 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
大型语言模型的一步生成能力:揭秘人工智能"一口气"说故事的秘密 - AIRI与Skoltech研究成果
在我们日常使用ChatGPT或类似AI助手时,它们总是一个词一个词地生成回答,仿佛在思考着下一个词应该是什么。但你有没有想过,这些AI模型是否能一次性生成一大段完整的文字,而不是一个词接一个词地输出?这个看似简单的问题背后,隐藏着人工智能领域一个鲜为人知的能力。
近日,来自AIRI(人工智能研究所)和Skoltech(斯科尔科沃科技学院)的研究人员Gleb Mezentsev和Ivan Oseledets在一项突破性研究中揭示,大型语言模型(LLMs)具有惊人的"一步生成"能力。这项研究成果以《探索大型语言模型一步文本生成的潜在能力》(Exploring the Latent Capacity of LLMs for One-Step Text Generation)为题,于2025年5月27日发表在arXiv预印本平台(arXiv:2505.21189v1)。
你可能会问,这和我们有什么关系?想象一下,如果AI能一次性生成数百个甚至更多的单词,而不是逐个生成,这将大大提高AI的响应速度。特别是在资源有限的设备上,或者需要快速响应的场景中,这种能力可能会带来革命性的变化。
一、研究背景:从逐词生成到一次成型
大型语言模型就像一个讲故事的人,通常需要思考每一个词,然后才能说出下一个词。这种所谓的"自回归生成"方式,就像你讲故事时,根据已经说过的内容,一步步思考接下来要说什么。例如,如果你说"我今天去了",你会根据这个开头来决定下一个词是"超市"、"公园"还是其他地方。
2025年,研究人员Kuratov等人发现了一个有趣的现象:如果给大型语言模型一个特殊训练过的"记忆令牌"(就像给故事讲述者一个提示卡片),模型可以基于这个提示自动重建整个故事,长度可达数千个词。这就像给讲故事的人一个特殊的提示,他就能想起整个故事并逐字复述出来。
但Mezentsev和Oseledets提出了一个更进一步的问题:模型真的需要一个词一个词地生成吗?它能否像摄影师按下快门一样,一次性捕捉整个画面?换句话说,模型能否在一次前向计算中,不借助逐步生成,直接输出一整段准确的文本?
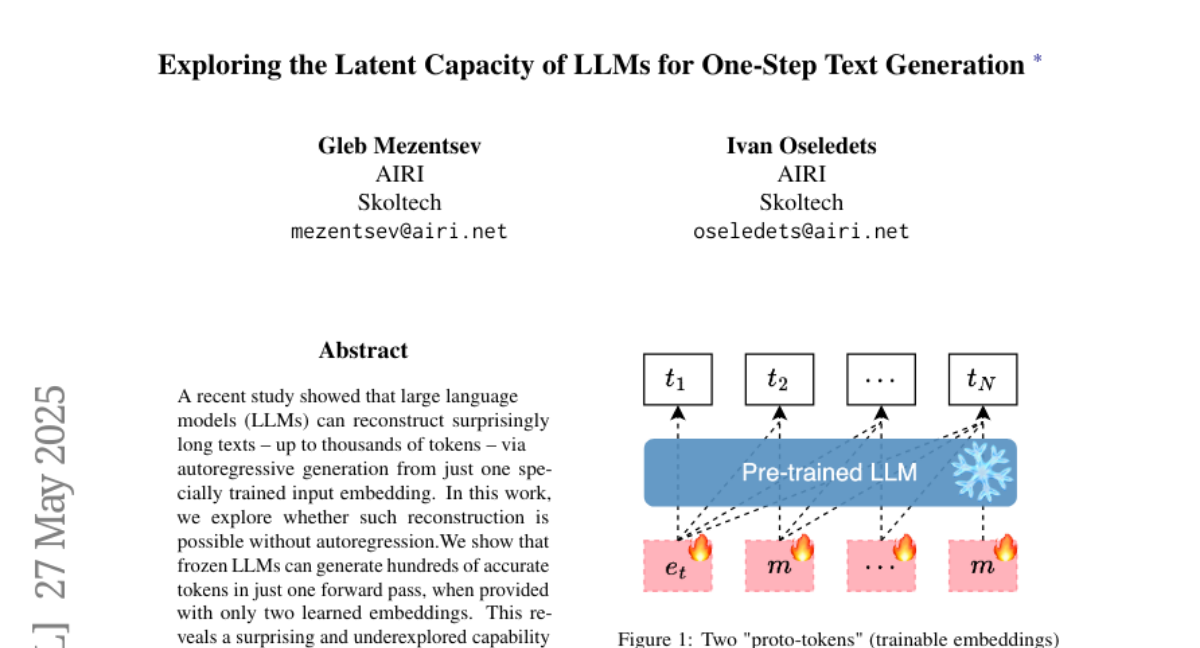
二、研究方法:两个神奇的"原型令牌"
研究团队设计了一个巧妙的实验,他们使用了两个可训练的特殊向量,称为"原型令牌"(proto-tokens)。这些并不是真正的词汇表中的词,而是经过特殊训练的向量。想象一下,这就像给讲故事的人两张神奇的卡片,他看到这两张卡片后,不需要一个词一个词地想,而是能够一次性说出整个故事。
具体来说,他们的方法是:
首先,研究团队创建了两个可训练的"原型令牌",分别标记为e和m。想象这就像两张白纸,研究人员可以在上面写下特定的信息。
然后,他们构造了一个输入序列,将一个e令牌放在最前面,后面跟着多个m令牌。如果想要生成N个词的文本,输入序列就是[e, m, m, ..., m],总共N个令牌。这就像排列这两张卡片,一张放在前面,另一张的复制品排在后面。
接下来,他们使用交叉熵损失函数(一种衡量预测准确性的方法)来训练这两个令牌的内容,目标是让模型在看到这些令牌后,能够一次性准确预测出目标文本序列。这相当于反复调整卡片上的内容,直到讲故事的人看到卡片后能准确地说出整个故事。
最关键的是,在这个过程中,语言模型本身是"冻结"的,也就是说,模型的参数不会改变,只有这两个"原型令牌"的内容会被优化。这就像不改变讲故事人的讲故事能力,只改变提示卡片上的内容。
三、惊人发现:一次前向计算,生成数百个准确词汇
研究结果令人惊讶。研究团队发现,大型语言模型确实能够在单次前向计算中生成长达数百个词的准确文本。具体来说,Llama 3.1-8B模型能够一次性准确重建长达724个词的序列,而Pythia-1.4B模型则能重建约128个词的序列。
这就像是一个人能够看一眼提示卡片,然后一口气准确无误地说出一个包含数百个词的故事,而不需要停下来思考下一个词应该是什么。
更有趣的是,研究团队发现这种能力对令牌的排列方式非常敏感。如果只使用一个可训练的令牌,模型甚至无法准确重建两个词的文本。而当使用两个令牌,并且按照特定方式排列(一个e令牌后跟多个m令牌)时,模型的表现最佳。这表明这两个令牌可能扮演着不同的功能角色。
就像一个魔术师需要特定的道具和准确的摆放位置才能完成魔术一样,大型语言模型也需要这两个特殊令牌以特定方式排列,才能发挥出"一步生成"的能力。
四、令牌共享:模型的神奇记忆方式
研究团队进一步探索了一个有趣的问题:这两个"原型令牌"是否都需要针对每个文本单独训练,还是可以在不同文本之间共享?
他们的实验表明,无论是共享e令牌还是m令牌,模型都能保持相当高的重建准确性。具体来说,即使在256个不同文本的组中共享一个令牌,模型仍然能达到约83-86%的平均重建准确率,如果选择最佳的随机初始化,甚至可以达到99-100%的准确率。
这就像给讲故事的人一张固定的卡片和一张可变的卡片,无论哪张是固定的,他都能利用这两张卡片讲出不同的故事。这表明这两个令牌可能扮演着不同但互补的角色。
研究人员推测,如果e令牌被共享(放在序列最前面的令牌),这可能类似于"提示调整"(prompt-tuning)技术,就像告诉模型"接下来你要解码m令牌中的信息"。如果m令牌被共享,这可能类似于某些"推测解码"(speculative decoding)方法,模型需要根据前面的e令牌来确定如何解释后面相同的m令牌。
五、不同模型和文本类型的表现
研究团队测试了不同大小的模型和不同类型的文本,以了解这种"一步生成"能力的普遍性和局限性。
他们使用了六个不同的模型:三个Pythia模型(160M、410M和1.4B参数)和三个Llama模型(1B、3B和8B参数)。测试的文本包括随机文本、粉丝小说(训练数据之外的自然文本)、PG-19数据集(训练数据中的自然文本)以及模型自己生成的文本。
结果表明,Llama系列模型的表现随着模型大小的增加而显著提升,而Pythia系列模型则不太明显。有趣的是,Llama-1B模型的重建能力比同等大小的Pythia模型高出近三倍。
对于自然文本(无论是否在训练数据中),模型的重建能力没有显著差异。然而,对于随机文本,模型的表现明显下降。这表明"原型令牌"并不是简单地存储文本的每个词,而是以某种更高级的方式编码文本,利用模型的语言能力。
就像一个人可以轻松记住有意义的故事,但很难记住毫无规律的随机词汇列表一样,模型似乎也更擅长处理有语言规律的自然文本。
六、自回归生成与一步生成的对比
研究人员还将这种"一步生成"方法与传统的自回归生成方法进行了比较。他们发现,虽然一步生成方法在信息密度上通常比自回归方法低(大约低2-5倍),但在生成速度上有显著优势,平均快约279倍。
想象一下,如果传统方法需要5分钟生成一段文本,这种新方法可能只需要1秒多一点。这种巨大的速度提升主要是因为传统方法需要多次前向计算(每生成一个词都需要计算一次),而新方法只需要一次计算就能生成整段文本。
这种速度优势在快速上下文压缩和解压缩、设备端推理或对解码速度要求特别高的场景中可能特别有价值。
七、解密"原型令牌":它们到底编码了什么?
研究团队还试图理解这些"原型令牌"实际上编码了什么信息。如果它们只是简单地存储目标词的ID,那么所有的"语言生成"工作实际上都发生在编码阶段,解码过程就没有太大意义。另一种可能是,这些令牌编码了某种压缩表示,模型在解码时会基于这种表示生成文本。
为了探索这个问题,研究人员分析了不同"原型令牌"嵌入之间的关系。他们发现,对应于同一文本但来自不同随机初始化的解决方案,它们在嵌入空间中的距离通常比对应于不同文本的解决方案更近。这表明学习到的表示具有某种局部性。
更有趣的是,对于从同一上下文生成的不同文本,即使这些文本在词汇层面或语义层面的相似度相同,它们的"原型令牌"嵌入也比从不同上下文生成的文本的嵌入更接近。这表明"原型令牌"不仅包含关于目标序列本身的信息,还包含关于序列潜在上下文的信息。
这就像讲故事的人不仅记住了故事本身,还记住了这个故事来自哪本书或哪个作者,这些背景信息也被编码在了提示卡片中。
八、解决方案空间的结构:寻找连接的路径
最后,研究人员探索了解决方案空间的结构。Kuratov等人之前发现,在自回归设置中,同一文本的不同嵌入解决方案之间的线性插值通常不会产生有效的重建。这表明解决方案空间可能缺乏平滑性和局部性,这对于构建实用的编码器来说是个问题。
研究团队发现,在他们的非自回归设置中,线性插值同样不能产生有效解决方案。然而,使用二次贝塞尔曲线(抛物线段)可以在"解决方案集"内连接不同的解决方案。这意味着同一文本的解决方案虽然不形成凸集,但确实形成了一个连通集。
实际上,贝塞尔曲线长度与相应线性连接的比率仅为1.2,表明路径几乎是线性的。这些结果表明解决方案空间行为相当良好,为构建编码器模型提供了合理的希望。
就像在地图上,两点之间虽然不能直线相连(可能中间有障碍物),但可以找到一条平滑的曲线路径连接它们。这表明模型的内部表示空间有着相对有序的结构,这对未来开发能够利用这种能力的实用系统非常重要。
九、结论与未来展望
总的来说,这项研究揭示了大型语言模型一个令人惊讶的能力:它们可以在一次前向计算中生成数百个准确的词,而不需要逐步生成。这种能力需要两个特殊训练的"原型令牌",它们的数量和排列方式对性能至关重要。
虽然这种"一步生成"方法在信息密度上通常不如传统的自回归方法,但在生成速度上有显著优势。此外,研究还发现"原型令牌"不仅编码了目标序列的信息,还包含了关于序列潜在上下文的信息。
这项研究的局限性包括:缺乏直接的实际应用、对模型架构的依赖性以及有限的领域覆盖范围。研究更多地揭示了大型语言模型的一个有趣特性,而不是提供了可立即投入使用的方法。
然而,这些发现打开了新的研究方向,包括非自回归推理和表示学习。如果能够构建一个能够映射到这个空间的编码器,可能会为快速文本生成和压缩开辟新的可能性。
就像我们发现汽车不仅可以一步步前进,还可以一次性跨越长距离一样,这项研究揭示了大型语言模型潜在的"一步生成"能力,为AI文本生成的未来提供了新的视角和可能性。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

北航大学团队推出Easy Dataset:让普通人也能制作AI训练数据的神奇工具
北航团队推出Easy Dataset框架,通过直观的图形界面和角色驱动的生成方法,让普通用户能够轻松将各种格式文档转换为高质量的AI训练数据。该工具集成了智能文档解析、混合分块策略和个性化问答生成功能,在金融领域实验中显著提升了AI模型的专业表现,同时保持通用能力。项目已开源并获得超过9000颗GitHub星标。

网络安全AI助手:让电脑漏洞危险等级一秒识别的RoBERTa智能系统
卢森堡计算机事件响应中心开发的VLAI系统,基于RoBERTa模型,能够通过阅读漏洞描述自动判断危险等级。该系统在60万个真实漏洞数据上训练,准确率达82.8%,已集成到实际安全服务中。研究采用开源方式,为网络安全专家提供快速漏洞风险评估工具,有效解决了官方评分发布前的安全决策难题。

人工智能评判官:xVerify如何解决复杂推理模型的评估难题
中国电信研究院等机构联合开发的xVerify系统,专门解决复杂AI推理模型的评估难题。该系统能够准确判断包含多步推理过程的AI输出,在准确率和效率方面均超越现有方法,为AI评估领域提供了重要突破。

只需输入音频就能生成说话人视频?昆仑集团推出的Skywork R1V让AI同时看懂图片和推理数学
昆仑公司Skywork AI团队开发的Skywork R1V模型,成功将文本推理能力扩展到视觉领域。该模型仅用380亿参数就实现了与大型闭源模型相媲美的多模态推理性能,在MMMU测试中达到69.0分,在MathVista获得67.5分,同时保持了优秀的文本推理能力。研究团队采用高效的多模态迁移、混合优化框架和自适应推理链蒸馏三项核心技术,成功实现了视觉理解与逻辑推理的完美结合,并将所有代码和权重完全开源。

北航大学团队推出Easy Dataset:让普通人也能制作AI训练数据的神奇工具

网络安全AI助手:让电脑漏洞危险等级一秒识别的RoBERTa智能系统

人工智能评判官:xVerify如何解决复杂推理模型的评估难题

只需输入音频就能生成说话人视频?昆仑集团推出的Skywork R1V让AI同时看懂图片和推理数学
