 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
ComposeAnything:来自INRIA的人工智能新突破,让AI图像生成理解复杂空间关系
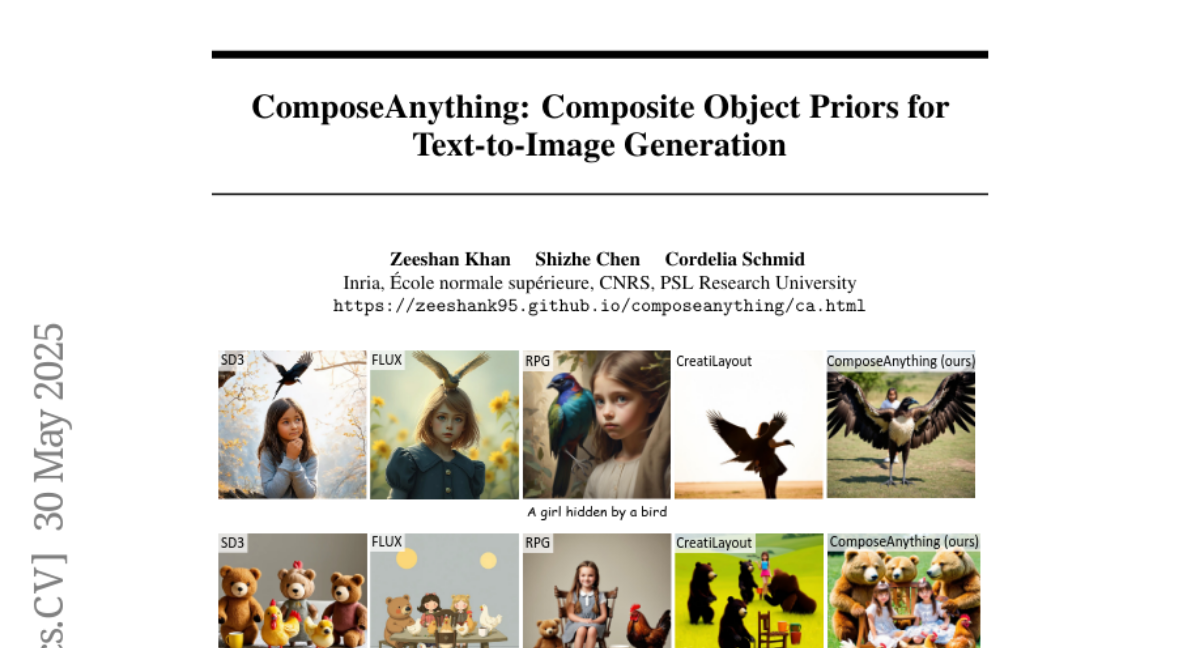
在2025年5月,法国国家信息与自动化研究所(INRIA)、巴黎高等师范学院和法国国家科学研究中心(CNRS)的研究团队 Zeeshan Khan、Shizhe Chen 和 Cordelia Schmid 联合发布了一项令人瞩目的研究成果:ComposeAnything。这项发表于arXiv预印本平台(arXiv:2505.24086v1)的研究为人工智能图像生成领域带来了重大突破,解决了当前AI绘画中一个让人头疼的问题——复杂物体组合的精准生成。
想象一下,你对AI说:"请画三只熊、两个女孩、三只鸡、一把椅子和两个杯子",或者"画一个被鸟挡住的女孩"。对于人类来说,理解这些指令并不困难,但对于现有的AI绘画模型来说,这些复杂的空间关系和多物体组合却是一道难以逾越的鸿沟。现有模型经常会"搞混"物体数量、位置关系,甚至将物体混合在一起,生成不符合要求的图像。
ComposeAnything就像是给AI图像生成模型装上了一副特殊的"空间感知眼镜",使其能够更好地理解和呈现物体之间的复杂关系。这个框架不需要重新训练现有的文本到图像(Text-to-Image,简称T2I)模型,而是巧妙地利用了大型语言模型(LLM)和扩散模型的优势,在推理阶段引入了复合物体先验(Composite Object Prior)的概念,使得生成过程更加可控和精准。
这项技术的工作原理如同一位经验丰富的电影导演在拍摄前先做分镜头脚本。首先,大型语言模型会像编剧一样仔细分析文本指令,生成一个详细的"2.5D语义布局",包括每个物体的说明、位置和深度信息。然后,系统会根据这个布局"草稿"生成一个粗略的场景合成图,作为最终图像生成的"先验指导"。这个过程就像是先画出电影场景的草图,然后再由专业团队完成精细的拍摄和后期制作。
研究团队在两个挑战性测试基准(T2I-CompBench和NSR-1K)上的实验表明,ComposeAnything远超现有方法,特别是在处理2D/3D空间关系、高物体数量和超现实组合方面。人类评估也证实,这种方法能够生成高质量图像,同时忠实反映输入文本的要求。
接下来,让我们深入了解这项创新技术的工作原理、主要组成部分以及它如何改变AI图像生成的未来。
一、为什么现有AI绘画模型难以处理复杂组合?
在深入了解ComposeAnything之前,我们需要先理解为什么现有的AI绘画模型在处理复杂场景时会"力不从心"。
想象你正在用遥控器指挥一位蒙着眼睛的画家作画。你只能通过语言描述你想要的画面,而画家必须在没有视觉参考的情况下完成创作。这基本上就是当前文本到图像(T2I)模型的工作方式——它们只能根据文本描述"想象"出一幅画。
虽然像Stable Diffusion 3(SD3)、FLUX等最新模型在生成单个概念(如"一只猫"或"一朵花")时表现出色,但当面对多个物体的复杂组合时,它们往往会"晕头转向"。就像那位蒙眼画家,当你要求他画"三只熊、两个女孩、三只鸡、一把椅子和两个杯子"时,他很可能会混淆物体数量、位置,甚至将不同物体的特征混合在一起。
这主要是因为这些模型在训练过程中很少接触到如此复杂的组合场景,它们对3D空间关系的理解也十分有限。就像一个从未看过魔术表演的人很难描述魔术师是如何将助手"切成两半"的细节一样,AI模型也难以理解和呈现它从未"见过"的复杂空间关系。
为了解决这个问题,研究人员提出了各种布局控制方法。其中训练型方法(如CreatiLayout)通过额外训练来增强模型的布局控制能力,但往往会因为过于严格的布局约束而牺牲图像质量和连贯性。而免训练方法(如RPG)则尝试在推理阶段引入布局控制,但控制能力较弱,难以处理复杂指令。
更重要的是,现有方法主要依赖于粗糙的2D布局,既不包含3D空间关系信息,也无法视觉化表达物体的外观,这极大限制了它们指导T2I生成的有效性。
二、ComposeAnything:如何让AI理解空间关系的"魔法"
ComposeAnything的神奇之处在于它巧妙地结合了大型语言模型的推理能力和扩散模型的图像生成能力,创造了一个无需额外训练就能增强图像生成质量的框架。这个框架包含三个关键组件:LLM规划、复合物体先验和先验引导扩散。
首先,让我们通过一个简单的例子来理解这个过程:假设我们要生成"一个女孩站在一只鸡后面"的图像。
**1. LLM规划:智能"导演"的分镜头脚本**
ComposeAnything首先调用GPT-4.1这样的大型语言模型,通过链式思考推理(chain-of-thought reasoning)将文本指令分解为结构化的2.5D语义布局。这就像电影导演在拍摄前绘制详细的分镜头脚本,规划每个角色的位置、动作和场景安排。
在我们的例子中,LLM会分析"一个女孩站在一只鸡后面"这个指令,并提供以下信息:
- 物体描述:详细描述每个物体的大小、朝向和外观,如"穿蓝色T恤、面向左侧站立的小女孩"和"站在地面上的鸡" - 边界框:为每个物体指定2D空间位置,如女孩的框为[550, 200, 780, 700],鸡的框为[300, 550, 600, 1000] - 深度值:反映每个物体的相对深度顺序,如鸡的深度为1(更靠近观察者),女孩的深度为2(更远) - 背景描述:描述整个场景的背景 - 综合描述:对整个图像的简洁摘要
这种详细的规划为下一步的图像生成提供了清晰的"蓝图",就像建筑师的设计图纸指导建筑施工一样。
**2. 复合物体先验:从"草图"到"模型"**
有了详细的布局规划后,ComposeAnything接下来会为每个物体生成独立的图像。这一步使用现有的T2I模型(如SD3-M)根据每个物体的描述生成单独的图像,然后通过Hyperseg模型提取物体及其分割掩码。
这些独立生成的物体随后会按照边界框和深度信息进行缩放和组合,创建一个粗略的复合场景。在我们的例子中,系统会生成女孩和鸡的独立图像,然后将它们按照规划的位置组合起来,鸡在前(更靠近观察者),女孩在后。
这个复合场景就像电影制作中的实物模型或概念艺术,为最终的图像生成提供了强有力的视觉参考。与传统扩散模型使用的随机噪声初始化相比,这种复合物体先验包含了丰富的语义信息和空间关系,能够更好地引导后续的图像生成过程。
**3. 先验引导扩散:从"模型"到"精细作品"**
有了复合物体先验后,ComposeAnything不是简单地从随机噪声开始生成图像,而是将这个先验转换为潜在空间的噪声,并用它来引导扩散过程。这一步包含两个关键机制:
- 物体先验强化:在早期扩散步骤中,系统会反复恢复前景物体先验,同时允许背景自然生成,确保物体的语义完整性和空间结构得到保留。就像电影后期制作中保留主要角色的表演,同时完善背景场景一样。
- 空间控制去噪:通过掩码引导的注意力机制,系统强化了复合先验的空间安排,特别是在早期扩散步骤中确定整体结构时。这就像电影导演确保每个演员都站在正确的位置上,同时保持整个场景的和谐与连贯。
在初始步骤之后,系统会切换到标准扩散,让模型自由完善图像的质量和连贯性,实现既忠实于原始指令又具有高视觉质量的图像生成。
通过这三个步骤的协同工作,ComposeAnything能够处理极其复杂的空间关系和多物体组合,生成既符合指令又视觉精美的图像。
三、实验结果:ComposeAnything的惊人表现
研究团队在T2I-CompBench和NSR-1K这两个挑战性测试基准上评估了ComposeAnything的性能。这些基准包含了丰富的空间关系、物体计数和复杂组合的测试案例,能够全面检验模型的组合生成能力。
在T2I-CompBench的四个类别(2D空间、物体计数、3D空间和复杂组合)上,ComposeAnything的表现远超所有现有方法。与基础模型SD3-M相比,它在2D空间类别上提升了16.9个百分点,在物体计数上提升了7.9个百分点,在3D空间关系上提升了惊人的27.7个百分点,在复杂组合上也有0.9个百分点的提升。
在NSR-1K基准上,ComposeAnything同样取得了显著优势,在空间关系和物体计数类别上分别比SD3-M提高了19.0和14.7个百分点。
这些数字可能看起来有些抽象,让我们通过一些具体例子来直观感受ComposeAnything的强大能力:
**复杂物体计数与组合**:"两只长颈鹿、两个面包、三个鸡蛋、四个草莓和三个微波炉" - SD3-M和FLUX等模型在面对这种复杂指令时往往会混淆物体数量,甚至将物体"卡通化"以牺牲真实感 - ComposeAnything则能准确生成正确数量的各类物体,同时保持真实感和图像质量
**超现实空间关系**:"一个气球在鸡的底部" - 传统模型难以理解这种非常规空间关系,往往会生成气球飘在鸡上方的常规场景 - ComposeAnything能够准确理解并呈现出鸡站在气球上的超现实场景
**复杂3D关系**:"一只鸡被时钟挡住" - 现有模型在处理"被...挡住"这类3D关系时往往会失败,生成并排或混合的物体 - ComposeAnything能够正确呈现时钟前面有一只鸡的场景,准确反映3D空间关系
人类评估结果进一步证实了ComposeAnything的优势。研究团队随机选取了T2I-CompBench中的30个提示词,让人类评估者比较ComposeAnything与RPG和CreatiLayout生成的图像。在2D空间、3D空间和物体计数三个类别上,ComposeAnything都以显著优势胜出,证明它在提示词一致性和图像质量方面的卓越表现。
四、技术深度解析:ComposeAnything如何工作?
现在,让我们更深入地了解ComposeAnything的技术细节,看看它是如何实现这些惊人成果的。
**LLM规划的精妙之处**
ComposeAnything使用GPT-4.1作为"智能规划师",通过精心设计的提示词引导LLM进行链式思考推理。这个过程包括几个关键步骤:
1. 首先,LLM会分析输入文本,识别可分离的物体元素和它们的属性,如数量、颜色、大小等 2. 然后,它会考虑物体之间的2D和3D空间关系,确定每个物体的相对位置和深度 3. 对于纠缠在一起难以分离的物体(如"戴戒指的女人"),LLM会将它们视为单一物体处理 4. 最后,LLM会为每个物体生成独立的描述、边界框和深度值,以及整个场景的综合描述
这种基于LLM的规划方法比简单的规则或模板更灵活,能够处理各种复杂的语言描述和隐含关系。
**复合物体先验的创新**
ComposeAnything的一个关键创新是将布局规划转化为视觉化的复合物体先验。这一步包括:
1. 使用SD3-M等T2I模型根据每个物体的独立描述生成单独的物体图像 2. 使用Hyperseg模型为每个物体提取准确的分割掩码 3. 根据布局规划中的边界框对物体进行缩放和定位 4. 按照深度值从后到前组合物体,确保正确的遮挡关系 5. 将组合后的场景编码为潜在空间的噪声,用于指导扩散过程
这种方法的优势在于它提供了一个强大的视觉化先验,包含了物体的外观、数量、大小和2.5D空间关系信息,远比简单的边界框或文本条件更有信息量。
**先验引导扩散的双重机制**
ComposeAnything的先验引导扩散过程包含两个相互补充的机制:
1. **物体先验强化**:在从时间步T到tp的去噪过程中,系统会在每一步后恢复前景区域的原始物体先验,同时保留去噪后的背景。这确保了前景物体的语义完整性和空间结构在早期去噪步骤中得到保留,同时允许背景在前景物体的存在下自然生成。
2. **空间控制去噪**:ComposeAnything利用SD3中的多模态扩散变换器架构,实现了区域级的空间控制。它将图像潜在变量分割为基础潜在变量和物体-背景潜在变量,后者进一步分割为各个物体和背景区域。每个区域与其对应的文本嵌入连接并通过联合自注意力处理,实现精确的区域级控制,同时保持全局视觉一致性。
这两种机制的结合使ComposeAnything能够在保持物体完整性和空间关系的同时,生成连贯自然的背景和高质量图像。
**超参数的平衡艺术**
ComposeAnything的性能受两个关键超参数的影响:
1. **tp**:决定在前向扩散中对先验图像采样和应用噪声的时间步。较低的tp值意味着更强的先验强度,增加忠实度但减少生成灵活性。
2. **Nsc**:决定空间控制去噪的步数。较高的值强化空间控制,但可能导致图像质量下降。
研究团队通过实验发现,设置tp为对应91.3%噪声水平(在Flow匹配计划中)和Nsc=3步,能够在忠实度和图像质量之间取得最佳平衡。
五、ComposeAnything的优势与局限
通过深入分析,我们可以总结出ComposeAnything的几个显著优势:
1. **免训练框架**:ComposeAnything不需要重新训练现有的T2I模型,可以直接应用于任何扩散型T2I模型,大大降低了应用门槛。
2. **强大的组合能力**:它能够处理复杂的空间关系、高物体数量和超现实组合,远超现有方法的表现。
3. **可解释性**:通过生成明确的2.5D语义布局和复合物体先验,ComposeAnything的生成过程变得更加透明和可解释。
4. **平衡的质量与控制**:它在保持强空间控制的同时,通过灵活的生成过程保证了图像质量和连贯性。
5. **适应性强**:该框架适用于各种复杂场景,包括常规空间关系、超现实组合和高物体数量的场景。
然而,ComposeAnything也存在一些局限:
1. **对LLM规划的依赖**:系统性能很大程度上依赖于LLM规划的质量。如果LLM生成的布局不准确,最终图像质量可能会受到影响。
2. **3D知识的局限**:虽然ComposeAnything比现有方法更好地处理3D关系,但它在扩散模型中缺乏完整的3D知识,在极其复杂的3D场景中可能会失败。
3. **计算开销**:生成复合物体先验和执行先验引导扩散需要额外的计算资源,可能增加生成时间。
六、未来展望:ComposeAnything开启的可能性
ComposeAnything不仅解决了当前T2I模型在复杂组合生成方面的挑战,还为未来研究开辟了新方向:
1. **增强的多模态理解**:通过结合LLM的推理能力和扩散模型的生成能力,ComposeAnything展示了多模态协同的巨大潜力。未来研究可以进一步探索这种协同,开发出对语言指令理解更深入的生成系统。
2. **更精细的3D控制**:虽然ComposeAnything引入了2.5D语义布局,但未来可以探索更完整的3D场景表示和控制方法,可能通过引入专门的3D理解模型来增强空间关系的表达。
3. **更高效的先验生成**:当前的复合物体先验生成过程需要为每个物体单独生成图像。未来可以研究更高效的先验生成方法,可能通过单次生成或模型蒸馏来减少计算开销。
4. **更广泛的应用场景**:ComposeAnything的框架可以扩展到视频生成、3D内容创建等更广泛的应用场景,为创意内容生成提供更强大的工具。
ComposeAnything的出现标志着AI图像生成向着更高级的语义理解和空间感知能力迈进了一大步。它不仅提高了生成图像的质量和忠实度,还增强了AI系统对复杂人类指令的理解能力,为未来人机交互和内容创作开辟了新的可能性。
当我们展望未来,可以想象这项技术将如何改变创意工作者的工作方式——设计师可以通过自然语言描述复杂场景,AI助手能够准确理解并生成符合要求的图像;电影制作人可以快速生成分镜头草图;教育工作者可以创建复杂的教学插图。这些应用不仅提高了工作效率,还将创意表达的门槛降低,让更多人能够将脑海中的想象转化为视觉作品。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

鸡尾酒会里如何听清朋友说话?清华大学揭秘语音分离的终极奥秘
清华大学等多家机构研究团队完成了语音分离技术的全面调研,系统梳理了从传统方法到深度学习的技术演进。研究揭示了"鸡尾酒会问题"的核心挑战,分析了各种学习范式和网络架构的优劣,并通过统一实验框架提供了公平的性能基准。调研涵盖了实时处理、轻量化设计、多模态融合等关键技术方向,为学术界和产业界的技术选型提供了重要参考,推动语音分离从实验室走向实际应用。

浙大团队发现AI画画的黄金时机:什么时候出手最重要?
浙江大学和腾讯微信视觉团队发现AI图片生成训练中"时机胜过强度"的重要规律,开发出TempFlow-GRPO新方法。通过轨迹分支技术精确评估中间步骤,结合噪声感知权重调整优化不同阶段的学习强度,将训练效率提升三倍,在复杂场景理解方面准确率从63%提升至97%,为AI训练方法论带来重要突破。

谷歌DeepMind重磅突破:AI机器人学会了像人类一样思考和决策
谷歌DeepMind发布突破性AI规划技术,让机器人学会像人类一样进行"情境学习"规划。该技术通过Transformer架构实现了快速适应新问题的能力,在迷宫导航、机器人控制等测试中表现优异,为自动驾驶、智能制造、医疗等领域应用奠定基础,标志着向通用人工智能迈出重要一步。

新南威尔士大学首创ZARA:让AI像侦探一样从运动传感器数据中识别人类活动
新南威尔士大学研究团队开发了ZARA系统,这是首个零样本运动识别框架,能够在未经专门训练的情况下识别全新的人类活动。该系统集成了自动构建的知识库、多传感器检索机制和分层智能体推理,不仅实现了比现有最强基线高2.53倍的识别准确率,还提供清晰的自然语言解释,为可穿戴设备和健康监护等应用领域带来了突破性进展。

鸡尾酒会里如何听清朋友说话?清华大学揭秘语音分离的终极奥秘

浙大团队发现AI画画的黄金时机:什么时候出手最重要?

谷歌DeepMind重磅突破:AI机器人学会了像人类一样思考和决策

新南威尔士大学首创ZARA:让AI像侦探一样从运动传感器数据中识别人类活动
