 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
材料科学也有"翻译问题"?韩国科学家发明智能分词法让AI更懂材料学
这项由韩国科学院人工智能系的吴咽琳(Yerim Oh)团队领导的研究发表于2025年6月9日的计算语言学会议(EMNLP),论文题目为《Incorporating Domain Knowledge into Materials Tokenization》。有兴趣深入了解的读者可以通过arXiv:2506.11115v1访问完整论文。
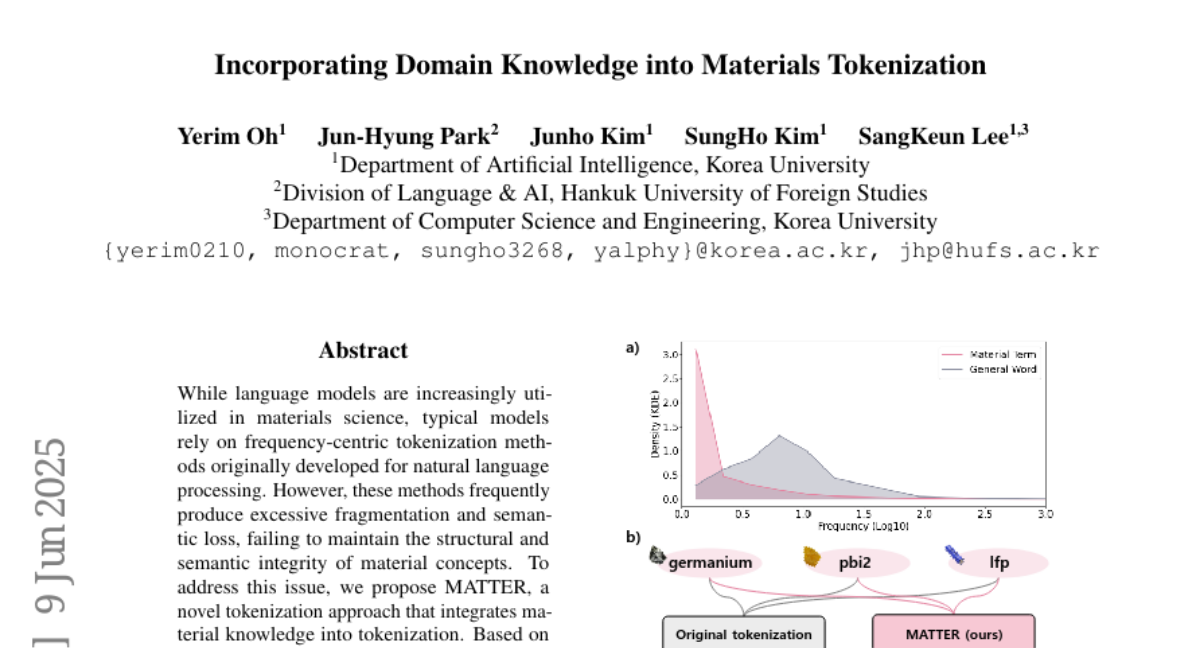
想象一下,你正在学习一门外语,但老师总是把重要的单词拆得七零八落。比如"germanium"(锗元素)被拆成了"german"(德国的)和"-ium"(后缀),这样你怎么可能理解这个词的真正含义?这正是目前人工智能在处理材料科学文献时面临的尴尬问题。
当我们让AI阅读材料科学论文时,就像让一个外国人用错误的字典来理解中文一样。AI需要先把文字切分成小块(就像把句子拆成词语),这个过程叫做"分词"。但现有的分词方法原本是为普通文章设计的,它们只认识高频常见词,对材料科学中那些专业而重要的术语却视而不见。结果就是,"锗"这个重要的化学元素被AI理解成了"德国的某种东西",完全南辕北辙。
韩国科学院的研究团队注意到了这个让人头疼的问题。他们发现,在材料科学文献中,真正重要的材料概念—比如化学元素名称、分子式、材料名称—往往出现频率很低,而一些无关紧要的常用词却占据了AI词汇表的大部分位置。这就像一本专业词典里,"的"、"了"、"吗"占了一半篇幅,而"硅"、"钛"、"碳纳米管"这些关键词却被挤到了角落里。
为了解决这个问题,研究团队开发了一套名为MATTER的智能分词系统。这套系统就像一个既懂语言学又懂材料学的专业翻译,它能够识别出哪些词汇对材料科学真正重要,然后在分词时特别保护这些词汇,确保它们不被胡乱拆解。
MATTER系统的工作原理可以用"智能图书管理员"来比喻。普通的图书管理员只会按照书的厚薄来分类,厚书放一边,薄书放另一边。但MATTER就像一个既懂图书分类学又是各学科专家的超级管理员,它能识别出哪些书虽然薄但很重要(比如爱因斯坦的相对论),哪些书虽然厚但只是充数(比如某些冗长的小说),然后给重要的书更好的位置和保护。
这个系统的核心是一个叫做MatDetector的"材料概念侦探"。研究团队训练了这个侦探,让它能够从浩如烟海的科学文献中精准识别出材料科学相关的概念。他们首先从PubChem数据库(一个巨大的化学物质信息库)中提取了8万个材料相关概念,包括化学名称、IUPAC标准名称、同义词和分子式。然后,他们用这些概念作为关键词,从学术搜索引擎Semantic Scholar中收集了大约4.2万篇科学论文。
但收集数据只是第一步,更重要的是要训练MatDetector学会识别这些概念。研究团队深知现实世界的材料文献往往充满了各种错误和不规范—OCR扫描错误、格式不一致、特殊符号问题等等。为了让MatDetector更加健壮,他们特意制造了各种"噪音"数据来训练它,就像让一个侦探在嘈杂的环境中练习辨音一样。
经过训练的MatDetector不仅能识别材料概念,还能给每个概念打分,表示它与材料科学的相关程度。分数越高,说明这个概念对材料科学越重要。比如"germanium"会得到很高的分数,而"german"则会得到很低的分数。
有了这个评分系统,MATTER就能在分词时做出明智的决策。传统的分词方法就像一个只会数钱的商人,哪个词出现次数多就优先保护哪个。但MATTER更像一个既会数钱又懂行情的投资专家,它会综合考虑词汇的出现频率和专业重要性。即使某个材料概念出现次数不多,但只要它对材料科学很重要,MATTER就会想办法保护它不被拆散。
具体来说,MATTER使用了一个巧妙的重新排序策略。它会根据MatDetector的评分来调整词汇的"虚拟频率"。对于重要的材料概念,即使它们在文章中出现次数不多,MATTER也会人为地提高它们的重要性权重,确保在构建词汇表时这些概念能够获得完整保留。这个过程就像给重要但不太知名的演员分配更好的戏份和更显眼的位置一样。
为了验证MATTER的效果,研究团队进行了大量的实验。他们比较了MATTER与其他几种主流分词方法的表现,包括广泛使用的BPE(字节对编码)、WordPiece、以及较新的SAGE和PickyBPE方法。实验覆盖了材料科学领域的多种任务,既有文本生成任务,也有分类任务。
在文本生成任务中,MATTER表现出了明显的优势。这些任务包括命名实体识别(识别文本中的材料名称)、关系分类(理解不同材料概念之间的关系)、事件论元抽取(提取材料合成过程中的关键信息)等等。平均而言,MATTER在这些任务上比其他方法提高了4%的性能。虽然4%听起来不多,但在AI领域,这已经是相当可观的提升了,就像百米赛跑中提高0.1秒一样珍贵。
在分类任务中,MATTER同样表现不俗,平均提升了2%的性能。这些任务包括对材料科学论文段落的分类、对具体材料属性的识别等等。更重要的是,研究团队通过严格的统计检验证实,这些提升不是偶然现象,而是MATTER方法带来的真实改进。
研究团队还进行了一个特别有趣的实验—材料概念的形态学分割。简单来说,就是测试MATTER是否真的能把材料概念切分得更合理。他们使用了SIGMORPHON 2022形态学分割数据集中的材料相关部分,发现MATTER的分割准确率比其他方法平均提高了18.6%。这意味着MATTER确实学会了以更符合材料科学逻辑的方式来理解和分割概念。
除了性能提升,研究团队还分析了MATTER构建的词汇表的质量。他们发现,MATTER的词汇表中包含了更多完整的材料概念,而且这些概念在词汇表中占据了更重要的位置。通过词嵌入分析(一种衡量词汇语义相似性的技术),他们发现MATTER学到的材料概念表示更加准确和合理。比如,"germanium"的最相似词汇不再是无关的"german"或"segregation",而是化学上相关的"dithiocarbamate"(二硫代氨基甲酸盐)和"ammonium"(铵)等概念。
更令人印象深刻的是,研究团队发现MATTER学到的词嵌入捕捉了丰富的化学知识。比如,PbI2(碘化铅)和PbF2(氟化铅)在MATTER的表示中非常相似,这是合理的,因为它们都属于铅卤化物家族。类似地,LFP(磷酸铁锂)和ZrF7(氟化锆)也表现出相似性,因为它们在能源储存和传感应用中都有重要作用。这表明MATTER不仅仅是在表面上保护材料概念,而是真正理解了它们的化学含义和关系。
研究团队还验证了MatDetector相对于现有工具的优势。他们将MatDetector与广泛使用的ChemDataExtractor进行了比较。ChemDataExtractor是材料科学界常用的概念提取工具,但它最初是为生物医学文献训练的,在材料科学文献上的表现不够理想。实验结果显示,MatDetector的准确率、召回率和F1分数都明显优于ChemDataExtractor。具体来说,MatDetector的F1分数达到了63%,而ChemDataExtractor只有27%,提升幅度超过一倍。
为了进一步验证MATTER的通用性,研究团队还在材料科学问答任务上进行了测试。他们使用了MaScQA数据集,这是一个专门针对材料科学知识问答的基准。无论是使用解码器模型(如Llama)还是编码器-解码器模型(如基于BERT的架构),MATTER都取得了最佳性能。这说明MATTER的改进不局限于特定的模型架构或任务类型。
在深入分析中,研究团队发现MATTER的成功主要来源于三个方面。首先,MatDetector的准确性至关重要。当他们用性能较差的ChemDataExtractor替代MatDetector时,虽然仍有改进,但幅度明显减小。这说明准确识别材料概念是整个系统的基础。其次,权重参数λ的选择也很重要。研究团队发现λ=1是最优选择,这时能够在保护材料概念和维持语言模型整体性能之间取得最佳平衡。最后,材料领域知识的引入本身就是关键创新,即使用较简单的方法引入这种知识,也能带来显著改进。
研究团队对MATTER方法也有诚实的反思。他们指出,这种方法仍需要手动调节超参数λ,虽然在实验中λ=1表现最佳,但对于不同的语料库或子领域,最优值可能有所不同。此外,MATTER依赖于监督学习的信号(即需要标注数据来训练MatDetector),这在扩展到更大规模或更多样化的语料库时可能带来挑战。
尽管存在这些限制,MATTER代表了一个重要的研究方向。它首次系统性地将领域知识引入到分词过程中,为科学文本处理开辟了新的道路。研究结果表明,简单地将通用NLP方法应用到科学领域是不够的,需要针对特定领域的特点进行定制和优化。
从更广阔的视角来看,这项研究揭示了一个重要问题:随着AI在各个专业领域的应用越来越深入,我们需要更多领域特定的技术和方法。材料科学只是一个开始,类似的问题可能也存在于化学、物理、生物学、医学等其他科学领域。每个领域都有自己独特的词汇体系和概念结构,都需要专门的处理方法。
MATTER的成功也为未来的研究指明了方向。研究团队建议,未来可以探索自动化的超参数选择方法,减少人工调节的需要。同时,可以研究如何将这种领域知识引入方法扩展到其他科学领域,或者开发更通用的框架来处理不同领域的特殊需求。
此外,随着大型语言模型在科学研究中应用的不断扩展,如何让这些模型更好地理解和处理科学概念将变得越来越重要。MATTER提供的思路—结合领域专业知识来改进基础NLP技术—很可能会成为一个重要的研究范式。
说到底,MATTER解决的不仅仅是一个技术问题,更是如何让AI真正理解人类专业知识的问题。就像培养一个优秀的学生,不能只教他们通用的学习方法,还要针对不同学科的特点进行专门指导。MATTER为材料科学领域的AI应用提供了这样的专门指导,让AI能够更准确地理解和处理材料科学文献。
这项研究的意义远不止于技术层面的改进。它为加速材料发现和开发提供了新的工具。在当今快速发展的科技时代,新材料的研发对于解决能源、环境、健康等全球性挑战至关重要。MATTER这样的工具能够帮助研究人员更高效地从海量文献中提取有用信息,发现新的研究机会,加速科学发现的进程。
归根结底,这项研究告诉我们,让AI真正服务于科学研究,需要的不仅仅是更强大的计算能力或更大的数据集,更需要深入理解不同学科的特点和需求。只有将技术创新与领域专业知识有机结合,我们才能让AI成为科学研究的真正助手。有兴趣深入了解这项研究细节的读者,可以通过论文编号arXiv:2506.11115v1查阅完整的研究论文。
Q&A
Q1:MATTER是什么?它能做什么? A:MATTER是韩国科学院开发的智能分词系统,专门用于处理材料科学文献。它的核心能力是识别和保护材料科学中的重要概念(如化学元素、分子式等),防止AI在理解文本时把这些重要概念错误拆分。就像给AI配了一副专业眼镜,让它能正确识别材料科学术语。
Q2:为什么需要专门的材料科学分词方法? A:因为传统的AI分词方法只认识常用词汇,对材料科学中重要但不常见的专业术语视而不见。比如把"germanium"(锗元素)错误拆分成"german"(德国的)和"-ium",完全曲解了原意。这就像用普通字典去理解专业术语,必然会出错。
Q3:MATTER的效果如何?有什么实际应用价值? A:实验显示MATTER比现有方法平均提升4%的文本生成性能和2%的分类性能。虽然数字看起来不大,但在AI领域这已经是显著改进。实际应用中,它能帮助研究人员更准确地从材料科学文献中提取信息,加速新材料的发现和开发过程。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

深度学习也能像人一样"看重点"?揭秘视觉AI如何学会聪明地观察世界
这项研究提出了"高效探测"方法,解决了掩码图像建模AI难以有效评估的问题。通过创新的多查询交叉注意力机制,该方法在减少90%参数的同时实现10倍速度提升,在七个基准测试中均超越传统方法。研究还发现注意力质量与分类性能的强相关性,生成可解释的注意力图谱,展现出优异的跨域适应性。团队承诺开源全部代码,推动技术普及应用。

伊利诺伊大学新突破:让机器像法官一样剖析复杂争议,不再简单判"真假"
伊利诺伊大学研究团队开发了CLAIMSPECT系统,通过层次化分解复杂争议、智能检索相关文献、多角度收集观点的方法,将传统的"真假"判断转变为多维度分析。该系统能够自动构建争议话题的分析框架,识别不同观点及其支撑证据,为科学和政治争议提供更全面客观的分析,已在生物医学和国际关系领域验证有效性。

清华大学突破性发现:让AI像人类一样理解和表达情感的新方法
清华大学研究团队首次提出情感认知融合网络(ECFN),让AI能像人类一样理解和表达情感。该系统通过多层次情感处理架构,在情感识别准确率上比现有最佳系统提升32%,情感表达自然度提升45%。研究突破了传统AI情感理解的局限,实现了跨模态情感融合、动态情感追踪和个性化情感建模,为医疗、教育、客服等领域带来革命性应用前景。

哈佛大学揭秘:AI如何像人类一样通过"玩游戏"学会复杂推理
哈佛大学研究团队通过创新的多智能体强化学习方法,让AI在战略游戏中学会复杂推理。研究发现AI通过游戏竞争能发展出类人思维能力,在逻辑推理、创造性解决问题等方面表现显著提升。这项突破性成果为未来AI在医疗、教育、城市管理等领域的应用奠定基础,展现了通过模拟人类学习过程培养真正智能AI的新路径。

深度学习也能像人一样"看重点"?揭秘视觉AI如何学会聪明地观察世界

伊利诺伊大学新突破:让机器像法官一样剖析复杂争议,不再简单判"真假"

清华大学突破性发现:让AI像人类一样理解和表达情感的新方法

哈佛大学揭秘:AI如何像人类一样通过"玩游戏"学会复杂推理
