 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
视觉语言模型也能深度思考:香港科技大学推出VL-Rethinker,让AI看图答题像人类一样反思纠错
这项由香港科技大学的王浩哲领导,联合滑铁卢大学和INF.AI公司完成的研究发表于2025年1月,论文题目为"VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning"。有兴趣深入了解的读者可以通过项目页面https://tiger-ai-lab.github.io/VL-Rethinker/访问完整论文和相关资源。
近年来,OpenAI的o1和DeepSeek的R1等"慢思考"AI系统在数学和科学问题上展现出了令人瞩目的能力。这些AI就像经验丰富的学者一样,会在给出答案前进行深入思考、反复验证,因此在各类考试中的表现远超那些"快思考"的传统AI模型。然而,当这些AI面对需要同时理解图像和文字的复杂任务时,它们的"慢思考"优势却神奇地消失了。
以GPT-o1为例,它在纯文本的数学题上可以轻松击败GPT-4o等传统模型30%以上,但在需要看图解题的数学视觉推理任务上,表现却与传统模型不相上下。这就像一个在纸面推理游戏中无往不利的高手,一旦要求他同时观察棋盘和思考策略,反而变得手忙脚乱。
为了解决这个问题,研究团队开发了VL-Rethinker,这是一个能够在视觉语言任务中进行深度反思的AI系统。与那些依赖复杂师生教学模式的方法不同,VL-Rethinker采用了一种更直接的训练方式,就像教一个学生学会自我检查作业一样。
**一、视觉语言模型的"反思困境"**
要理解VL-Rethinker的创新之处,我们首先需要明白现有AI系统面临的挑战。传统的视觉语言模型就像一个只会快速抢答的学生,看到图片和问题后立即给出答案,很少停下来思考"我的答案对吗?""是否还有其他可能性?"这种approach在简单任务上效果不错,但面对复杂的多步推理问题时就显得力不从心。
研究团队发现,即使是目前最先进的视觉语言模型,在处理需要深度思考的图像理解任务时,也很少表现出类似人类的反思行为。这就像让一个从不检查作业的学生去解决复杂的几何证明题,结果往往是错误百出。
更有趣的是,研究人员发现了一个令人困惑的现象:同样的强化学习训练方法,在纯文本任务上能够有效激发AI的深度思考能力,但在视觉语言任务上却效果甚微。这种差异就像同一种教学方法对不同科目的学生产生完全不同的效果一样神秘。
**二、创新的训练策略:选择性样本回放**
为了解决这个问题,研究团队首先要克服一个被称为"优势消失"的技术难题。这个问题就像教练在训练运动员时发现,随着训练的进行,能够提供有效指导的训练样本越来越少,最终导致训练效果停滞。
具体来说,传统的GRPO算法通过比较同一问题的不同回答来判断哪个更好,然后据此调整模型。然而,当模型变得越来越熟练后,它对同一问题的多个回答往往都是正确的或都是错误的,这就失去了比较的意义,就像所有学生都考满分或都考零分时,老师就无法区分谁学得更好。
研究团队提出的解决方案叫做"选择性样本回放"(SSR)。这个方法就像给AI建立一个"错题本",专门记录那些曾经让它纠结或犯错的问题。在后续训练中,系统会刻意重温这些有价值的学习经验,确保不会因为新题目的加入而忘记之前的重要教训。
这种方法的巧妙之处在于,它不是简单地重复所有旧题目,而是智能地挑选那些最能提供学习价值的经验。就像一个聪明的学生不会盲目刷题,而是专注于那些最容易出错或最具代表性的问题类型。
**三、强制反思:教会AI"三思而后行"**
解决了训练稳定性问题后,研究团队发现还有一个更深层的挑战:即使训练顺利进行,AI也很难自发地产生反思行为。这就像一个学生虽然解题能力提升了,但仍然没有养成检查答案的习惯。
为此,研究团队开发了"强制反思"技术。这个方法就像在学生的作业本上预先印好"请检查你的答案"这样的提示,强制AI在给出答案后进行二次思考。具体来说,系统会在AI的初始回答后自动添加反思触发词,比如"等等,这样对吗?"或"让我再检查一下",然后要求AI继续思考。
这种方法包含了三种不同类型的反思触发:自我质疑、自我纠错和自我验证。就像培养一个全面的思维习惯,AI需要学会问自己"这个答案合理吗?"、"我是否犯了什么错误?"以及"让我验证一下这个结论"。
有趣的是,经过这种训练的AI最终学会了选择性地进行反思,而不是机械地对每个问题都进行冗长的思考。它就像一个经验丰富的专家,能够直觉地判断哪些问题需要额外的思考时间,哪些问题可以快速回答。
**四、令人瞩目的实验结果**
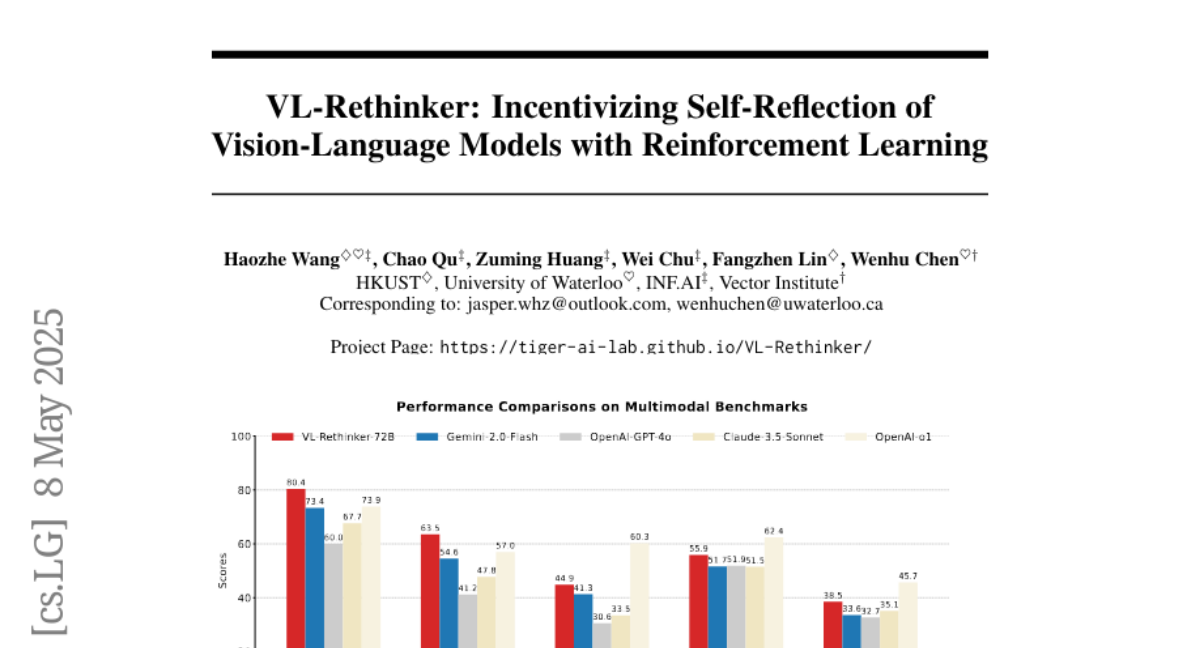
VL-Rethinker在多个权威测试集上的表现令人印象深刻。在数学视觉推理任务MathVista上,VL-Rethinker-72B达到了80.4%的准确率,显著超过了GPT-o1的73.9%。在另一个重要测试MathVerse上,它也达到了63.5%的成绩,比GPT-o1的57.0%高出6.5个百分点。
更重要的是,VL-Rethinker不仅在数学相关任务上表现优秀,在多学科理解和现实世界任务上也创下了开源模型的新纪录。比如在MMMU-Pro测试中达到55.9%,在EMMA测试中达到38.5%,在MEGA-Bench测试中达到51.3%。
这些数字背后反映的是AI推理能力的实质性提升。研究团队发现,经过训练的VL-Rethinker不仅能够自我纠错,甚至能够发现题目本身的问题。在一个几何题的例子中,AI在初始回答后进行反思,发现题目描述存在矛盾,并明确指出需要额外信息才能得出结论。
**五、从"快答"到"深思"的转变机制**
研究团队对VL-Rethinker的学习过程进行了深入分析,发现了一些有趣的现象。通过词云分析,他们发现训练后的AI经常使用"double check"(再次检查)、"mistake"(错误)、"correct"(正确)等反思相关词汇,这表明它确实内化了自我监督的思维模式。
更有价值的发现是,VL-Rethinker学会了适应性反思。在不同类型的任务中,它进行反思的频率是不同的。比如在MathVision任务中,反思比例约为26%,而在MMMU-Pro任务中约为62%。这种差异化策略表明AI能够根据任务难度和自身把握程度来决定是否需要额外思考,这与人类专家的行为非常相似。
研究团队还通过对比实验验证了强制反思策略的有效性。他们发现,如果强制基线模型对每个问题都进行反思,虽然会带来一些提升,但效果远不如经过专门训练的VL-Rethinker。这说明简单的技术手段无法替代系统性的能力培养,就像临时抱佛脚无法替代扎实的基础训练。
**六、技术实现的精妙设计**
VL-Rethinker的训练过程体现了研究团队对技术细节的精心考量。他们构建了一个包含38,870个问题的多样化数据集,涵盖数学、科学、图表理解等多个领域。为了确保训练效率,他们针对不同规模的模型精心筛选了适合的训练子集,避免了"一刀切"的简单做法。
在具体的训练策略上,团队采用了近在线的强化学习范式,每处理1024个问题后就同步行为策略和改进策略。这种做法既保证了训练的稳定性,又避免了策略偏移过大的问题。同时,他们设定每个问题最多接受两个正确的反思轨迹,这个限制既保证了数据质量,又避免了过度拟合。
值得一提的是,研究团队在实验设计上也展现了严谨的科学态度。他们不仅与最先进的商业模型进行比较,还与专门针对推理优化的开源模型进行对比,确保了评估的全面性和公正性。
**七、未来展望与思考**
VL-Rethinker的成功为视觉语言AI的发展开辟了新方向,但也引发了一些深层思考。研究团队坦诚地指出,目前的方法在某些通用多模态任务上仍有改进空间,主要瓶颈可能在于高质量训练数据的不足。
这项研究还揭示了一个有趣的现象:相同的训练方法在不同模态任务上会产生不同效果。为什么强化学习在纯文本推理中更容易激发深度思考,而在视觉语言任务中需要额外的技术手段?这个问题的答案可能涉及认知科学、神经科学和机器学习理论的交叉领域,值得进一步探索。
从实用角度来看,VL-Rethinker为开发更智能的AI助手提供了重要启示。未来的AI系统可能不再是简单的"问答机器",而是能够进行深度思考、自我检查和持续改进的智能伙伴。这种能力对于教育、科研、工程设计等需要高度精确性的领域具有重要价值。
**八、方法论的深度解析**
VL-Rethinker的核心创新在于巧妙结合了两个看似简单但极其有效的策略。选择性样本回放(SSR)解决了训练过程中的技术难题,而强制反思则培养了AI的元认知能力。这种组合就像为学生同时提供了高质量的练习材料和良好的学习习惯指导。
在SSR的实现中,系统维护一个经验回放缓冲区,专门存储那些产生了非零优势信号的样本。采样概率与优势值的绝对大小成正比,这确保了那些最具学习价值的经验能够被反复利用。这种设计体现了机器学习中"困难样本挖掘"的思想,但在强化学习的框架下得到了新的诠释。
强制反思的设计更是体现了研究团队对人类认知过程的深刻理解。通过在回答后添加反思触发词,系统引导AI进入一种类似人类"二次思考"的状态。关键在于,这种引导不是简单的模板填充,而是真正激发了AI对自身答案的批判性评估。
**九、实验设计的周密考量**
研究团队在实验设计上展现了高度的专业素养。他们选择了七个具有代表性的评测基准,涵盖了从纯数学推理到多学科理解再到现实世界应用的全方位场景。这种全面的评估策略确保了结论的可靠性和适用性。
特别值得注意的是,团队采用了严格的Pass@1贪心解码评估方式,这意味着AI只有一次机会给出正确答案,不允许多次尝试后选择最佳结果。这种评估标准更接近真实应用场景,也更能体现模型的真实能力。
在对比实验中,研究团队不仅比较了最终性能,还深入分析了训练动态。通过追踪训练过程中有效查询的比例变化,他们清晰地展示了"优势消失"问题的存在和SSR策略的有效性。这种深入的分析为其他研究者提供了宝贵的实践指导。
**十、技术贡献的理论意义**
从更宏观的角度来看,VL-Rethinker的成功验证了"显式反思训练"在人工智能中的可行性。长期以来,AI研究者一直在探索如何让机器具备类似人类的元认知能力,即"思考如何思考"的能力。VL-Rethinker提供了一个具体可行的技术路径。
这项研究还揭示了多模态学习中的一个重要洞察:不同模态的信息处理可能需要不同的认知策略。纯文本推理更多依赖逻辑链条的构建,而视觉语言推理则需要在视觉理解和文本理解之间建立复杂的对应关系。这种差异要求AI系统具备更灵活的适应性思维模式。
研究成果还为强化学习在复杂认知任务中的应用提供了新思路。传统的强化学习往往关注动作选择的优化,而VL-Rethinker展示了如何利用强化学习来培养更高层次的认知技能。这种paradigm shift可能会影响未来AI系统的设计思路。
说到底,VL-Rethinker不仅仅是一个技术突破,更是对AI认知能力本质的深入探索。它告诉我们,真正智能的AI系统不应该只是一个高速的答题机器,而应该是一个能够思考、反思、自我改进的学习者。
通过巧妙的训练策略设计,研究团队成功地将"慢思考"的优势引入到视觉语言理解中,为构建更智能、更可靠的AI系统开辟了新道路。虽然目前的方法还有改进空间,但VL-Rethinker已经证明了这个方向的巨大潜力。
对于关心AI发展的读者来说,这项研究展示了一个令人兴奋的可能性:未来的AI助手不仅能快速处理信息,还能像人类专家一样进行深入思考和自我检查。这种能力的实现,将为教育、科研、医疗诊断等众多领域带来革命性的改变。同时,这种能够自我反思的AI也为解决当前AI系统的可靠性和可解释性问题提供了新思路。
如果读者对这项研究的技术细节感兴趣,可以访问项目页面获取完整的论文、代码和数据集,研究团队已经将所有资源开源,以促进整个学术界在这个方向上的进一步探索。
Q&A
Q1:VL-Rethinker是什么?它能做什么? A:VL-Rethinker是香港科技大学开发的AI视觉语言模型,它的核心能力是在处理需要同时理解图像和文字的任务时能够进行深度反思。就像一个会检查作业的学生,它不仅能快速给出答案,还会主动思考"我的答案对吗?"并进行自我纠错,在数学视觉推理等任务上表现显著超越了GPT-o1等先进模型。
Q2:VL-Rethinker会不会取代现有的AI模型? A:目前不会完全取代,但会推动AI发展方向的改变。VL-Rethinker主要在需要复杂推理的视觉语言任务上表现出色,它更像是为现有AI系统增加了"深度思考"能力。未来的AI系统可能会普遍具备这种自我反思能力,从简单的"问答机器"进化为能够深度思考的智能伙伴。
Q3:普通人能使用VL-Rethinker吗?有什么实际应用? A:目前VL-Rethinker还主要用于研究阶段,研究团队已将相关代码和数据开源。未来这种技术可能会被集成到教育软件、智能助手、医疗诊断系统等应用中。比如在在线教育中,AI能够像老师一样检查学生的解题过程并给出针对性建议,或在工程设计中提供更可靠的图像分析和决策支持。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来
韩国KAIST开发的Vector Prism系统通过多视角观察和统计推理,解决了AI无法理解SVG图形语义结构的难题。该系统能将用户的自然语言描述自动转换为精美的矢量动画,生成的动画文件比传统视频小54倍,在多项评估中超越顶级竞争对手,为数字创意产业带来重大突破。

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
华为诺亚方舟实验室提出VersatileFFN创新架构,通过模仿人类双重思维模式,设计了宽度和深度两条并行通道,在不增加参数的情况下显著提升大语言模型性能。该方法将单一神经网络分割为虚拟专家并支持循环计算,实现了参数重用和自适应计算分配,为解决AI模型内存成本高、部署难的问题提供了全新思路。

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
