 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
毫米级相机也能拍出大片?这家中国团队用AI让超微镜头媲美专业设备
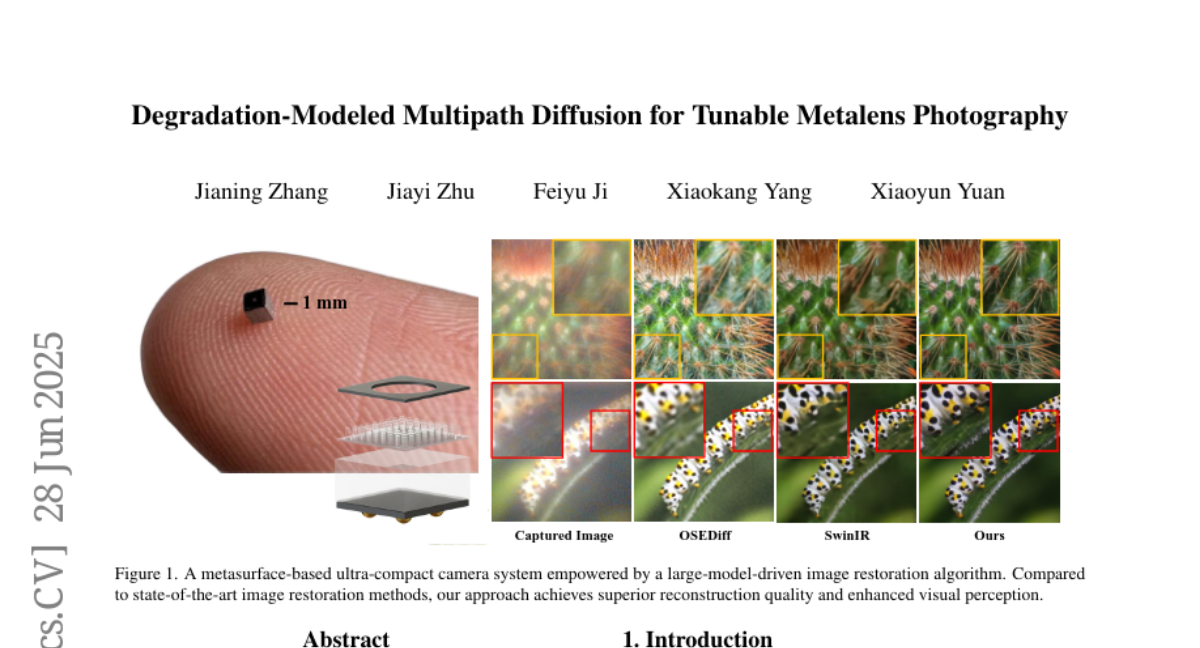
这项由上海交通大学张嘉宁、朱嘉艺、季飞宇团队与杨小康、袁晓云教授共同完成的研究发表于2025年6月的arXiv计算机视觉领域,感兴趣的读者可以通过arXiv:2506.22753v1访问完整论文。想象一下,有一天你的眼镜片厚度的相机就能拍出和单反相机一样清晰的照片,这听起来像科幻小说,但现在真的有人做到了。
传统相机就像一个复杂的光学迷宫,需要好几层镜片才能把光线收集得恰到好处,拍出清晰的照片。这就是为什么相机镜头总是又大又重的原因。但是,当我们需要制造极其微小的相机时,比如用于医疗植入设备或者增强现实眼镜,传统的多镜片设计就完全行不通了。
这时候,一种叫做"超表面镜头"的新技术登场了。如果把传统镜头比作厚重的放大镜,那么超表面镜头就像一张神奇的贴纸,薄得几乎看不见,但却能精确控制光线的方向。这种镜头由无数个比头发丝还细的微小结构组成,每个结构都像一个微型的光线引导员,告诉光线该往哪个方向走。
不过,这种超薄镜头也有自己的问题。就像用一张薄纸试图代替专业相机镜头一样,拍出来的照片往往模糊不清,特别是在照片的边缘部分,就像透过起雾的玻璃看东西一样。以前的解决方法通常需要精确知道镜头的所有光学特性,就像需要一张详细的地图才能找到正确的路,但这种方法在实际应用中既复杂又不可靠。
研究团队想到了一个聪明的解决方案:既然我们已经有了能够理解和生成高质量图像的人工智能模型,为什么不让它来帮助修复这些模糊的照片呢?这就像有一个非常有经验的照片修复师,即使给他一张模糊的老照片,他也能根据自己的经验把它修复得清晰动人。
但是,直接使用现有的图像修复技术有一个大问题:它们往往会"脑补"一些原本不存在的细节。就像一个过于积极的画家,在修复古画时添加了一些原作者从未画过的内容。这在超薄镜头摄影中是不可接受的,因为我们需要的是真实还原,而不是艺术创作。
**一、三条路径的智能修复系统**
为了解决这个问题,研究团队设计了一个独特的三路径修复系统,就像安排三个不同性格的专家同时工作。第一个专家叫"积极路径",它的任务是尽可能恢复照片中的精细细节,就像一个追求完美的艺术家,总是想让画面更加生动精彩。第二个专家叫"中性路径",它更加保守,专注于保持照片的基本结构和真实性,就像一个严谨的历史学家,绝不允许添加任何虚假的信息。第三个专家叫"负面路径",它的工作是识别和消除超薄镜头特有的问题,就像一个专门的"问题清洁工"。
这种设计的巧妙之处在于,三个专家可以互相制衡。当积极路径想要添加过多细节时,中性路径会拉它回到现实;当照片出现超薄镜头特有的畸变时,负面路径会及时纠正。更重要的是,用户可以根据自己的需要调节这三个专家的发言权,就像调节音响的音量平衡一样简单。
这个负面路径还有一个额外的好处:它可以反向工作,用清晰的照片生成模糊的训练样本。这就像一个能够制造"人工老化照片"的机器,帮助系统学习如何处理各种不同程度的模糊问题。这种方法大大扩充了训练数据,让整个系统变得更加聪明和可靠。
**二、空间感知的降质修复技术**
超薄镜头有一个特殊的问题:它拍出的照片不是均匀模糊的,而是像一个同心圆一样,中心部分相对清晰,越靠近边缘越模糊。这就像透过一个有划痕的镜子看世界,不同位置的视觉质量完全不同。
为了应对这个挑战,研究团队开发了一种叫做"空间变化降质感知注意力"的技术。听起来很复杂,但其实概念很简单:就是让修复系统能够"看懂"照片的每个区域有多么模糊,然后针对性地进行修复。
这个系统的工作方式像一个经验丰富的医生。首先,它会"体检"整张照片,通过两种方式评估每个区域的问题严重程度。第一种方式是理论分析,根据超薄镜头的设计参数计算出每个位置应该有多模糊,就像医生根据病史预判病情。第二种方式是直接观察,使用图像质量评估工具实际测量每个区域的清晰度,就像医生直接检查病人的症状。
系统将照片分成一个个小格子,为每个格子计算一个"模糊指数"。这个指数综合了理论预测和实际观察的结果,告诉修复算法应该在这个区域投入多少"注意力"。模糊严重的区域会得到更多的修复资源,而相对清晰的区域则保持原样,避免过度处理。
这种方法的优势在于它不需要事先精确校准镜头参数。传统方法就像需要一份详细的地图才能导航,而这个新方法更像一个有经验的向导,能够根据实际情况灵活调整路线。
**三、毫米级超微相机的实际制造**
为了验证他们的算法,研究团队真的制造了一个毫米级的超微相机,他们称之为"MetaCamera"。这个相机小得令人难以置信,整体尺寸只有1立方毫米左右,比一粒芝麻还要小。
这个超微相机的核心是一片由硅氮化物制成的超薄镜头,厚度只有几百纳米,相当于头发丝的千分之一。镜头表面布满了密密麻麻的微型柱状结构,每个柱子的直径在100到300纳米之间,比病毒还要小。这些微型结构的排列不是随机的,而是经过精心设计的,每个位置的柱子直径都不相同,形成一个复杂的光学调制图案。
制造这样的镜头需要极其精密的纳米加工技术。研究团队使用了有限时域差分仿真和神经网络优化相结合的设计方法,确保每个微结构都能精确控制通过它的光线相位。这个过程就像用原子级的精度雕刻一件艺术品,任何细微的误差都可能影响最终的成像质量。
这个超微相机配备了一个400×400像素的CMOS图像传感器,虽然分辨率不高,但对于这么小的设备来说已经相当不错了。整个相机模组的组装也是一个技术挑战,需要将超薄镜头精确对准图像传感器,对准精度要求达到微米级别。
**四、训练数据的巧妙获取**
获得训练数据是这类研究中最困难的部分之一。不像普通的照片修复,超薄镜头的成像特性非常特殊,很难找到现成的对比数据。研究团队采用了一种聪明的数据收集策略。
他们首先在显示器上播放各种图片,然后用自制的超微相机拍摄这些图片。为了保证图像对齐,他们先用机械方法进行粗略对准,然后使用单应性变换进行精确的像素级对齐。这个过程就像给两张照片做"指纹比对",确保每个像素都能完美匹配。
除了直接拍摄,他们还收集了三个公开数据集(DIV2K、Flickr2K和WED),使用多尺度裁剪技术从中提取了7800张训练图像和3000张测试图像。更重要的是,他们利用前面提到的负面路径,从1万张高质量图像生成了对应的模糊样本,这种"人工制造问题"的方法大大丰富了训练数据。
为了确保算法的实用性,他们还在各种真实场景下进行了测试,包括室内外不同光照条件、不同距离的物体、不同颜色和纹理的目标等。这种全方位的测试确保了算法在实际应用中的可靠性。
**五、令人惊喜的实验结果**
实验结果超出了研究团队的预期。在多项图像质量指标上,他们的方法都显著超越了现有的最佳技术。在PSNR(峰值信噪比)这个衡量图像保真度的指标上,他们的方法达到了30.31,而最好的对比方法只有29.46。在MUSIQ这个衡量主观视觉质量的指标上,他们更是达到了51.85的高分,远超其他方法。
更重要的是定性对比的结果。从视觉效果来看,传统的图像修复方法如SwinIR虽然能够减少一些模糊,但往往让照片看起来像是蒙了一层雾,细节缺失严重。而基于扩散模型的方法如OSEDiff和SeeSR虽然能生成更多细节,但经常会添加一些原本不存在的内容,特别是在处理超薄镜头特有的色散问题时表现不佳。
相比之下,新方法生成的图像既保持了出色的细节表现,又很好地控制了虚假信息的产生。特别是在照片边缘这些最困难的区域,新方法依然能够保持较好的修复效果,而其他方法往往在这些区域完全失效。
可调节功能也得到了验证。通过调整α参数,用户可以在保真度和视觉效果之间找到最适合自己需求的平衡点。当α值较小时,修复结果更加保守,PSNR和SSIM等客观指标更高;当α值较大时,图像看起来更加生动自然,主观视觉质量更佳。
**六、技术创新的深层价值**
这项研究的意义远超表面上的技术改进。在传统的计算成像领域,人们总是试图通过更精确的光学设计或更复杂的物理模型来解决问题。这种方法就像试图制造一个完美的机械钟表,每个齿轮都必须精确无误。
而这项研究代表了一种全新的思路:与其追求完美的硬件,不如让软件变得足够智能来弥补硬件的不足。这就像用一个聪明的翻译软件来代替完美的语言能力,虽然底层机制不同,但最终效果可能更好。
这种"用AI补偿光学缺陷"的思路对整个计算成像领域都有重要启发。它证明了在某些情况下,通过算法优化可能比硬件改进更有效率,也更容易实现大规模应用。
从实用角度来看,这项技术为超紧凑成像设备的应用打开了新的可能性。未来的智能隐形眼镜、植入式医疗设备、微型无人机等都可能受益于这种技术。当成像设备可以做到真正的微型化时,我们对于"相机"这个概念的理解也会发生根本性的改变。
**七、面向未来的技术展望**
虽然这项研究取得了显著成果,但研究团队也坦承还有很多改进空间。目前的系统主要针对静态图像设计,对于动态视频的处理还需要进一步优化。此外,不同光照条件下的表现稳定性也是一个需要持续改进的方向。
从技术发展趋势来看,这种结合先进光学设计和人工智能的方法代表了计算成像的未来方向。我们可能会看到更多类似的"光学-AI混合"系统,其中硬件负责基础的光学收集,而AI负责后续的智能处理和优化。
这项研究也为其他类型的计算成像问题提供了思路。比如夜视成像、医学成像、天文观测等领域都可能从类似的方法中受益。关键在于如何根据不同应用的特点,设计出相应的多路径处理策略和质量感知机制。
更广泛地说,这项工作体现了当前科技发展的一个重要趋势:通过软硬件的深度融合来突破传统技术瓶颈。这种思路不仅适用于成像领域,在通信、传感、显示等多个技术领域都有类似的应用潜力。
说到底,这项研究最令人兴奋的地方在于它重新定义了我们对"相机"这个概念的理解。当一个比芝麻还小的设备也能拍出专业级照片时,我们就真正进入了一个"无处不在的成像"时代。也许不久的将来,每一个智能设备、每一件可穿戴产品,甚至每一粒智能尘埃都可能配备这样的超微相机,为我们提供前所未有的视觉信息获取能力。研究团队已经把详细的技术资料和演示视频放在了他们的项目网站https://dmdiff.github.io/上,感兴趣的读者可以进一步了解这项令人振奋的技术突破。
Q&A
Q1:超表面镜头和传统镜头有什么区别? A:超表面镜头就像一张神奇的贴纸,厚度只有几百纳米,通过表面的微小结构控制光线,而传统镜头需要多层厚重的玻璃。超表面镜头虽然超薄,但成像质量较差,需要AI算法来弥补这个缺陷。
Q2:这个毫米级相机能达到什么样的拍照效果? A:经过AI修复后,这个只有1立方毫米大小的相机能拍出接近传统相机的清晰照片。虽然分辨率只有400×400像素,但在细节还原和色彩准确度方面表现出色,特别是解决了超薄镜头边缘模糊的问题。
Q3:这项技术什么时候能实际应用? A:目前还处于实验室阶段,但技术已经相当成熟。未来可能首先应用于医疗植入设备、增强现实眼镜等对尺寸要求极高的场合,预计在5-10年内可能看到商业化产品。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来
韩国KAIST开发的Vector Prism系统通过多视角观察和统计推理,解决了AI无法理解SVG图形语义结构的难题。该系统能将用户的自然语言描述自动转换为精美的矢量动画,生成的动画文件比传统视频小54倍,在多项评估中超越顶级竞争对手,为数字创意产业带来重大突破。

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
华为诺亚方舟实验室提出VersatileFFN创新架构,通过模仿人类双重思维模式,设计了宽度和深度两条并行通道,在不增加参数的情况下显著提升大语言模型性能。该方法将单一神经网络分割为虚拟专家并支持循环计算,实现了参数重用和自适应计算分配,为解决AI模型内存成本高、部署难的问题提供了全新思路。

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
