水印。这种方法之所以有效,是因为水印技术通常具有极低的误报率,大大降低了误判的可能性。
四、实验结果分析
研究团队进行了大量实验,在多个数据集和模型上一致表明SymMark优于现有基线方法。
在可检测性方面,Series策略在所有数据集和模型上都实现了完美的真阳性率(TPR)1.000,意味着没有假阴性,这在水印上下文中至关重要。这得益于对每个标记注入双重水印信号,增强了整个序列中水印的存在。然而,这种增强的可检测性以文本质量为代价,因为在逻辑和采样阶段都对标记选择施加了强烈约束。
Parallel策略展示了与基线相比具有竞争力的可检测性能,F1/AUC得分比采样水印平均提高了1.60%/1.35%。尽管每个标记仅被两种水印策略之一(逻辑或采样)修改,但对检测而言,水印信号仍然足够。这表明,双重水印并非检测所必需。
Hybrid策略在各种数据集和基础模型配置上始终优于基线,证明了其卓越的泛化能力。与采样水印相比,Hybrid的F1/AUC性能平均提高了1.90%/1.52%。这种策略根据熵特性自适应地分配水印策略,使得水印放置最优,确保高可检测性的同时保持文本质量。
在文本质量方面,研究团队使用困惑度和下游任务来评估水印对文本质量的影响。Parallel策略的困惑度较低,因为每个标记上的双重水印比单一水印更严重地降低文本质量。而Hybrid策略通过考虑语义熵并自适应地应用特定阶段的水印,有效地管理文本质量并实现了最低的困惑度。
在下游任务测试中,研究发现,生成的答案越长(例如,任务2和任务4),注入水印对下游任务的影响就越小。Hybrid策略在所有任务中都保持高检测率和出色的任务表现。具体来说,在任务1上性能仅下降0.87%,在任务4上仅下降0.96%,展示了最小的失真。相比之下,其他基线方法要么文本质量下降过多,要么可检测性较弱。
在面对真实世界攻击的鲁棒性测试中,Hybrid策略展现出持续稳健的水印检测能力。研究团队测试了编辑、复制-粘贴、回译和改写等四种攻击情境。串行和混合共生水印的平均AUC值分别为0.987和0.984,显著优于此前最稳健的方法Unigram,其AUC为0.951。
Hybrid在鲁棒性方面的卓越表现归功于三方面原因:双信号注入确保即使一个水印信号部分受损,另一个仍保持完整;基于熵的自适应方法确保水印既不易察觉又有弹性;以及跨攻击泛化能力,使其在各种对抗条件下保持高检测率。
在安全性测试方面,研究团队针对Unigram和Hybrid方法应用了水印窃取方法并执行了欺骗攻击。实验结果表明,随着攻击者获取的标记数量增加,攻击成功率和z分数也随之提高。然而,与原始Unigram相比,Hybrid方案的攻击成功率明显更低。当生成200,000个标记时,原始Unigram的攻击成功率达到69%,而共生水印方案仅为18%。
Hybrid方案安全性增强源于其逻辑基础和采样基础水印方法的非线性组合。由于共生水印规则不仅受逻辑影响,还受采样过程中固有随机性的影响,攻击者无法仅通过标记频率统计或分布建模重建水印规则。这使得Hybrid方案在攻击者积极试图破坏水印的对抗环境中大大提高了抵抗水印窃取攻击的能力,提供了增强的安全性。
五、研究意义与未来方向
这项研究的主要贡献在于系统地探索了基于逻辑和基于采样水印方法的集成,开创了它们协同的全面方法;提出了包含三种不同策略的多功能共生水印框架SymMark;以及通过大量实验证明SymMark框架在可检测性、鲁棒性、文本质量和安全性方面达到了最先进(SOTA)的性能。
这一创新框架将传统水印技术从权衡取舍转变为协同增效,为未来的水印技术提供了新的思路。研究人员计划在未来探索更多的共生水印范式,超越熵视角,进一步推进水印技术的发展。
就像任何创新研究一样,这项工作也有其局限性。研究团队承认,本文从熵的角度探索了结合基于逻辑和基于采样的水印,但熵并非唯一的评估指标。未来的研究可以采用其他数学或信息论工具来增强共生水印设计。例如,信息增益和信噪比等指标,与熵一起,可能会对水印性能、鲁棒性和效率提供更深入的见解。
尽管存在局限性,研究团队相信共生水印概念为这一快速发展领域的LLM水印提供了一个新颖的视角和有意义的方向。这种方法不仅是技术上的创新,还为如何保护知识产权、遏制虚假信息和减轻AI生成内容滥用(包括学术欺诈)提供了新思路,有助于增强公众对AI技术的信任。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

谷歌DeepMind等顶级机构联合揭秘:为什么所有AI安全防护都是纸老虎?
谷歌DeepMind等顶级机构联合研究揭示,当前12种主流AI安全防护系统在面对专业自适应攻击时几乎全部失效,成功率超过90%。研究团队通过强化学习、搜索算法和人类红队攻击等多种方法,系统性地突破了包括提示工程、对抗训练、输入过滤和秘密检测在内的各类防护技术,暴露了AI安全评估的根本缺陷。
 2025-11-19 16:15
2025-11-19 16:15西蒙弗雷泽大学和Adobe研究院联手打造视频制作新神器:让静态图片学会"按剧本演戏"
西蒙弗雷泽大学和Adobe研究院联合开发的MultiCOIN技术,能够将两张静态图片转换为高质量的过渡视频。该技术支持轨迹、深度、文本和区域四种控制方式,可单独或组合使用。采用双分支架构和分阶段训练策略,在运动控制精度上比现有技术提升53%以上,为视频制作提供了前所未有的灵活性和精确度。

英国国王学院突破传统:让AI像人类思考一样"反复斟酌",生成速度飞跃10倍
英国国王学院研究团队开发了潜在精炼解码(LRD)技术,解决了AI文本生成中的速度与准确性平衡难题。该方法通过两阶段设计模仿人类思考过程:先让AI在连续空间中"深思熟虑",保持多种可能性的混合状态,然后"果断行动",逐步确定答案。实验显示,LRD在编程和数学推理任务中准确性提升最高6.3个百分点,生成速度提升最高10.6倍,为AI并行文本生成开辟了新路径。

清华大学团队发布ViSurf:让AI视觉模型学习更聪明的新方法
清华大学团队开发的ViSurf是一种创新的大型视觉语言模型训练方法,巧妙融合了督导式学习和强化学习的优势。该方法通过将标准答案整合到强化学习过程中,让AI既能从正确答案中学习又能保持自主推理能力。实验显示ViSurf在多个视觉任务上显著超越传统方法,特别是在处理模型知识盲区时表现突出,同时有效避免了灾难性遗忘问题,为AI训练提供了更高效稳定的新范式。

谷歌DeepMind等顶级机构联合揭秘:为什么所有AI安全防护都是纸老虎?

西蒙弗雷泽大学和Adobe研究院联手打造视频制作新神器:让静态图片学会"按剧本演戏"

英国国王学院突破传统:让AI像人类思考一样"反复斟酌",生成速度飞跃10倍

清华大学团队发布ViSurf:让AI视觉模型学习更聪明的新方法
