 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
新加坡科技大学揭示:小型AI语言模型的学习悖论——为什么过度训练反而让它们变笨?
这项由新加坡科技设计大学(SUTD)统计自然语言处理研究组的罗仁杰、李嘉西、黄晨和陆维团队完成的突破性研究,于2025年6月发表在arXiv预印本平台上。有兴趣深入了解的读者可以通过论文编号arXiv:2506.07712v1访问完整研究报告。这项研究首次系统性地揭示了一个令人意外的现象:当我们试图让小型AI语言模型(参数量在30亿以下)学习复杂的推理过程时,过度的训练反而会让它们的表现急剧下降。
想象一下,你在教一个小学生解复杂的数学题。一开始,你给他看了很多详细的解题步骤和思考过程,希望他能学会深入思考。但令人意外的是,这个孩子不仅没有变得更聪明,反而开始胡言乱语,写出一大堆冗长但错误的答案。这正是研究团队在小型AI模型身上发现的现象,他们将其命名为"长思维链退化"。
这个发现颠覆了我们之前的认知。在AI领域,长思维链训练就像是给机器"开小灶"——让它们学习像人类专家一样进行深入思考,包括反思、验证和分步解决问题。这种方法在大型AI模型上效果显著,就像给聪明的大学生提供高级课程一样,他们能够消化吸收并变得更优秀。然而,研究团队惊讶地发现,同样的"高级课程"对小型模型来说却是灾难性的。
在实验中,研究人员使用了多个不同规模的AI模型家族进行测试,包括Qwen2.5系列(从5亿到140亿参数)、LLaMA系列和Gemma系列。他们发现,当只用8000个长思维链样本训练最小的模型时,其性能竟然下降了75%。更令人震惊的是,即使用22万个样本进行大规模训练,某些特别小的模型仍然无法恢复到训练前的原始性能水平。这就像一个原本能考80分的学生,经过所谓的"强化训练"后,成绩反而跌到了20分,而且无论怎么补课都回不到原来的水平。
研究团队深入分析后发现,这种退化现象的根本原因在于"错误累积效应"。当小型模型试图模仿复杂的推理过程时,它们往往会生成冗长但充满错误的回答。就像一个小孩子试图模仿大人写长篇大论,结果写出了很多字,但其中充满了逻辑错误和重复内容。每一个小错误都会在后续步骤中被放大,最终导致完全错误的结论。
更有趣的是,研究团队还发现这种退化会"传染"到后续的强化学习阶段。如果一个模型在基础训练阶段就被"教坏了",那么即使用更先进的强化学习方法继续训练,它也很难恢复到正常水平。这就像一个养成了坏习惯的学生,即使后来接受了更好的教育,也很难完全纠正之前的错误思维模式。
然而,这项研究也带来了希望。研究团队发现,如果提供足够大规模的训练数据(比如12.8万个样本),大多数模型最终都能够恢复甚至超越原有性能。这个过程就像是让学生经历一个"先退后进"的学习曲线——刚开始接触复杂内容时会感到困惑和退步,但随着练习量的增加,最终能够掌握更高级的技能。
一、小型AI模型遭遇的"学习危机"
想象你正在观察一群不同年龄的学生学习高等数学。年龄较大的学生能够轻松掌握复杂的证明过程,而年幼的学生却在这些高难度内容面前显得手足无措。研究团队在AI模型世界中发现了类似的现象,他们称之为"长思维链退化"。
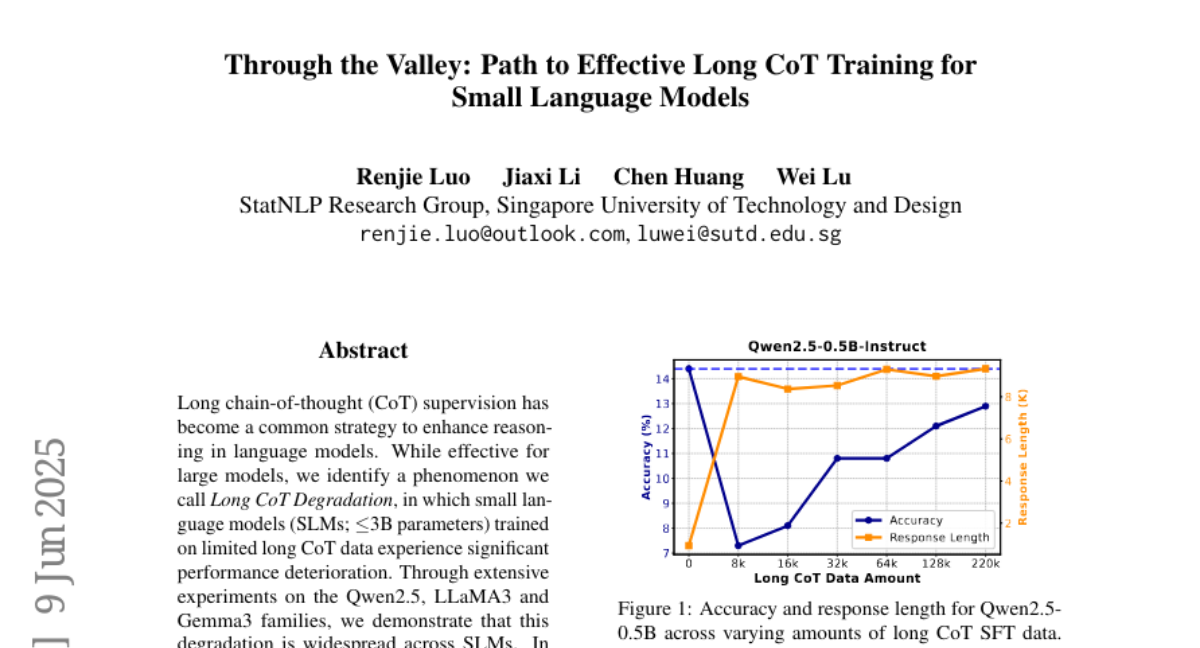
这个现象最初是在一个只有5亿参数的小型模型Qwen2.5-0.5B上被观察到的。研究人员用包含复杂推理过程的数学题目来训练这个模型,期望它能学会更深入的思考方式。然而,结果却令人大跌眼镜。当研究人员用8000个包含详细解题步骤的样本训练这个模型时,它的准确率从原来的14%急剧下降到了7%。更糟糕的是,虽然模型生成的回答变得更长了(从平均2000个词增加到8000个词),但这些冗长的回答大多是错误的。
这就像一个原本能简单明了回答问题的小学生,在接受了"高级训练"后,开始写出长篇大论的答案,但这些答案虽然看起来很有学问,实际上却是错误百出的胡言乱语。研究团队意识到,他们目睹了一个前所未见的学习悖论:更多的"高质量"训练反而让模型变得更糟。
为了验证这个发现的普遍性,研究人员扩大了实验范围。他们测试了九个不同的AI模型,覆盖了从5亿到140亿参数的广泛范围,包括当前最流行的Qwen、LLaMA和Gemma三个模型家族。实验使用了一个包含22.5万个数学问题的大型数据集,每个问题都配有经过验证的详细解题过程,这些解题过程是由顶级AI模型DeepSeek-R1生成的。
实验结果证实了这种退化现象的普遍性。几乎所有的小型模型都在接受长思维链训练后出现了性能下降。比如,Gemma3-1B模型的准确率从24%下降到了仅有6%,降幅达到了75%。即使是相对较大的Qwen2.5-14B模型,也从50%的准确率下降到45%。这个现象就像是一种"学习过敏反应"——模型对复杂的训练内容产生了负面反应,而不是预期的正面提升。
更令人担忧的是,这种退化现象还伴随着一个奇特的副作用:所有模型的回答都变得异常冗长。研究人员发现,经过长思维链训练的模型会产生大量重复、冗余的内容,就像一个学生为了凑字数而不断重复同样的句子。这种现象暗示着模型并没有真正理解复杂推理的精髓,而是简单地模仿了表面的形式特征。
然而,这个故事还有转折。研究团队发现,随着训练数据量的增加,大部分模型最终都能够从这种退化中恢复过来,甚至超越原有的性能水平。这个恢复过程就像是学生经历了一个"先苦后甜"的学习曲线。较大的模型恢复得更快更彻底,比如Qwen2.5-14B模型在训练数据达到1.6万个样本时就恢复并超越了原有性能,而Qwen2.5-1.5B模型则需要3.2万个样本才能略微超越基线。
最让人印象深刻的是,一些最小的模型表现出了惊人的"固执"特性。即使经过22万个样本的大规模训练,Qwen2.5-0.5B和Gemma-3-1B模型仍然无法恢复到训练前的原始性能水平。这就像某些学生一旦形成了错误的学习习惯,即使经过长期纠正也很难完全改变过来。这个发现揭示了AI模型能力的根本限制:当模型的"容量"不足以处理复杂信息时,强行灌输这些信息不仅无效,反而会造成伤害。
二、揭秘模型"变笨"的真相
为了理解为什么小型AI模型会出现这种反常的学习退化现象,研究团队就像医生诊断疾病一样,提出了两个核心假设,并通过精心设计的实验来验证这些假设。
第一个假设听起来有些讽刺:小型模型在接受长思维链训练时,首先学会的不是深度思考,而是"装腔作势"。就像一个小孩子模仿大人说话,先学会的是语调和手势,但并不真正理解内容的含义。研究团队认为,当小型模型接触到包含反思、验证和多步推理的训练样本时,它们会快速掌握这些表面特征,开始在回答中大量使用"让我重新检查一下"、"等等,我需要验证这个步骤"这样的反思性语言。
为了验证这个假设,研究人员设计了一个巧妙的检测方法。他们开发了一套"反思行为识别系统",就像给模型的回答做"行为分析"。这个系统结合了关键词检测(寻找"重新检查"、"重新思考"、"重新评估"等词汇)和AI辅助判断(使用GPT-4o-mini来识别隐含的反思行为)。
实验结果令人震惊。即使只用8000个长思维链样本进行训练,所有Qwen模型的"反思比例"都从不到5%急剧上升到了约75%。这就像一群学生在一夜之间都学会了说"让我再想想"这样的话,但他们并不真正知道如何深入思考。更有趣的是,研究人员发现,包含反思行为的回答平均比不包含反思的回答长2000个词左右,这种模式在所有训练规模下都保持一致。
这个发现解释了为什么模型的回答会变得如此冗长。模型快速学会了使用反思性语言作为"填充词",就像一个学生为了让作文看起来更有深度而反复使用"经过深入思考"这样的表述,但实际内容却并没有相应的深度增加。
第二个假设更加直观但同样重要:更长的回答意味着更多的犯错机会。这就像走一条更长的路到达目的地,虽然可能看到更多风景,但也更容易迷路。研究团队认为,当模型生成越来越长的推理过程时,每一个推理步骤都可能引入错误,而这些错误会在后续步骤中累积和放大,最终导致完全错误的结论。
为了验证这个假设,研究人员创造了一个"纯净"的测试环境——一个合成的算术基准测试。这个测试就像是专门为AI模型设计的数学练习册,每道题都是由5到15个基本算术运算组成的表达式,所有的数字都被限制在1到100之间,确保中间结果都是整数。这样做的目的是消除问题理解、背景知识等干扰因素,纯粹测试模型的计算能力和错误累积情况。
这个测试的设计非常巧妙。与现实世界中复杂的数学问题不同,这些算术题的每一步都有明确的对错标准,研究人员可以精确追踪错误是如何产生和传播的。就像在一个完全受控的实验室环境中观察化学反应一样,研究人员能够清晰地看到模型在每个计算步骤中的表现。
实验结果强有力地支持了第二个假设。大多数模型在接受长思维链训练后,在这个简单的算术测试上表现出了与真实数学问题类似的退化模式。例如,Qwen2.5-7B模型的算术准确率下降了30%,同时其平均输出长度从约600个词增加到3600个词。这个结果特别有说服力,因为算术运算本身并不复杂,模型的失败明显是由于生成过程中的错误累积造成的。
研究人员通过详细分析模型的错误回答发现了错误累积的具体机制。在用8000个样本训练的模型中,他们观察到模型经常会重复相同的计算错误,并且会用大量重复的短语(如"等等")来填充回答。更糟糕的是,即使模型试图提出"替代解决方案",这些方案往往包含相同的基础错误,导致错误在不同的解决路径中反复出现。
相比之下,用64000个样本训练的模型展现出了更加disciplined的推理行为。这些模型能够更有效地验证计算步骤,提出的替代方案也更有针对性和清晰度。这就像是经过充分练习的学生不仅能够避免基础错误,还能够在发现错误时进行有效的自我纠正。
这两个假设共同解释了长思维链退化现象的完整机制:小型模型首先快速学会了复杂推理的表面形式(如反思性语言),这导致它们生成更长的回答,而更长的回答又为错误的累积和传播提供了更多机会,最终导致整体性能的下降。这个机制就像一个恶性循环:越是试图显得"聪明",就越容易犯错,而越多的错误又进一步损害了真正的推理能力。
三、训练数据规模的"拯救力量"
虽然长思维链退化现象看起来令人沮丧,但研究团队的深入分析揭示了一个充满希望的发现:这种退化并非不可逆转的。通过仔细观察不同规模训练数据的效果,研究人员发现了一个类似于"药物剂量效应"的有趣现象——适当的"药量"不仅能治愈"疾病",还能让"患者"变得比以前更强壮。
研究团队发现,模型的恢复能力与其"体型"(参数规模)密切相关。较大的模型就像体质更好的人,能够更快地从训练冲击中恢复过来。例如,拥有140亿参数的Qwen2.5-14B模型就像一个身强力壮的成年人,仅仅用1.6万个训练样本就能完全恢复并超越原有性能。相比之下,只有15亿参数的Qwen2.5-1.5B模型就像一个体弱的孩子,需要3.2万个样本才能勉强恢复到原来的水平。
更令人印象深刻的是模型在恢复过程中展现出的"智慧成长"。研究人员观察到,随着训练数据的增加,模型不仅准确率在提升,回答的长度也在逐渐缩短。这就像一个最初啰嗦冗长的学生,经过充分的练习后,学会了用更少但更精确的话语表达复杂的想法。这种现象被研究团队称为"token效率的提升",即模型学会了用更少的文字产生更准确的答案。
以Qwen2.5-14B模型为例,当训练数据达到3.2万个样本时,它能够在准确率达到66%的同时,将平均回答长度控制在4000个词以内。而同样的训练量对于7B模型来说,虽然能达到53%的准确率,但平均回答长度却需要5000个词。这个对比清楚地表明,较大的模型不仅能够产生更准确的答案,还能以更简洁的方式表达这些答案。
然而,并非所有模型都能完全从退化中恢复。研究团队发现了一些"顽固分子"——即使经过22万个样本的大规模训练,某些最小的模型仍然无法回到训练前的性能水平。Qwen2.5-0.5B模型就是一个典型例子,它的最终准确率从原来的14%只能恢复到11%,而Gemma-3-1B模型则从24%只能恢复到15%。这个现象就像某些学习能力有限的学生,无论怎么补课都很难达到期望的水平,暗示着模型容量的根本限制。
这种"容量限制"的发现具有重要的实践意义。它告诉我们,并不是所有的模型都适合接受复杂的推理训练,就像不是所有的学生都适合跳级学习高难度课程一样。对于那些参数量极小的模型,强行进行长思维链训练可能弊大于利。
更有趣的是,研究团队在观察恢复过程中发现了模型学习的"阶段性特征"。在训练初期(8000-16000个样本),几乎所有模型都会经历一个"阵痛期",表现出明显的性能下降。这个阶段就像学生刚接触新知识时的困惑和挫折期。随后,在中期阶段(32000-64000个样本),大部分模型开始显示出恢复的迹象,就像学生开始理解新概念的精髓。最后,在后期阶段(128000个样本以上),优秀的模型不仅能完全恢复,还能达到前所未有的高度。
这个发现对AI开发者具有重要的指导意义。它表明,如果选择对小型模型进行长思维链训练,必须要有充分的耐心和足够的训练数据。半途而废(比如只用几千个样本进行训练)不仅无法获得预期的改进,反而会让模型变得更糟。这就像教一个孩子学游泳,如果只是让他在浅水区扑腾几下就结束训练,他不仅学不会游泳,反而可能对水产生恐惧。
研究团队还发现了一个有趣的"共同进化"现象:在同一个模型家族中,较大的模型总是能够在相对较少的训练数据下实现恢复和超越,而较小的模型则需要更多的数据和时间。这种现象类似于同一个家庭中年龄较大的孩子总是能更快地掌握新技能,而年幼的孩子需要更多的指导和练习。
四、强化学习阶段的"连锁反应"
在发现了长思维链训练对小型模型的复杂影响后,研究团队面临了一个更深层的问题:这种影响是否会延续到后续的学习阶段?在AI模型的训练过程中,基础训练(SFT)通常只是第一步,之后还会有强化学习(RL)阶段,这就像学生在掌握基础知识后还需要参加实战练习一样。
为了回答这个问题,研究团队设计了一系列"接力实验"。他们选择了三个具有代表性的小型模型——Qwen2.5系列的0.5B、1.5B和3B版本,就像选择了三个不同能力等级的学生参加同一个进阶课程。这些模型首先接受不同规模的长思维链训练(从不训练到12.8万个样本),然后统一进入强化学习阶段。
强化学习的设置就像一个严格的考试系统。模型需要解决数学问题,如果答案完全正确就得1分,答案错误就得0分,没有部分分数。这种"要么全对要么全错"的评分方式虽然看起来严苛,但却能够精确地测量模型的真实能力,避免了"看起来有道理但实际错误"的答案获得不应得的分数。
实验结果揭示了一个令人担忧的"负债传递"现象。那些在基础训练阶段表现糟糕的模型,在强化学习阶段也很难翻身。就像一个在基础数学课上养成了错误习惯的学生,即使后来参加了更好的辅导班,也很难完全纠正之前的错误思维模式。
具体来说,那些仅用8000个长思维链样本训练的模型,在整个强化学习过程中始终表现出较低的准确率和较长的回答长度。这种"双重劣势"就像一个恶性循环:模型不仅答错题目,还用冗长的错误推理来"证明"自己的错误答案。更糟糕的是,这种性能差距在强化学习过程中不仅没有缩小,反而有进一步扩大的趋势。
然而,研究也带来了一些积极的发现。那些接受了充分长思维链训练(12.8万个样本)的模型在强化学习阶段展现出了惊人的"后发优势"。这些模型不仅在强化学习过程中表现出更快的改进速度,还能达到更高的性能上限。最令人印象深刻的是,即使是最小的0.5B模型,在经过充分的基础训练后,也能在强化学习阶段实现显著的性能提升。
以0.5B模型为例,虽然经过12.8万样本的长思维链训练后,它的即时性能低于未经训练的基线模型,但在强化学习阶段,它展现出了惊人的学习能力。经过完整的强化学习训练后,这个模型不仅弥补了之前的性能差距,还实现了相对于基线13%的性能提升,相对于训练前状态60%的巨大飞跃。这就像一个在基础阶段暂时落后的学生,通过持续努力最终在期末考试中取得了优异成绩。
研究团队还观察到了一个有趣的"效率悖论"现象。在强化学习的早期阶段,那些经过充分长思维链训练的模型会迅速缩短其回答长度,同时提高准确率。这种现象就像一个啰嗦的学生突然学会了言简意赅地表达要点,既提高了效率又提升了准确性。相比之下,那些没有经过长思维链训练的基线模型在强化学习过程中只能实现很小的改进,就像缺乏基础的学生很难在高级课程中取得突破。
这些发现揭示了AI模型训练中的一个重要原理:基础训练的质量决定了后续学习的上限。虽然充分的长思维链训练可能在短期内造成性能下降,但它为模型建立了更强的"学习基础设施",使得模型能够在后续的强化学习中实现更大的突破。这就像为房子打地基一样,虽然过程费时费力,甚至可能暂时看不到明显效果,但坚实的地基是建造高楼大厦的必要条件。
研究团队的发现对实际应用具有重要启示。它表明,在评估长思维链训练的效果时,不能仅仅看基础训练结束后的即时表现,还要考虑模型在后续强化学习阶段的潜力。一个在基础训练后暂时表现不佳的模型,可能蕴含着在强化学习阶段实现跨越式发展的巨大潜力。
五、为AI开发者指明方向
经过大量实验和深入分析,研究团队为AI开发者描绘了一幅关于小型模型训练的全新图景。这幅图景既有令人担忧的陷阱,也有充满希望的机遇,就像一张标明了危险区域和安全路径的航海图。
首先,研究明确指出了一个重要的"危险区域":对小型模型进行小规模的长思维链训练。这就像用成人的学习材料去教小学生,不仅不会让他们变得更聪明,反而会让他们感到困惑和挫败。当开发者只使用几千个复杂推理样本来训练小型模型时,模型很可能会陷入"装腔作势"的陷阱——表面上学会了使用复杂的推理语言,但实际的推理能力却大幅下降。
这个发现对整个AI开发社区具有重要意义。在过去,很多研究者认为即使是少量的高质量训练数据也能显著改善模型性能,但这项研究表明,对于小型模型来说,"少量"的复杂训练可能弊大于利。这就像给营养不良的孩子吃大补药,不仅不能改善健康状况,反而可能造成消化不良。
然而,研究也为开发者指出了一条"黄金路径":大规模的长思维链训练配合后续的强化学习。虽然这条路径在初期可能充满挑战,需要投入更多的计算资源和时间,但最终能够获得远超预期的回报。研究表明,当训练数据达到12.8万个样本的规模时,即使是最小的模型也能在完整的训练流水线后实现显著的性能提升。
这个发现重新定义了我们对AI模型训练"性价比"的理解。传统观点认为,小型模型的优势在于训练成本低、部署方便,但复杂推理能力有限。然而,这项研究表明,通过适当的训练策略,小型模型也能获得令人印象深刻的推理能力,从而在保持低成本优势的同时大幅提升智能水平。
研究团队特别强调了训练过程中的"耐心"的重要性。他们发现,模型的学习过程类似于人类掌握复杂技能的过程,需要经历一个"先退后进"的阶段。在这个阶段,模型的表现可能会暂时下降,但这是掌握更高级能力的必经之路。开发者需要有足够的耐心和信心度过这个"黑暗期",而不是在看到暂时的性能下降后就放弃训练。
另一个重要发现是模型规模与训练策略之间的匹配关系。研究表明,不同规模的模型需要不同的训练策略,就像不同年龄的学生需要不同的教学方法。对于参数量在10亿以下的超小型模型,开发者需要特别谨慎,因为这些模型可能永远无法从长思维链退化中完全恢复。对于这类模型,传统的短链推理训练可能是更好的选择。
对于参数量在10亿到30亿之间的小型模型,研究建议采用"大规模训练+强化学习"的组合策略。虽然这种策略的初期投入较高,但能够获得最佳的长期回报。对于30亿参数以上的较大模型,它们展现出了更好的训练弹性,即使在相对较小的训练规模下也能获得不错的改进效果。
研究还揭示了一个有趣的"投资回报递增"现象。随着训练数据规模的增加,模型性能的改进幅度不是线性增长,而是呈现加速增长的趋势。这意味着,对长思维链训练的投入存在一个"临界点",超过这个点后,每增加一份投入都能获得超比例的回报。这个发现鼓励开发者在资源允许的情况下尽可能扩大训练规模,而不是满足于小规模的"试水"训练。
最后,研究团队强调了评估方法的重要性。他们建议开发者在评估长思维链训练效果时,不应该仅仅关注基础训练结束后的即时表现,而应该将整个训练流水线(包括强化学习阶段)的最终效果作为评判标准。这就像评估一个学生的潜力时,不应该只看他在基础课程中的表现,而应该观察他在整个学习过程中的成长轨迹。
研究团队希望这些发现能够帮助AI开发者做出更明智的决策,避免在小型模型训练中走弯路。他们的工作不仅揭示了长思维链训练中存在的陷阱,更重要的是为开发者指明了获得成功的正确路径。这就像为探险者提供了一张详细的地图,既标明了危险的沼泽地,也指出了通往宝藏的安全道路。
说到底,这项研究告诉我们一个简单而深刻的道理:在AI模型的训练中,没有免费的午餐,但也没有不可能完成的任务。关键在于选择正确的策略,投入足够的资源,并且保持足够的耐心。就像培养一个孩子成才一样,虽然过程可能充满挑战,但最终的收获会让所有的努力都变得值得。
这项研究的意义远不止于技术层面。它提醒我们,在追求AI技术进步的过程中,需要更加细致地理解不同规模模型的特性和限制,而不是简单地假设"大模型有效的方法对小模型也同样有效"。只有通过这样深入细致的研究,我们才能真正释放小型AI模型的潜力,让AI技术更好地服务于现实世界的各种应用场景。
对于那些希望深入了解这项研究技术细节的读者,建议查阅发表在arXiv平台上的完整论文,论文编号为arXiv:2506.07712v1。研究团队在论文中提供了详细的实验设计、数据分析和补充材料,这些内容对于AI研究者和开发者来说都具有重要的参考价值。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

利用大语言模型探索科学创新前沿:南洋理工大学团队开发检测学术新颖性的突破性方法
这项研究利用大语言模型解决科学新颖性检测难题,南洋理工大学团队创新性地构建了闭合领域数据集并提出知识蒸馏框架,训练轻量级检索器捕捉想法层面相似性而非表面文本相似性。实验表明,该方法在市场营销和NLP领域显著优于现有技术,为加速科学创新提供了有力工具。

un?CLIP:通过反转unCLIP来提升CLIP模型的视觉细节捕捉能力
un?CLIP是一项创新研究,通过巧妙反转unCLIP生成模型来增强CLIP的视觉细节捕捉能力。中国科学院研究团队发现,虽然CLIP在全局图像理解方面表现出色,但在捕捉细节时存在不足。他们的方法利用unCLIP生成模型的视觉细节表示能力,同时保持与CLIP原始文本编码器的语义对齐。实验结果表明,un?CLIP在MMVP-VLM基准、开放词汇语义分割和视觉中心的多模态任务上显著优于原始CLIP和现有改进方法,为视觉-语言模型的发展提供了新思路。

角色扮演能力大考验:里尔大学研究团队开发的大语言模型角色扮演评估新标准
这项研究介绍了RPEval,一个专为评估大语言模型角色扮演能力而设计的新基准。研究团队从法国里尔大学开发的这一工具专注于四个关键维度:情感理解、决策制定、道德对齐和角色一致性,通过单轮交互实现全自动评估。研究结果显示Gemini-1.5-Pro在总体表现上领先,而GPT-4o虽在决策方面表现出色,但在角色一致性上存在明显不足。这一基准为研究人员提供了一个可靠、可重复的方法来评估和改进大语言模型的角色扮演能力。

LegalSearchLM:北大团队打造突破性法律案例检索新方法,将案例检索重新定义为法律要素生成
这篇论文介绍了LegalSearchLM,一种创新的法律案例检索方法,将检索任务重新定义为法律要素生成。研究团队构建了LEGAR BENCH数据集,涵盖411种犯罪类型和120万案例,并开发了能直接生成关键法律要素的检索模型。实验表明,该模型在准确率上超越传统方法6-20%,且在未见犯罪类型上展现出强大泛化能力。这一突破为法律专业人士提供了更高效、精准的案例检索工具。

利用大语言模型探索科学创新前沿:南洋理工大学团队开发检测学术新颖性的突破性方法

un?CLIP:通过反转unCLIP来提升CLIP模型的视觉细节捕捉能力

角色扮演能力大考验:里尔大学研究团队开发的大语言模型角色扮演评估新标准

LegalSearchLM:北大团队打造突破性法律案例检索新方法,将案例检索重新定义为法律要素生成
