 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
LLM推理过程有必要吗?麻省理工和滑铁卢大学研究告诉你:不要过度"深思"排序重排
在人工智能领域,大型语言模型(LLM)的推理能力近年来取得了显著进展,特别是在解决复杂的自然语言任务方面表现出色。这种成功引发了信息检索(IR)领域研究者的兴趣,他们开始探索如何将类似的推理能力整合到基于LLM的文章重排系统中。这项名为《不要过度"深思"段落重排:推理真的必要吗?》(Don't "Overthink" Passage Reranking: Is Reasoning Truly Necessary?)的研究由麻省理工学院林肯实验室的Nour Jedidi、麻省理工学院的Yung-Sung Chuang和James Glass,以及滑铁卢大学的Jimmy Lin共同完成,发表于2025年5月的arXiv预印本平台(arXiv:2505.16886)。
想象一下,当你在网络上搜索信息时,搜索引擎会返回一系列相关结果。在幕后,有一个重要的步骤是"重排"——确定哪些结果最符合你的查询,并将它们排在前面。近期,研究人员开始尝试让AI系统在做这种重排决策前先进行"推理"——就像我们人类会先思考一下问题再做决定。但这种额外的"思考"真的能提高排序质量吗?这就是本研究要解答的问题。
这个问题很重要,因为在AI系统中,推理过程需要额外的计算资源和时间。如果发现推理过程并不能真正提高重排的准确性,那么我们可以构建更高效的系统,节省大量计算资源。研究团队通过设计严谨的实验,比较了带推理和不带推理的重排器在相同训练条件下的表现,结果发现了一些出人意料的发现。
论文的核心问题很简单:在重排任务中,让模型先生成一系列推理步骤(类似"思考")再得出最终判断,是否真的比直接得出判断更有效?为了回答这个问题,研究团队设计了两个研究角度:一是在完全相同的训练环境下,比较带推理和不带推理的重排器;二是看看当我们强制禁用推理重排器的推理能力时,它的效果会如何变化。
一、研究设计:三种不同的重排器
研究团队开发并测试了三种重排器模型:
首先是StandardRR,这是一个标准的基于LLM的逐点重排器(pointwise reranker)。想象一下,这就像是一个快速评价员,它直接判断每对查询-文章是否相关,不需要解释自己的判断理由。它工作方式很简单:看到一个查询和一篇文章,立即给出"相关"或"不相关"的判断。
第二种是ReasonRR,这是对Weller等人(2025)提出的Rank1模型的复现。与StandardRR不同,这个模型就像一个会思考的评价员,它会先生成一系列推理步骤,记录下自己为什么认为文章相关或不相关,然后再给出最终判断。这种方法类似于最近流行的"思维链"(Chain-of-Thought, CoT)技术。
第三种是ReasonRR-NoReason,这是ReasonRR的一个变体,研究者在推理时强制禁用了它的推理过程。想象成这样:虽然这个评价员被训练成先思考再判断,但现在我们强制它跳过思考环节,直接给出判断。具体实现方式是在推理时预先填充一个固定的"我已思考完毕"的文本,这样模型就会跳过实际的推理过程直接输出结论。
为了确保公平比较,所有模型都使用相同的基础LLM架构(Qwen2.5系列,包括1.5B、3B和7B参数规模),并在完全相同的数据集上训练。训练数据来源于MS MARCO数据集,增强了由DeepSeek R1生成的推理链。
二、惊人的发现:推理过程可能反而有害
研究团队在两类数据集上评估了这些模型:源自MS MARCO的数据集(包括TREC DL19至DL23)作为领域内测试,以及推理密集型检索基准BRIGHT作为领域外测试。评估的主要指标是NDCG@10,这是信息检索领域常用的衡量排序质量的指标。
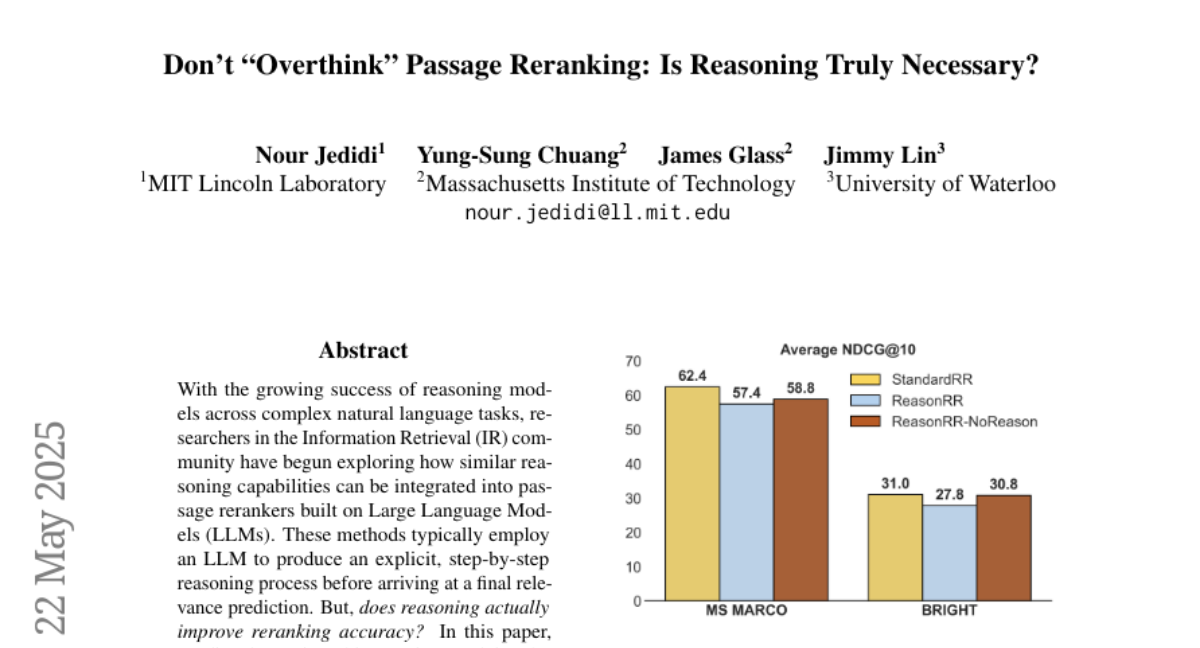
结果令人惊讶。在相同的训练条件下,StandardRR(没有推理过程的重排器)通常表现优于ReasonRR(带推理过程的重排器)。具体来说,在MS MARCO数据集上,StandardRR平均比ReasonRR高出5.3、3.7和5个百分点(分别对应1.5B、3B和7B模型大小)。更令人惊讶的是,在推理密集型的BRIGHT数据集上,StandardRR同样表现更好,平均高出3.4、1和3.2个百分点。
更有趣的是,当研究者强制禁用ReasonRR的推理过程(即ReasonRR-NoReason)时,它的表现反而比原版ReasonRR更好。在MS MARCO上,ReasonRR-NoReason平均比ReasonRR高出0.8、0.5和1.4个百分点;在BRIGHT数据集上,随着模型规模增大,ReasonRR-NoReason的优势越发明显,在7B规模时甚至超过ReasonRR 3个百分点。
这些结果清晰表明:至少对于逐点重排任务,推理过程不仅不是必要的,有时甚至可能是有害的。这与该领域之前的一些直觉是相悖的。
三、为什么推理会伤害重排效果?
既然发现推理过程可能有害,研究团队深入分析了原因。他们假设推理过程可能导致模型产生"极化"的相关性分数,使其难以表达文章与查询之间的"部分相关性"。
想象一下这个场景:两个人在评价餐厅。第一个人直接给出评分:"这家餐厅值7分(满分10分)"。第二个人则先详细分析:"食物很好但服务一般,环境不错但价格偏高...",最后得出结论:"所以,这家餐厅好/不好"。很可能第二个人会倾向于给出更极端的评价(非常好或非常差),因为他已经通过推理得出了一个明确的结论。
研究者通过三种方式验证了这一假设:
首先,他们比较了各模型作为简单相关性分类器的表现。结果显示,ReasonRR确实在精确度(precision)和F1分数上优于ReasonRR-NoReason,但后者在NDCG@10指标上表现更好。这说明仅仅提高相关性分类的准确度并不足以提升重排的效果。
其次,研究者分析了各模型产生的相关性分数分布。发现StandardRR和ReasonRR都将大约70%的文章分类为低相关性(0-0.1分),但对于剩余文章,StandardRR会将相关性分数分布在中间区域(0.1-0.9分)和高相关性区域(0.9-1.0分),比例分别为11.4%和19.7%。而ReasonRR几乎不给文章分配中间相关性分数,将所有部分相关的文章都集中分配在极高相关性区域(29.0%)。这证实了推理过程确实导致了更极化的判断。
第三,通过定性分析,研究者发现ReasonRR在推理过程中可能会明确提到文章"部分相关",但因为最终必须选择"相关"或"不相关"的二分结果,它往往会倾向于将部分相关归类为高度相关,导致相关性分数极高(接近1)。
这就像一个审慎的法官和一个直觉型法官的区别。审慎法官会详细推理,但最终只能判"有罪"或"无罪",这可能导致非黑即白的判决。而直觉型法官虽然不详细解释,但可能更能表达"这个案件不是完全有罪,但有一定嫌疑"的微妙判断。在重排任务中,这种灵活性反而更为重要。
四、改进方向:如何让推理更有效?
研究者并没有完全否定推理在重排中的价值,而是探索了如何改进推理重排器。他们尝试了"自洽性"(Self-Consistency)技术,即生成多个推理链,然后平均它们的预测结果。这种方法确实使ReasonRR的相关性分数分布更加均匀,并在MS MARCO和BRIGHT数据集上分别提高了1.8和2.9个百分点的NDCG@10。
然而,即使经过这种改进,推理重排器的表现仍落后于标准重排器。这表明,至少在当前技术条件下,简单、直接的方法可能更为有效和资源高效。
研究团队还提出了几种潜在的改进方向:
一种思路是训练推理重排器预测非二元的相关性分数,例如从1到5的评分,而不是简单的"相关"或"不相关"。这可能使模型更好地表达部分相关性。
另一种思路是从推理过程中提取信号,当模型明确表示"部分相关"时,利用这些线索产生更准确的中间分数。
第三种思路是通过设计专门的损失函数,直接训练模型产生校准良好的分数,鼓励输出能反映各种程度的相关性。
这些改进方向仍是开放的研究问题,需要未来工作进一步探索。
总的来说,这项研究挑战了我们对推理过程在重排任务中作用的传统认识。研究表明,至少对于逐点重排任务,简单直接的方法可能比复杂的推理过程更有效,这不仅带来了理论上的新见解,也为构建更高效的信息检索系统提供了实用指导。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

LLM情境调节与持续工作流程提示:革新化学分子式的多模态验证技术
这项研究探索了如何通过"LLM情境调节"和"持续工作流程提示"技术来提高大型语言模型在验证化学分子式时的准确性。研究者发现,普通提示方法往往不可靠,因为LLM倾向于自动"纠正"错误而非指出它们。然而,通过精心设计的情境调节提示,研究成功引导Gemini 2.5 Pro不仅识别出文本中的错误,还发现了之前人工审阅未察觉的图像中的分子式错误。这一概念验证研究表明,即使不修改模型本身,也能通过适当的提示策略显著提高LLM在科学技术文档细节验证中的表现。

微生物显微图像分割新突破:复旦大学研究团队借助多模态大语言模型统一显微镜下的"万物分割"
复旦大学研究团队开发的uLLSAM模型成功将多模态大语言模型(MLLMs)与分割一切模型(SAM)结合,解决了显微镜图像分析的跨域泛化难题。通过创新的视觉-语言语义对齐模块(VLSA)和语义边界正则化(SBR)技术,该模型在9个领域内数据集上提升了7.71%的分割准确度,在10个从未见过的数据集上也展现了10.08%的性能提升。这一统一框架能同时处理光学和电子显微镜图像,大大提高了生物医学图像分析的效率和准确性,为科研人员提供了强大的自动化分析工具。

用强化学习让大语言模型为汇编代码提速:斯坦福团队的优化探索
斯坦福大学等机构研究团队利用强化学习训练大语言模型,使其能够优化汇编代码性能。研究构建了8,072个程序的数据集,并通过近端策略优化(PPO)训练模型生成既正确又高效的汇编代码。实验表明,训练后的Qwen2.5-Coder-7B-PPO模型实现了96.0%的测试通过率和1.47倍平均加速比,超越包括Claude-3.7-sonnet在内的所有其他模型。研究发现模型能识别编译器忽略的优化机会,如用单一指令替代整个循环,为性能敏感应用提供了有价值的优化途径。

播放师傅变声魔术:让你的录音遵循参考风格的推理时间优化新方法
这项研究提出了一种改进的声乐效果风格迁移方法,通过在推理时间优化过程中引入高斯先验知识,解决了传统ST-ITO方法忽视参数合理性的问题。研究团队基于DiffVox数据集构建了专业效果器参数分布模型,将风格迁移转化为最大后验概率估计问题。实验结果表明,该方法显著优于基准方法,参数均方误差降低了33%,并在主观听感测试中获得最高评分。这一创新为音频处理领域融合数据驱动和专业知识提供了新思路。

LLM情境调节与持续工作流程提示:革新化学分子式的多模态验证技术

微生物显微图像分割新突破:复旦大学研究团队借助多模态大语言模型统一显微镜下的"万物分割"

用强化学习让大语言模型为汇编代码提速:斯坦福团队的优化探索

播放师傅变声魔术:让你的录音遵循参考风格的推理时间优化新方法
