 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
双专家一致性模型:高效高质量视频生成的解决方案 - 香港大学和南京大学联合研究突破
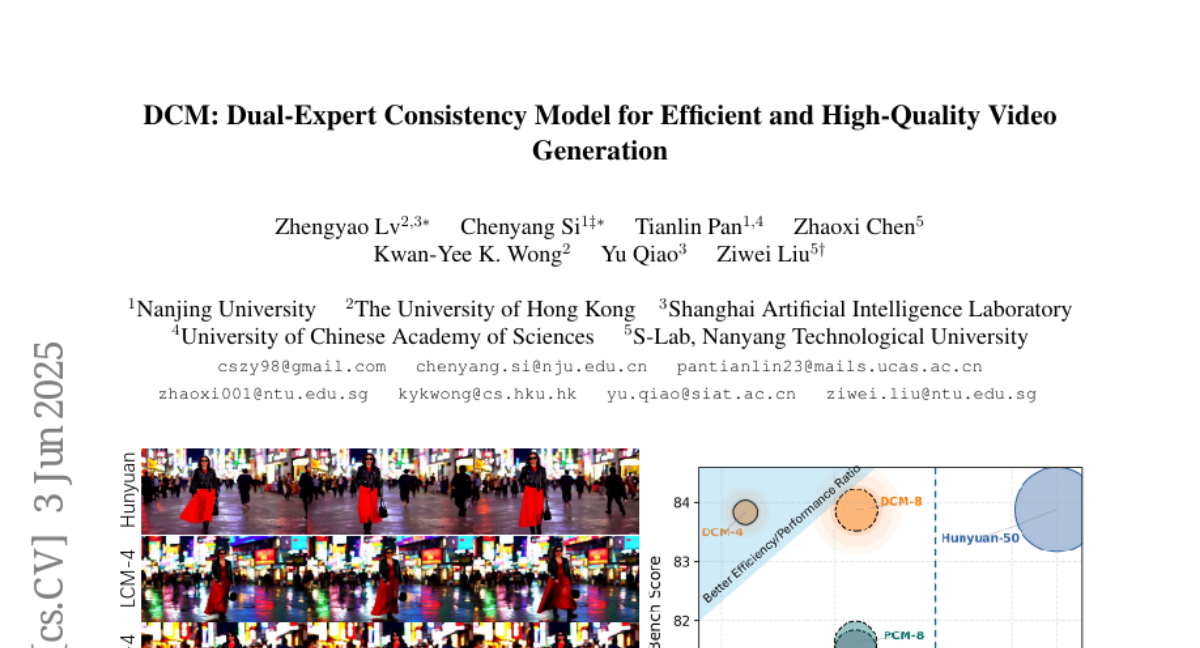
**香港大学、南京大学、上海人工智能实验室和南洋理工大学**的研究团队近期在视频生成领域取得了重要突破。这项研究名为《DCM: 双专家一致性模型用于高效高质量视频生成》(DCM: Dual-Expert Consistency Model for Efficient and High-Quality Video Generation),由Zhengyao Lv、Chenyang Si、Tianlin Pan、Zhaoxi Chen、Kwan-Yee K. Wong、Yu Qiao和Ziwei Liu等研究人员共同完成,论文发表于2025年6月3日的arXiv预印本平台(arXiv:2506.03123v1)。
**一、视频生成面临的难题:既要高质量又要高效率**
想象你正在拍一部电影。传统上,你需要一帧一帧地拍摄,这既费时又费力。现在的人工智能已经可以从文字描述自动生成视频,就像一位虚拟导演,能够根据你的剧本构思出完整的视觉内容。这些技术主要依靠"扩散模型"——一种能够从噪声中逐步提炼出清晰图像的人工智能系统。
然而,这些AI"导演"面临一个关键问题:它们需要进行大量的计算步骤才能生成高质量视频。这就像一位导演需要反复排练几十遍才能拍出满意的一个镜头。在实际应用中,这意味着即使使用强大的计算设备,生成一段高质量视频也需要花费数分钟甚至更长时间,严重限制了这项技术的实用性。
研究团队分析了现有的解决方案,比如"一致性模型"(Consistency Models),这些模型试图通过知识蒸馏的方式,将原本需要几十步的生成过程缩减到几步甚至一步。然而,当直接应用于视频生成时,这些方法往往会导致视频质量严重下降——动作不连贯、细节模糊、场景扭曲。
**二、问题根源:不同阶段的学习目标存在冲突**
为了找出问题所在,研究团队首先分析了视频生成的整个过程。他们发现,在生成视频的不同阶段,AI模型的学习目标存在明显差异。
想象一位画家正在创作一幅画。在最初的草图阶段,画家关注的是物体的大致形状、位置和整体布局;而在后期的精修阶段,画家则专注于添加细节、调整色彩和增强质感。这两个阶段需要截然不同的技能和关注点。
研究团队通过可视化分析发现,视频生成也遵循类似的模式: - 在早期阶段(高噪声水平),模型主要关注确定视频的语义布局和运动趋势,这时每一步的变化都非常明显和剧烈 - 在后期阶段(低噪声水平),模型则专注于精细化细节,每一步的变化变得更加微妙和渐进
更重要的是,他们发现当尝试将这两个阶段的任务合并到一个简化模型中时,会出现"优化冲突"。具体来说,在训练过程中,高噪声样本和低噪声样本的损失值和梯度大小存在显著差异,这导致模型无法同时有效地学习两种不同的任务。
这就像要求一个人同时成为一位出色的建筑师和一位精细的室内设计师——虽然这两种技能有一定关联,但专业方向不同,很难同时达到最高水平。
**三、双专家一致性模型:分工协作的创新解决方案**
基于上述发现,研究团队提出了一个巧妙的解决方案:为什么不让两位"专家"分别负责不同的任务呢?这就是"双专家一致性模型"(DCM)的核心思想。
具体来说,他们设计了两个专家模型: 1. 语义专家(Semantic Expert):专注于早期阶段,负责生成视频的语义布局和运动 2. 细节专家(Detail Expert):专注于后期阶段,负责细化和完善视频的细节
这就像电影制作中,先有导演确定整体场景和动作设计,再由摄影师和美术师负责调整光线、色彩和细节,各司其职,协作完成。
为了验证这一想法,研究团队首先进行了初步实验,分别训练了两个完全独立的专家模型。实验结果令人振奋:当这两个专家模型协作时,生成的视频质量确实显著提高。这证实了他们的核心假设:分离训练确实能够缓解优化冲突问题。
然而,使用两个完全独立的模型会导致参数数量翻倍,增加存储和推理成本。研究团队进一步分析了两个专家模型之间的参数差异,发现主要差异集中在两个方面:时间步嵌入层和注意力层中的线性层。
基于这一发现,他们提出了一种参数高效的实现方案:不是训练两个完全独立的模型,而是基于一个共享的基础模型,添加少量特定的参数来实现专业化。具体步骤如下:
1. 首先训练语义专家模型,负责视频的整体布局和运动 2. 然后冻结这个模型的大部分参数,仅添加少量新的时间步相关层和基于LoRA(低秩适应)的注意力层调整 3. 最后只训练这些新添加的参数,使其专门处理细节精修任务
这种方法大大减少了额外参数的数量,同时保持了两个专家各自的专业能力。就像一个人掌握了基础技能后,只需要少量额外训练就可以在特定方向上取得专业化成就。
**四、专家特定的优化目标:各自发挥所长**
除了模型结构的创新外,研究团队还为每个专家设计了特定的优化目标,进一步提升各自的专业能力。
对于语义专家,他们引入了"时间一致性损失"(Temporal Coherence Loss)。这个优化目标鼓励模型生成在时间上连贯一致的运动。可以理解为,这个损失函数要求模型特别关注视频中相邻帧之间的关系,确保运动流畅自然,避免出现卡顿或不合理的跳跃。
想象你在观看一个人走路的视频,如果每一帧之间的动作连贯,整体会显得自然流畅;但如果帧与帧之间不协调,人物可能会显得"闪烁"或"瞬移"。时间一致性损失就是帮助模型学会创造那种流畅自然的运动效果。
对于细节专家,他们采用了生成对抗网络(GAN)损失和特征匹配损失。GAN是一种让两个网络相互"竞争"的训练方法:一个网络负责生成内容,另一个网络负责判断内容是否真实。通过这种"博弈",生成网络能够学会创造更加真实、细节丰富的内容。
特征匹配损失则进一步要求生成的内容在中间特征层面也与真实内容相似,这有助于稳定GAN的训练过程并提高细节质量。这就像要求一位画家不仅要画出看起来像真实物体的画作,还要确保色彩、纹理等各个方面都符合现实世界的规律。
**五、实验结果:效率与质量的完美平衡**
研究团队在多个视频生成模型上测试了他们的方法,包括拥有130亿参数的HunyuanVideo和20亿参数的CogVideoX。测试结果非常令人鼓舞:
使用DCM后,模型只需4步采样就能生成高质量视频,相比原始模型需要的50步有了巨大提升。在HunyuanVideo模型上,DCM在仅用4步生成时,视频质量分数(VBench分数)达到83.83,几乎与原始50步模型的83.87相当。同时,生成129帧1280×720分辨率的视频仅需121.52秒,大大低于原始模型的1504.5秒。
这种效率与质量的平衡在视觉效果上也得到了证实。通过对比生成的视频样本,可以看到DCM生成的视频在语义一致性、细节丰富度和整体质量上都表现出色,大大优于其他快速生成方法如LCM和PCM。
研究团队还进行了用户研究,让评估者对不同方法生成的视频进行偏好评分。结果显示,82.67%的评估者更喜欢DCM生成的视频而非LCM生成的视频,77.33%的评估者更喜欢DCM生成的视频而非PCM生成的视频。这进一步证明了DCM在主观视觉质量上的优越性。
此外,研究团队还进行了详细的消融实验,分别验证了优化解耦、参数高效双专家蒸馏、时间一致性损失以及GAN和特征匹配损失等各个组件的有效性。结果表明,每个组件都对最终性能有积极贡献,其中优化解耦是最关键的因素。
**六、总结与展望:视频生成的新时代**
这项研究通过识别并解决一致性模型蒸馏过程中的关键冲突,成功实现了高效高质量的视频生成。研究团队提出的双专家一致性模型(DCM)通过将语义布局和细节精修任务分离,有效缓解了优化冲突问题,同时通过参数高效的实现方式保持了计算成本的合理性。
对普通用户来说,这项技术意味着未来的AI视频生成工具将能够更快速地响应创意需求,同时保持高质量的输出。想象一下,你只需输入一段文字描述,几秒钟内就能获得一段高质量的视频内容,这将极大地改变内容创作的方式和效率。
当然,这项研究也存在一些局限性。研究团队指出,虽然他们的方法在4步采样时表现出色,但进一步减少步数(如降至2步)时仍面临挑战,这可能与训练数据和迭代次数有关。这也指明了未来研究的方向:如何在更少的步数下保持高质量的视频生成。
总的来说,这项研究为高效高质量的视频生成提供了一个有效的解决方案,展示了专家分工在人工智能模型中的价值,也为未来的研究指明了方向。有兴趣深入了解的读者可以通过GitHub(https://github.com/Vchitect/DCM)访问研究团队公开的代码和模型。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

北航大学团队推出Easy Dataset:让普通人也能制作AI训练数据的神奇工具
北航团队推出Easy Dataset框架,通过直观的图形界面和角色驱动的生成方法,让普通用户能够轻松将各种格式文档转换为高质量的AI训练数据。该工具集成了智能文档解析、混合分块策略和个性化问答生成功能,在金融领域实验中显著提升了AI模型的专业表现,同时保持通用能力。项目已开源并获得超过9000颗GitHub星标。

网络安全AI助手:让电脑漏洞危险等级一秒识别的RoBERTa智能系统
卢森堡计算机事件响应中心开发的VLAI系统,基于RoBERTa模型,能够通过阅读漏洞描述自动判断危险等级。该系统在60万个真实漏洞数据上训练,准确率达82.8%,已集成到实际安全服务中。研究采用开源方式,为网络安全专家提供快速漏洞风险评估工具,有效解决了官方评分发布前的安全决策难题。

人工智能评判官:xVerify如何解决复杂推理模型的评估难题
中国电信研究院等机构联合开发的xVerify系统,专门解决复杂AI推理模型的评估难题。该系统能够准确判断包含多步推理过程的AI输出,在准确率和效率方面均超越现有方法,为AI评估领域提供了重要突破。

只需输入音频就能生成说话人视频?昆仑集团推出的Skywork R1V让AI同时看懂图片和推理数学
昆仑公司Skywork AI团队开发的Skywork R1V模型,成功将文本推理能力扩展到视觉领域。该模型仅用380亿参数就实现了与大型闭源模型相媲美的多模态推理性能,在MMMU测试中达到69.0分,在MathVista获得67.5分,同时保持了优秀的文本推理能力。研究团队采用高效的多模态迁移、混合优化框架和自适应推理链蒸馏三项核心技术,成功实现了视觉理解与逻辑推理的完美结合,并将所有代码和权重完全开源。

北航大学团队推出Easy Dataset:让普通人也能制作AI训练数据的神奇工具

网络安全AI助手:让电脑漏洞危险等级一秒识别的RoBERTa智能系统

人工智能评判官:xVerify如何解决复杂推理模型的评估难题

只需输入音频就能生成说话人视频?昆仑集团推出的Skywork R1V让AI同时看懂图片和推理数学
