 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
进击的多模态推理:浙大&复旦联合研究团队揭秘从优化冷启动到分阶段强化学习的全新训练范式
在人工智能领域,多模态大语言模型(MLLM)的推理能力一直是研究热点。近日,由浙江大学、复旦大学、苏州大学和上海人工智能实验室等机构组成的研究团队在《arXiv:2506.04207v1》(2025年6月4日发布)上分享了他们的最新研究成果——ReVisual-R1,这一创新性的开源模型在复杂推理任务上取得了令人瞩目的进展。
想象一下,如果人工智能能够像侦探一样,不仅能看懂眼前的图像,还能基于这些视觉信息进行深入的推理和解题。这正是这项研究所追求的目标。研究团队的主要贡献者包括浙江大学的陈帅和复旦大学的郭悦(共同第一作者),以及上海人工智能实验室的曲晓晔和香港中文大学的程宇(共同通讯作者)等多位研究者。
这项研究的核心灵感来自于纯文本模型DeepSeek-R1在复杂推理任务中展现的卓越能力。许多研究者试图将类似的技术直接应用到多模态模型中,却收效甚微。为什么会这样?这就像是试图教一个人同时学会看图和解数学题,直接照搬教数学的方法常常不奏效。
研究团队并没有孤立地看待多模态强化学习问题,而是深入研究了整个训练流程,发现了三个关键现象:首先,良好的冷启动初始化对增强模型推理能力至关重要;其次,标准的GRPO算法在多模态强化学习中存在梯度停滞问题;最后,在多模态强化学习阶段后进行的纯文本强化学习可以进一步增强多模态推理能力。
基于这些发现,研究团队开发了ReVisual-R1模型,并在MathVerse、MathVision、WeMath、LogicVista、DynaMath等多个基准测试中取得了开源7B模型中的最佳表现,甚至在AIME2024和AIME2025等极具挑战性的测试中也展现出色。
一、冷启动初始化:文本推理的重要基础
研究团队的第一个重要发现堪称是一个意外之喜。想象你正在教一个孩子解决数学应用题,你会发现,让他先掌握纯数学推理能力,再教他理解带图的应用题,效果往往比直接从图像应用题开始要好得多。
研究人员发现,仅仅使用精心挑选的纯文本数据进行冷启动训练,就能使模型在多模态推理任务上的表现超过许多现有的多模态推理模型,甚至不需要进行多模态强化学习。这就像是先教会孩子深入思考的能力,然后再教他如何将这种能力应用到具体问题上。
为了验证这一发现,研究团队收集了两个开源的冷启动多模态数据集(Vision-R1和R1-One-Vision)以及两个冷启动文本数据集(DeepMath和OpenR1-Math),并随机抽取了40,000个样本用于微调Qwen2.5-VL-7B-Instruct模型。结果表明,使用纯文本冷启动数据训练的模型在文本和多模态推理任务上都表现出显著的改进,而仅使用多模态数据集训练的模型在两种任务上的增益都有限。
研究团队进一步分析了100个样本,发现对文本提示的响应平均长度为8,207.76个词元,远超对多模态提示的821.48个词元。此外,Vision-R1的通过率为96.00%,而DeepMath仅为75.0%。这些发现表明,现有的多模态冷启动数据集可能缺乏足够的复杂性来激发模型的高级推理能力。
二、GRAMMAR数据集:多模态推理的新基础
基于对开源推理数据的可变性的深入理解,研究团队开发了GRAMMAR,这是一个新数据集,旨在增强多模态模型推理能力的泛化能力。GRAMMAR包含47k多样化的文本思维样本(带有明确的推理路径),31k复杂的纯文本示例,以及21k带有真实标注的多模态问题,适用于基于规则的强化学习。
构建GRAMMAR涉及多阶段的精心策划。研究团队首先收集了各种难度的开源推理数据,然后通过基于规则的过滤确保答案的可验证性,排除了证明问题和具有难以验证的真实答案的问题。随后,研究人员使用Qwen2.5-VL-7B-Instruct进行初步筛选,剔除过于简单或复杂的问题,再利用Qwen2.5-VL-32B-Instruct评估剩余样本,将它们分为十个难度级别。
为了最大化数据多样性并最小化冗余,研究团队使用NV-Embedding-V2对问题进行编码,应用HDBSCAN进行聚类,通过Qwen2.5-7B-Instruct为聚类分配主题,并在主题和难度层面上进行平衡抽样。这就像是为学生精心设计一套由浅入深、涵盖各种知识点的习题集,确保学习过程既全面又高效。
三、分阶段强化优化(SRO):多模态推理的三步培养法
研究团队基于数据调查和GRAMMAR数据集的精心策划,提出了分阶段强化优化(SRO)框架,旨在系统地培养MLLM中的稳健推理和多样能力。这个框架通过一系列独特的学习阶段来实现这一目标,每个阶段都针对特定的训练挑战,并利用GRAMMAR数据集的适当组件。
SRO的第一阶段是多模态强化学习(MRL),这个阶段对于使MLLM将文本概念与视觉信息联系起来并执行跨模态推理至关重要。研究团队采用GRPO作为核心RL算法,并集成了两个关键增强:优先级优势提炼(PAD)和高效长度奖励函数。
PAD是为了解决GRPO在复杂多模态设置中面临的"梯度停滞"问题。当处理稀疏二进制奖励时,这个问题尤为严重。如果生成的响应组得到统一的奖励(例如,全部正确或全部错误),则优势信号变为零,导致那些样本的策略梯度为零,从而停止学习。PAD通过战略性地集中更新最具信息量的样本(具有明显的非零优势信号)来优化训练过程。
高效长度奖励函数则用于控制生成响应的冗长程度。虽然复杂推理任务通常需要更长的输出,但过长的序列可能会适得其反。因此,研究团队引入了一个高效长度奖励来调节生成响应的冗长度。
SRO的第二阶段是纯文本强化学习(TRL)。研究团队发现,密集的MRL训练可能会无意中导致纯文本能力下降,这被定义为"文本能力衰减"。为了进一步提升模型的抽象推理能力,研究团队集成了TRL阶段,旨在实现稳健的语言流畅性和高级推理能力。
这种分阶段训练方法有效地平衡了感知接地和认知推理发展,就像是先教会学生识别视觉元素,然后再教他们如何将这些视觉信息与深入的文本推理相结合,最后再强化他们的文本表达能力,使整个推理过程更加流畅和准确。
四、优先级优势提炼(PAD):提升多模态强化学习效率
在多模态强化学习中,研究团队发现了一个显著的挑战——"梯度停滞"。这个现象指的是由于接近零的优势估计占主导地位而导致学习效率降低,特别是在处理稀疏二元奖励时尤为严重。
想象一下,如果你在教一个学生解题,但无法明确告诉他哪些方法是有效的、哪些是无效的(都给出相同的反馈),那么学生就无法调整自己的策略。这就是多模态模型在训练过程中面临的问题。
为了专门应对梯度停滞并提高GRPO的效率,研究团队引入了优先级优势提炼(PAD)。PAD通过战略性地集中每个批次中最具信息量的样本来优化训练过程,即那些表现出显著的非零优势信号的样本。
PAD机制的工作流程如下:首先,计算每个序列的绝对优势,代表其学习信号的大小;然后,形成一个"有效集",选择绝对优势落在指定信息范围内的序列;最后,从这个有效集中抽取样本形成一个提炼的小批次,抽样基于序列的绝对优势进行优先级排序。
温度参数控制抽样集中度,通常在训练过程中从1.0线性衰减到0.3,以从探索转向利用。这样,小批次就会被最具信息量的样本所丰富。
PAD直接通过双重机制对抗梯度停滞:首先,过滤掉停滞的样本;其次,使用剩余集合中具有信息量的非零优势优先进行更新。这种对学习过程的选择性优化确保了高效的计算资源分配。因此,PAD导致增强的训练稳定性、改进的学习效率,以及更有效地获取复杂推理技能,尤其是在具有稀疏或二进制奖励的挑战场景中。
五、ReVisual-R1:分阶段训练的实证成功
ReVisual-R1模型的训练遵循研究团队提出的三阶段方法,利用精心策划的数据集进行每个阶段的训练。冷启动阶段使用了大约40k纯文本条目,重点是建立基础语言理解;随后的多模态强化学习(MRL)阶段使用了来自GRAMMAR数据集的约26k多样化多模态条目,以发展跨模态推理;最后,基于文本的RL(TRL)阶段包含了约30k文本条目,旨在完善细微理解和生成能力。
研究团队在一套全面的基准测试上评估了ReVisual-R1,这些基准测试被选择来测试不同的推理技能。对于视觉数学推理,他们使用了MathVerse、MathVision、WeMath和DynaMath;更广泛的多模态推理使用MathVista和LogicVista进行评估;而挑战性文本数学推理的表现则在AIME24/25和MATH-500上测量;通用问答则使用GPQA进行测试。
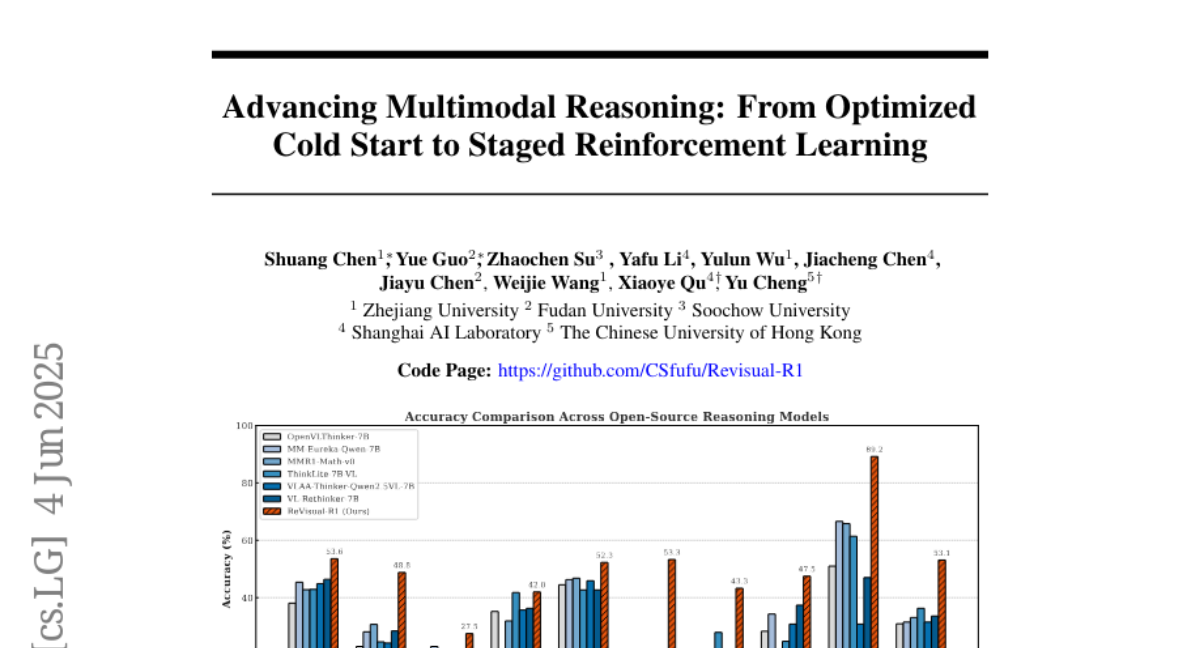
实验结果令人印象深刻。ReVisual-R1在多模态推理基准测试中取得了开源7B模型中的最佳表现,甚至优于一些商业大型MLLM。具体来说,ReVisual-R1实现了53.1%的令人印象深刻的平均分数,比之前的开源SOTA平均水平提高了+16.8个百分点。
ReVisual-R1在九个基准测试中获得了开源竞争者中的第一名:MathVerse(+5.4% ?)、MathVision(+13.9% ?)、DynaMath(+9.8% ?)、WeMath(+0.2% ?)、LogicVista(+9.6% ?)、AIME24(+44.6% ?)、AIME25(+15.4% ?)、GPQA(+10.1% ?)和MATH500(+23.4% ?)。最显著的增益在具有挑战性的AIME24、MATH500和AIME25基准测试中观察到,突显了ReVisual-R1的高级数学和推理能力。
值得注意的是,与闭源商业模型相比,ReVisual-R1也表现出高度竞争力。例如,其平均分数(53.1%)超过了OpenAI-GPT-4o(41.6%)。在特定的要求较高的基准测试(如MATH500)上,ReVisual-R1(89.2%)优于doubao-1.5-vision-pro-32k(85.2%)和OpenAI-GPT-4o(74.6%)。类似地,在AIME24和AIME25上,ReVisual-R1比这些商业产品表现出显著领先优势。
六、深入理解分阶段训练的重要性
研究团队进行了消融研究,以验证他们的分阶段强化优化(SRO)框架。他们测试了多模态RL(MRL)和基于文本的RL(TRL)阶段的不同组合,所有组合都建立在优化的文本中心冷启动(CS)之上。
实证证据强烈支持研究团队提出的CS + MRL + TRL(ReVisual-R1-MTR)序列,该序列在各类测试中持续产生最高的平均性能(49.6 Avg)。这个结果证实了研究团队的核心假设:首先进行专门建立强视觉接地的MRL阶段,然后进行TRL阶段来完善文本流畅性和抽象推理,对于开发卓越的多模态能力而不降低基础跨模态理解至关重要。
更详细的分析显示,仅CS + MRL模型(47.7 Avg),虽然在视觉密集型任务(如MathVista,71.9)上表现良好,但没有达到完整MTR序列的整体性能。这表明MRL虽然至关重要,但可能导致"文本能力衰减",而后续的TRL阶段有效地缓解了这一问题。
另一种SRO排序,CS + TRL + MRL(45.5 Avg),也比研究团队的MTR方法效果差。这一发现表明,在密集的文本精炼之前建立强视觉接地允许更协同的学习,其中TRL阶段可以增强已经连接跨模态的推理。
这些消融结果为MRL-then-TRL排序在SRO框架内提供了令人信服的理由。这种战略排序首先使模型多模态接地,然后锐化其语言和抽象推理能力,最终形成一个更全面的高性能MLLM。
七、PAD与高效长度奖励:改进模型训练的工具箱
研究团队还进行了消融研究,以评估优先级优势提炼(PAD)、其核心组件以及对关键超参数的敏感性。
为了评估PAD的影响,将其完整实现与GRPO-Baseline、GRPO-Filter-only和Random-Sampling策略进行了比较。结果表明,完整的PAD在数学推理基准测试上实现了卓越的性能,突显了其核心组件(有效样本过滤和优先级子采样)的重要性。
训练动态进一步证实了PAD的有效性,其采样策略产生更高的奖励准确性和更快的收敛,从而提高学习效率。在多模态RL中,研究团队还设计了一个高效长度奖励函数,该函数显著影响训练。
正则化模型保持稳定和更高的奖励准确性以及持续低熵。相比之下,基线模型遭受了准确性下降和熵急剧增加。此外,高效长度奖励有助于维持稳定的平均响应长度和低裁剪比率,不像基线模型那样表现出响应长度的不受控制增长和相应的更高裁剪比率。
总而言之,高效长度奖励对于稳定训练、防止准确性下降、保持低模型熵和控制冗长度至关重要。这些工具共同为多模态推理模型的训练提供了更加稳定和高效的方法。
八、结语:解锁多模态推理的未来
本研究引入了ReVisual-R1,这是一个7B开源MLLM,旨在解决培养复杂多模态推理的普遍挑战。通过系统地整合高难度纯文本冷启动阶段以建立基础推理能力,使用由我们新颖的优先级优势提炼(PAD)机制稳定的GRPO和基于规则的奖励(包括高效长度奖励)的多模态RL阶段,以及最终的TextRL精炼阶段,我们的结构化三阶段课程表明,周到的数据策略和有针对性的算法优化至关重要。
ReVisual-R1在一系列具有挑战性的视觉数学和推理基准测试中实现了开源7B模型中的最佳表现。这项工作强调,仔细的课程设计和算法增强,而不是仅仅依靠模型规模,可以解锁稳健的、自反思的多模态推理。
正如一位读者所评论的:"这就像是先教会孩子如何深入思考,再教他如何将这种思考能力应用到视觉问题上,最后再打磨他的表达能力,使整个推理过程更加流畅和准确。这种分阶段的教学方法,在人工智能训练中展现出了惊人的效果。"
这项研究不仅推动了多模态推理的边界,也为今后的研究提供了宝贵的方向,展示了如何通过精心设计的训练策略,使AI模型能够更好地理解和推理复杂的多模态信息。研究团队的代码已经在GitHub上开源,有兴趣的读者可以通过https://github.com/CSfufu/Revisual-R1访问并深入了解。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

北航大学团队推出Easy Dataset:让普通人也能制作AI训练数据的神奇工具
北航团队推出Easy Dataset框架,通过直观的图形界面和角色驱动的生成方法,让普通用户能够轻松将各种格式文档转换为高质量的AI训练数据。该工具集成了智能文档解析、混合分块策略和个性化问答生成功能,在金融领域实验中显著提升了AI模型的专业表现,同时保持通用能力。项目已开源并获得超过9000颗GitHub星标。

网络安全AI助手:让电脑漏洞危险等级一秒识别的RoBERTa智能系统
卢森堡计算机事件响应中心开发的VLAI系统,基于RoBERTa模型,能够通过阅读漏洞描述自动判断危险等级。该系统在60万个真实漏洞数据上训练,准确率达82.8%,已集成到实际安全服务中。研究采用开源方式,为网络安全专家提供快速漏洞风险评估工具,有效解决了官方评分发布前的安全决策难题。

人工智能评判官:xVerify如何解决复杂推理模型的评估难题
中国电信研究院等机构联合开发的xVerify系统,专门解决复杂AI推理模型的评估难题。该系统能够准确判断包含多步推理过程的AI输出,在准确率和效率方面均超越现有方法,为AI评估领域提供了重要突破。

只需输入音频就能生成说话人视频?昆仑集团推出的Skywork R1V让AI同时看懂图片和推理数学
昆仑公司Skywork AI团队开发的Skywork R1V模型,成功将文本推理能力扩展到视觉领域。该模型仅用380亿参数就实现了与大型闭源模型相媲美的多模态推理性能,在MMMU测试中达到69.0分,在MathVista获得67.5分,同时保持了优秀的文本推理能力。研究团队采用高效的多模态迁移、混合优化框架和自适应推理链蒸馏三项核心技术,成功实现了视觉理解与逻辑推理的完美结合,并将所有代码和权重完全开源。

北航大学团队推出Easy Dataset:让普通人也能制作AI训练数据的神奇工具

网络安全AI助手:让电脑漏洞危险等级一秒识别的RoBERTa智能系统

人工智能评判官:xVerify如何解决复杂推理模型的评估难题

只需输入音频就能生成说话人视频?昆仑集团推出的Skywork R1V让AI同时看懂图片和推理数学
