 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
当上下文成为金子:上下文文档嵌入模型的评估与训练
这项研究来自由Illuin Technology、Equall.ai、CentraleSupélec和EPFL洛桑的联合团队,由Max Conti、Manuel Faysse、Gautier Viaud、Antoine Bosselut、Céline Hudelot和Pierre Colombo共同完成,发表于2025年5月30日的arXiv预印本平台(arXiv:2505.24782v1)。对于想深入了解的读者,可通过GitHub(https://github.com/illuin-tech/contextual-embeddings)获取完整研究材料。
一、研究背景:为何文档上下文如此重要?
想象一下,你正在阅读一本厚重的百科全书,寻找关于拿破仑的信息。突然,你看到一个孤立的句子:"他在1804年成为皇帝。"没有任何背景信息,你根本无法确定这个"他"是谁。这正是现代文档检索系统面临的一个核心问题。
当今,从医疗记录到法律文件,再到大规模行政档案,我们需要快速处理和查询越来越庞大的文本库。为了应对这一挑战,检索增强生成(RAG)系统应运而生。这些系统通常会将长文档分割成小块(称为"chunks"),然后对每个小块单独进行嵌入处理,以便于检索和阅读。
然而,这种分割方法存在一个致命缺陷:它切断了文档各部分之间的语义和概念联系。就像前面提到的拿破仑的例子,如果不知道这段文字在谈论谁,检索系统将难以匹配与拿破仑相关的查询。
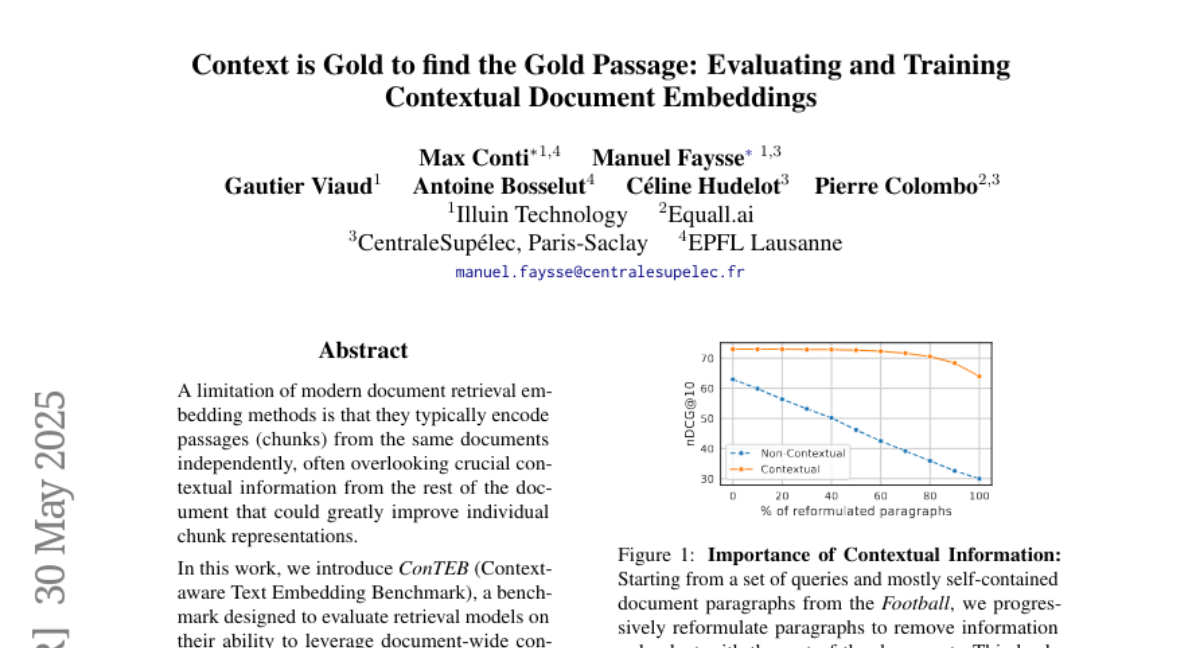
研究团队通过一个生动的实验展示了这个问题的严重性。他们从足球领域的文档中选取了一组段落,这些段落大多数是自包含的(意味着段落本身包含足够的信息)。然后,他们逐步改写这些段落,删除与文档其他部分重复的信息。结果表明,随着信息冗余的减少,标准检索系统的性能急剧下降,而具有上下文感知能力的系统则能保持稳定。
大型科技公司已经注意到这个问题,并试图通过大型生成语言模型(LLMs)来解决。一些方法尝试完全绕过检索步骤,直接在运行时将数百万个标记输入到模型的上下文窗口中。另一些方法则通过连接文档级摘要和上下文来重新表述单个段落。但这些方法在处理包含成千上万文档的语料库时成本高得令人望而却步。
二、ConTEB:评估模型对上下文的利用能力
现有的基准测试未能捕捉到上下文相关检索的挑战。它们通常依赖于这样的数据集:文档块被设计为对查询的自包含答案,这在现实中是一种理想化的情景。甚至有研究表明,一些广泛使用的基准测试存在偏见,有利于标准的上下文无关检索方法。
为了填补这一空白,研究团队开发了ConTEB(上下文感知文本嵌入基准),这是一个专门设计用来评估检索系统在索引和检索文档块时利用整个文档信息能力的基准测试。
ConTEB基准测试的构建分为三个阶段:
首先是分块阶段。研究人员选择了跨越多个领域的长文档,并通过结构感知方法将它们分块。想象这就像是将一本大书根据章节和段落分成更小的部分,而不是简单地每隔固定数量的文字就切一刀。
其次是配对阶段。研究人员使用手动注释的答案范围(例如在SQuAD、ESG数据集中)或通过大型语言模型合成标记(如在CovidQA、MLDR、NarrativeQA中),将查询与第一阶段获得的块匹配起来。在他们的控制实验任务中,他们手动(保险数据集)或通过大型语言模型(足球、地理数据集)生成与块相关的查询。
最后是"破坏"阶段。在保险数据集中,问题被设计成在不了解文档结构的情况下会产生歧义。更进一步,在足球和地理数据集中,研究人员在除了每个文档的第一个块之外的所有块中,删除了对文档主题的明确提及(而所有查询都会提到这个主题)。这就像是将拿破仑的名字从大多数段落中删除,只在第一段中提及,但所有问题仍然会问"拿破仑做了什么"。
ConTEB包含了各种类型的数据集:从MLDR(百科全书式)、NarrativeQA(文学)、SQuAD(问答)等学术数据集,到足球、地理、保险、Covid-QA和ESG报告等多样化领域的数据。此外,研究人员还使用NanoBEIR来评估模型在标准非上下文化嵌入任务上的表现,确保新方法不会损害基本模型性能。
三、InSeNT:高效的上下文训练方法
在确定了问题并建立了评估基准后,研究团队提出了一种新的嵌入后训练方法——InSeNT(序列内负面训练)。这种方法借鉴了"后期分块"技术,并进行了创新性的改进。
想象一下拼图游戏:传统方法是每个拼图块单独看待,而研究团队的方法则是先看整幅图,再决定每个拼图块的特征。具体来说,标准检索系统对文档的每个块进行独立编码:
φ(d) = [φ(c?), φ(c?), ..., φ(c?)]
而在"后期分块"方法中,首先将所有块连接起来,然后在单一前向传递中计算整个序列的表示:
H = φ(c? ⊕ c? ⊕ ... ⊕ c?)
接着,在每个原始块内应用平均池化来获得块级表示:
φ_LC(c_i) = (1/|c_i|) ∑_{t∈c_i} h_t
这允许每个块的表示在汇总前从整个文档的上下文中受益。
研究团队在此基础上增加了一个创新的学习目标。他们结合了两种对比学习损失:
1. 传统的批内对比损失,将来自不同文档的块视为"负样本" 2. 序列内对比损失,将来自同一文档的其他块视为"硬负样本"
这种双重对比学习可以用一个加权的InfoNCE损失来表达:
L = λ_seq * L_seq + (1 - λ_seq) * L_batch
直观地说,这种训练方法既鼓励同一文档内块之间的信息传播(通过批内对比),又确保每个块保持其特异性(通过序列内对比)。这就像教会模型既要认识到所有关于拿破仑的段落都属于同一个主题,又要能区分哪个段落讲的是他的童年,哪个讲的是他的军事成就。
研究团队的训练策略设计为轻量级的,可以在预训练的嵌入模型之上进行,而不会降低它们的原有能力。他们使用AdamW优化器,余弦衰减学习率调度器,初始学习率为5e-5,在训练数据集上训练2个轮次。整个训练过程在一台H100 GPU上不到一小时就能完成。
四、实验结果:上下文是金子
研究结果清晰地表明,利用上下文信息的方法大大优于非上下文方法。在ConTEB基准测试中,研究团队的InSeNT变体显著优于其未训练的对应物(ModernBERT的nDCG@10提高了14.6,ModernColBERT提高了11.5)。
特别值得注意的是,这种改进不是源于训练数据本身。使用相同数据训练的非上下文ModernBERT模型并没有比未训练的基线有所改进。最大的改进出现在那些专门设计用来引出前面段落中给出信息的控制设置任务(保险、足球)上,这些任务与训练集的领域不同。
研究还发现,当λ_seq参数(控制序列内和批内负样本的相对重要性)从0变化到1时,不同任务的最佳值各不相同。当文档需要在彼此之间进行区分时(如NanoBEIR、地理),增加批内负样本的权重似乎是最佳选择。而在挑战在于定位给定文档内信息的任务中(如NarrativeQA、CovidQA),序列内负样本起着重要作用,但仍需与批内负样本结合。找到最佳权衡非常依赖于具体用例,研究团队在验证集上调整后选择了λ_seq = 0.1。
在效率方面,研究团队的方法在上下文任务上表现出色,同时几乎不增加计算开销。事实上,他们发现索引速度略有提高,这归因于减少了批内不同长度序列的填充需求。相比之下,Anthropic的上下文化方法虽然在ConTEB上取得了类似的性能,但它依赖于成本高昂的基于LLM的摘要和块重构,难以扩展到大型语料库(速度慢120倍)。
进一步的实验表明,上下文化嵌入对块策略的鲁棒性更强。当研究人员将原始的自包含块分割成越来越小的子块时,非上下文嵌入的性能急剧下降,而上下文嵌入则保持相对稳定。这表明该模型能够从相邻块中提取信息,在较小的子块中整合上下文信息,从而在各种块大小下保持更一致的检索性能。
同样,当增加语料库中相似文档的数量时,上下文嵌入的扩展方式与独立嵌入的对应物大不相同。直观地说,语料库中相似文档和块的数量越多,检索系统就越难匹配正确的文档,但当嵌入模型能够利用外部上下文时,这种效应会减弱。
五、研究局限性与未来方向
尽管研究团队的方法在上下文依赖的环境中显著提高了检索性能,但仍存在一些局限性。
首先是上下文长度的限制。该方法应用于支持最多8k标记序列的长上下文编码器。虽然研究表明他们可以将性能外推到最多32k标记的序列,但使用基于解码器的模型扩展这种方法以处理百万级标记的上下文将是一个有趣的研究方向,并且会带来显著的计算和内存挑战。此外,这还需要重新思考数据构建过程,以确保更长的文档得到有效利用。
其次是数据生成的挑战。训练和评估数据的创建依赖于现有数据集和半合成生成管道。然而,一种完全自动化和可扩展的方法,用于生成能有效诱导非平凡上下文利用的高质量查询,仍然是一个开放的挑战。
最后,虽然该模型在跨领域表现出色,但在实际应用中进一步验证其在各种用例、多种语言中的鲁棒性和通用性是必要的。
六、结论:上下文改变一切
归根结底,这项研究清晰地表明,在文档检索中整合上下文信息不仅是有益的,而且是必要的。研究团队通过ConTEB基准测试证明了标准检索模型在上下文依赖的情境中的局限性,并提出了InSeNT,这是一种结合后期分块和新型训练方法的方法,在不增加计算开销的情况下显著提升了上下文检索性能。
对于实际应用,这意味着更智能的文档搜索系统,能够理解诸如"他在1804年成为皇帝"这样的句子确实是在谈论拿破仑,即使该句子本身并未提及他的名字。这种能力对于处理医疗记录、法律文件或任何结构化长文档的行业都具有重大价值。
随着大型语言模型和检索系统的不断发展,研究团队的工作为未来的嵌入模型指明了方向:不仅要关注单个文本片段的表示,还要考虑它们在更广泛文档上下文中的位置和关系。正如研究标题所言,"上下文是金子,能找到金子般的段落"。
有兴趣深入了解这项研究的读者可以访问GitHub仓库(https://github.com/illuin-tech/contextual-embeddings),获取基准测试、模型和训练数据等项目材料。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站


大语言模型为什么老是"胡编乱造"?OpenAI团队揭开AI幻觉的真相
OpenAI团队的最新研究揭示了大语言模型产生幻觉的根本原因:AI就像面临难题的学生,宁愿猜测也不愿承认无知。研究发现,即使训练数据完全正确,统计学原理也会导致AI产生错误信息。更重要的是,现有评估体系惩罚不确定性表达,鼓励AI进行猜测。研究提出了显式置信度目标等解决方案,通过改革评估标准让AI学会诚实地说"不知道",为构建更可信的AI系统指明方向。

ByteDance AI实验室发布重磅研究:让计算机学会"逆向思考",解决创意写作难题
字节跳动AI实验室提出"逆向工程推理"新范式,通过从优质作品反推思考过程的方式训练AI进行创意写作。该方法创建了包含2万个思考轨迹的DeepWriting-20K数据集,训练的DeepWriter-8B模型在多项写作评测中媲美GPT-4o等顶级商业模型,为AI在开放性创意任务上的应用开辟了新道路。

电脑终于学会了像人类一样用键盘鼠标:ByteDance推出会玩游戏的AI助手
ByteDance Seed团队开发的UI-TARS-2是一个革命性的AI助手,能够通过观看屏幕并用鼠标键盘操作电脑,就像人类一样完成各种任务和游戏。该系统采用创新的"数据飞轮"训练方法,在多项测试中表现出色,游戏水平达到人类的60%左右,在某些电脑操作测试中甚至超越了知名AI产品,展现了AI从对话工具向真正智能助手演进的巨大潜力。

阿里要用AI将云计算重做一遍

大语言模型为什么老是"胡编乱造"?OpenAI团队揭开AI幻觉的真相

ByteDance AI实验室发布重磅研究:让计算机学会"逆向思考",解决创意写作难题

电脑终于学会了像人类一样用键盘鼠标:ByteDance推出会玩游戏的AI助手
