 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
只要256MB就能秒杀80B大模型?Hugging Face推出史上最小却最强的视觉AI助手
这项由Hugging Face和斯坦福大学的Andrés Marafioti、Orr Zohar、Miquel Farré等十多位研究者共同完成的重磅研究,发表于2025年4月7日的arXiv预印本平台。感兴趣的读者可以通过arXiv:2504.05299v1访问完整论文,相关代码和模型已在Hugging Face社区开源发布。
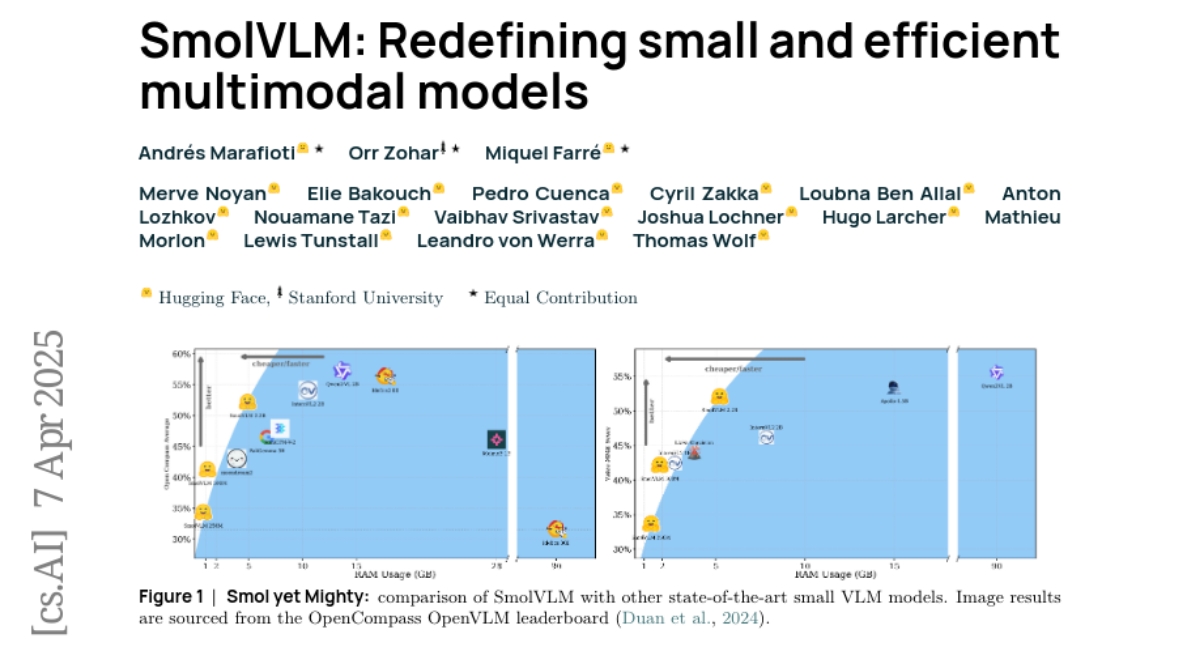
你有没有想过,一个比手机应用还小的AI,居然能看懂图片、理解视频,甚至回答复杂问题?更让人惊讶的是,这个"小不点"的表现竟然比那些需要占用几十GB内存的庞然大物还要出色。Hugging Face的研究团队就创造了这样一个奇迹——他们开发的SmolVLM系列模型,最小的版本只有256MB,运行时占用的显存还不到1GB,但性能却能超越18个月前那些参数量是它300倍的大型模型。
传统的视觉语言模型就像是一台需要整个车库才能放下的超级计算机,虽然功能强大,但普通人根本无法在家中使用。而SmolVLM就像是把这台超级计算机的核心功能塞进了一台笔记本电脑里,不仅携带方便,性能还丝毫不打折扣。研究团队通过巧妙的架构设计、精明的数据处理策略,以及创新的训练方法,彻底颠覆了"模型越大越好"的传统观念。
更令人兴奋的是,SmolVLM不仅能处理静态图片,还具备出色的视频理解能力。无论是识别图片中的文字、理解图表数据、回答科学问题,还是分析视频内容、理解时间序列,这个"小家伙"都能胜任。研究团队甚至开发了一个手机应用,让SmolVLM可以直接在智能手机上运行,真正实现了"人人都能拥有的AI助手"。
一、从大而笨重到小而精巧:SmolVLM的设计智慧
要理解SmolVLM的革命性意义,我们先来看看传统视觉语言模型面临的困境。过去的研究就像在建造越来越大的图书馆,以为书越多就越聪明,结果建出来的图书馆虽然藏书丰富,但普通人既找不到地方放置,也没有足够的资源来维护运营。
SmolVLM的设计哲学完全不同,研究团队的策略更像是打造一个精品书店——虽然书的数量不多,但每一本都经过精心挑选,布局合理,读者能够快速找到想要的信息。他们发现,对于小型模型来说,关键不在于拥有多少参数,而在于如何让这些参数发挥最大效用。
在架构设计上,SmolVLM采用了一种分工合作的策略。整个系统就像一个高效的工厂流水线:首先有一个专门负责"看图"的视觉编码器,它就像工厂里的质检员,负责仔细观察输入的图片或视频;然后有一个像素重排模块,相当于包装工,把视觉信息整理成后续处理更容易消化的格式;最后是语言模型部分,就像工厂里的产品说明书撰写员,负责用人类能理解的语言描述所看到的内容。
研究团队最聪明的地方在于找到了视觉编码器和语言模型之间的最佳配比。他们发现,对于小型模型来说,使用一个相对较小的视觉编码器(93M参数的SigLIP-B/16)搭配适中的语言模型,比使用大型视觉编码器搭配小型语言模型效果更好。这就好比组建一个乐队,与其让一个世界级的钢琴家搭配业余歌手,不如让两个都很优秀但更加协调的音乐家合作,最终的演出效果反而更佳。
二、巧妙的图像处理:让AI用更少看到更多
SmolVLM在图像处理方面的创新就像是给AI装上了一副特殊的眼镜,让它能够用更高效的方式"观看"世界。传统模型处理图像时,就像用放大镜逐个检查图片的每一个像素点,这种方法虽然细致,但效率极低,很快就会被海量的信息淹没。
研究团队引入了一种叫做"像素重排"的技术,这个过程就像是重新整理一个凌乱的书架。原本散乱分布的像素信息被重新组织,空间分辨率降低了,但信息密度却大大提升。打个比方,这就像把一张大海报压缩成一张精美的明信片,虽然尺寸变小了,但重要信息一点都没有丢失,反而更容易携带和处理。
更令人惊讶的是,研究团队发现小型模型实际上更适合使用激进的压缩策略。传统模型通常使用2倍压缩,而SmolVLM可以使用4倍压缩而不损失性能。这种现象的原因很有意思:小型模型的"注意力"是有限的,与其让它分散精力处理大量细节,不如让它专注于最重要的信息。这就像是让一个学生在有限的时间内学习,与其让他囫囵吞枣地读完整本教科书,不如让他专心掌握核心概念和重点内容。
对于高分辨率图像,SmolVLM采用了图像分割策略。当遇到一张大图片时,系统会像拼图游戏一样将其分割成若干小块,同时保留一个缩略版本作为全局参考。这样既能捕捉到细节信息,又不会因为信息量过大而"消化不良"。这种方法特别适合处理文档、图表这类需要精确识别的内容。
三、视频理解的智慧:时间就是效率
在视频处理方面,SmolVLM展现出了与众不同的"时间智慧"。许多传统方法试图通过帧平均化来减少计算量,就像把连续的电影画面混合成一幅静态图片。但研究团队发现,这种做法对小型模型来说是适得其反的,反而会损害理解能力。
相反,SmolVLM选择了一种更加直接的策略:保持每一帧的独立性,但将它们调整到合适的分辨率进行处理。这就像是观看幻灯片演示,每一张幻灯片都清晰可见,观众能够理解前后之间的逻辑关系和时间变化。
研究团队还发现了一个有趣的现象:适度增加训练时的视频长度不仅能提升视频理解能力,还能改善静态图像的处理效果。他们将平均视频长度从1.5分钟逐步增加到3.5分钟,发现这是一个"甜蜜点"——再长的视频带来的收益就会递减。这种现象说明视频和图像的理解能力是相互促进的,多模态学习确实存在协同效应。
四、训练数据的精心配置:少而精的哲学
SmolVLM的训练过程体现了"少而精"的哲学。研究团队发现,对于小型模型来说,数据质量远比数量重要。他们的发现颠覆了许多传统做法。
首先,他们发现重复使用大型语言模型的文本数据实际上会损害小型多模态模型的性能。这就像是让一个小学生去学习研究生课程,不仅学不会,还可能被复杂的内容搞得更加困惑。研究团队坚持使用新鲜的、专门为多模态任务设计的文本数据,效果显著提升。
其次,他们发现思维链(Chain-of-Thought)数据对小型模型来说是一把双刃剑。少量的思维链数据(约0.02-0.05%)能够提升推理能力,但过多反而会"压垮"模型的有限容量。这就像是给一个初学者适量的解题思路提示是有帮助的,但如果提供过多复杂的推理步骤,反而会让学习者感到困惑。
在位置编码方面,研究团队发现了"OCR丢失困境"——当使用简单的字符串标记来表示图像分块位置时,小型模型会出现训练停滞现象。他们创新性地引入了学习位置标记,让模型自己学会如何理解空间关系,这种方法显著提升了文字识别和文档理解能力。
五、三个层次的SmolVLM:各有所长的AI家族
研究团队贴心地开发了三个不同规模的SmolVLM版本,就像是为不同需求的用户准备了三种不同配置的汽车。
最小的SmolVLM-256M就像是一辆精巧的小型车,虽然体积最小,但五脏俱全。它只有256M参数,运行时的显存占用不到1GB,完全可以在普通智能手机上流畅运行。别看它小,在许多任务上的表现却能够超越那些大300倍的传统模型,特别适合移动设备和边缘计算场景。
中等规模的SmolVLM-500M就像是一辆实用的紧凑型轿车,在保持高效率的同时提供了更强的性能。它使用相同的视觉编码器,但搭配了更大的语言模型(360M参数),在图像理解和文字识别方面有显著提升,运行时只需要1.2GB显存,依然非常适合资源受限的环境。
最大的SmolVLM-2.2B则像是一辆高性能轿车,在保持相对紧凑的同时追求卓越性能。它使用了更强大的视觉编码器(400M参数)和语言模型(1.7B参数),在各种复杂任务上都表现出色,运行时需要4.9GB显存,虽然比前两个版本要求更高,但相比传统大型模型仍然非常高效。
六、性能测试:小身材的大能耐
SmolVLM在各种标准测试中的表现堪称惊艳。在文字识别任务中,最小的256M版本在OCRBench测试中获得了52.6%的成绩,而500M版本达到了61.0%,最大的2.2B版本更是达到了72.9%。要知道,许多参数量大得多的传统模型在这项测试中的表现还不如SmolVLM的中等版本。
在科学图表理解方面,SmolVLM同样表现出色。在AI2D科学图表测试中,2.2B版本获得了70.0%的优异成绩,这意味着它能够理解复杂的科学图表、图形和示意图。在图表问答任务ChartQA中,它获得了68.7%的成绩,展现出强大的数据可视化理解能力。
更令人印象深刻的是SmolVLM在数学推理方面的表现。在MathVista数学视觉推理测试中,2.2B版本获得了51.5%的成绩,超越了许多大型模型。这说明SmolVLM不仅能"看懂"数学图形和公式,还能进行复杂的数学推理。
在视频理解方面,SmolVLM也毫不逊色。在Video-MME综合视频理解测试中,2.2B版本获得了52.1%的成绩,在时间推理基准TempCompass中达到了53.7%。这些成绩证明了SmolVLM具备出色的视频内容理解和时间推理能力。
七、效率革命:让AI触手可及
SmolVLM最大的突破在于其惊人的效率表现。在GPU内存使用方面,SmolVLM-256M单张图片推理只需0.8GB显存,500M版本需要1.2GB,即使是最大的2.2B版本也只需要4.9GB。相比之下,性能相当的MolmoE-A1B-7B模型需要27.7GB显存,差距高达5-35倍。
这种效率优势在批处理时更加明显。当批处理64张图片时,SmolVLM-256M和500M版本分别只需要15.0GB和16.0GB显存,而2.2B版本需要49.9GB。这意味着即使在处理大量数据时,SmolVLM仍然能在相对普通的硬件上运行。
在推理速度方面,SmolVLM同样表现优异。在NVIDIA A100 GPU上,256M版本能够达到每秒16.3个样本的处理速度(批大小64),500M版本达到9.9个样本/秒,2.2B版本也有1.7个样本/秒。即使在资源更受限的L4 GPU上,256M版本仍能达到2.7个样本/秒的处理速度。
八、真正的移动AI:从云端到掌心
SmolVLM的一个重要突破是实现了真正意义上的移动端AI应用。研究团队开发了名为HuggingSnap的移动应用,让SmolVLM能够直接在智能手机上运行。这个应用就像是把一个专业的AI助手装进了手机里,用户可以随时随地拍照提问,获得即时的智能回答。
更令人兴奋的是,通过WebGPU技术,SmolVLM甚至可以直接在浏览器中运行。256M版本在14英寸MacBook Pro(M4 Max)上能够达到每秒80个token的解码速度,这意味着用户无需安装任何软件,就能在网页中体验强大的视觉AI功能。
这种移动化的实现具有重要意义。以往的大型AI模型都需要连接云端服务器才能使用,不仅响应速度慢,还要担心隐私泄露问题。SmolVLM的出现彻底改变了这种状况,让用户能够享受完全本地化的AI服务,既保护了隐私,又获得了更快的响应速度。
九、实际应用:从科研到生活的全面渗透
SmolVLM的实用价值已经在多个领域得到验证。在医疗健康领域,基于SmolVLM开发的BioVQA系统能够帮助医护人员快速分析医学影像,回答临床问题。由于其小巧的体积和出色的性能,这样的系统可以部署在资源有限的基层医疗机构,为更多患者提供AI辅助诊断服务。
在文档处理方面,超紧凑的Smol Docling系统专门针对文档转换任务进行了优化。这个只有256M参数的系统能够处理商业文档、学术论文、专利文件等各种复杂文档,准确识别内容、理解结构、保持格式,堪比那些大得多的通用模型。
在移动办公场景中,SmolVLM展现出巨大潜力。用户可以用手机拍摄白板内容、图表数据或文档页面,SmolVLM能够立即识别其中的文字、理解图表含义、回答相关问题。这就像是随身携带了一个专业的图像分析师,随时为你解读各种视觉信息。
十、技术细节:魔鬼在细节中
SmolVLM的成功离不开众多精妙的技术细节。在训练策略上,研究团队发现系统提示词的设计对性能有显著影响。他们为不同类型的任务设计了专门的提示词,比如对话任务使用"你是一个有用的对话助手",而视觉任务则使用"你是一个视觉智能体,应该提供简洁的答案"。
在媒体分割方面,研究团队巧妙地使用了引导词来帮助模型理解不同类型的输入。对于图像,系统会添加"这是一张图片..."这样的前缀;对于视频,则使用"这里有N帧从视频中采样的画面..."。这种做法就像是给AI戴上了"语境眼镜",帮助它更好地理解当前处理的内容类型。
用户提示词遮蔽是另一个重要的技术创新。在训练过程中,系统有时会故意"忽略"用户的问题部分,只关注答案部分。这种做法强迫模型专注于任务相关的内容,而不是简单地记忆问题模式,从而提高了泛化能力和回答质量。
十一、对比竞品:小而强的独特优势
与其他同类产品相比,SmolVLM展现出独特的优势。传统的大型模型如GPT-4V虽然功能强大,但部署成本极高,普通用户和小型企业根本无法承受。一些中型模型如Qwen2VL-2B和InternVL2-2B虽然参数量相近,但显存需求分别高达13.7GB和10.5GB,是SmolVLM的3-5倍。
更重要的是,SmolVLM在保持高效率的同时,并没有明显牺牲性能。在许多关键测试中,SmolVLM-2.2B的表现与那些资源需求更高的模型相当甚至更优。比如在MathVista数学推理测试中,SmolVLM-2.2B(51.5%)超越了Qwen2VL-2B(48.0%),而显存需求只有后者的三分之一。
在视频理解方面,SmolVLM的优势更加明显。它在Video-MME测试中的52.1%成绩超越了许多专门针对视频任务设计的大型模型,证明了其在时间序列理解方面的出色能力。
十二、未来展望:小模型的大时代
SmolVLM的成功标志着AI发展进入了一个新阶段——从"大就是美"转向"精就是强"。这种转变不仅仅是技术上的突破,更代表了AI普及化的重要里程碑。
随着SmolVLM这样的高效模型不断涌现,我们可以预见AI将更深入地融入日常生活。每个人的手机都可能成为一个强大的AI助手,能够理解周围的世界、回答复杂问题、协助完成各种任务。这种"人人都有AI"的未来正在变为现实。
对于开发者和研究者来说,SmolVLM的开源释放也意味着巨大的机会。他们可以基于这个高效的基础模型开发各种专门应用,而不需要投入巨额的计算资源。这将大大降低AI创新的门槛,推动整个行业的快速发展。
研究团队已经公开了所有的模型权重、训练数据和代码,并提供了详细的技术文档。这种开放的态度不仅体现了学术精神,也为整个AI社区的发展做出了重要贡献。任何有兴趣的开发者都可以基于SmolVLM进行二次开发,创造出更多有价值的应用。
说到底,SmolVLM的意义远超其技术本身。它证明了在AI发展的道路上,"小而美"同样是一条可行且充满前景的路径。通过精巧的设计、智慧的优化和精心的训练,小型模型也能展现出令人惊叹的能力。这不仅为AI的普及化铺平了道路,也为我们重新思考AI发展的方向提供了重要启示。当我们不再盲目追求参数量的增长,而是专注于效率和实用性的提升时,AI技术将真正走入千家万户,成为每个人都能享受的智能助手。感兴趣的读者可以通过论文中提供的链接体验SmolVLM的各种应用,亲身感受这个"小巧巨人"的强大能力。
Q&A
Q1:SmolVLM真的比那些大型AI模型更好用吗? A:在特定场景下确实如此。SmolVLM最大的优势是效率极高,可以在普通手机上运行,而传统大型模型需要专业服务器。虽然在某些复杂任务上可能不如超大模型,但在日常应用中,SmolVLM的表现完全够用,而且响应更快、更私密。
Q2:普通人现在就能使用SmolVLM吗?有什么要求? A:可以使用。研究团队已经开发了HuggingSnap手机应用,还提供了网页版本。用户可以直接在手机上安装应用或通过浏览器访问,不需要特殊的硬件配置。所有代码和模型也都在Hugging Face平台开源,技术人员可以自由下载使用。
Q3:SmolVLM会不会取代现有的大型AI模型? A:不会完全取代,但会形成互补。SmolVLM更适合移动端、边缘计算和个人用户场景,而大型模型在处理极其复杂的任务时仍有优势。未来可能会形成"大模型负责复杂推理,小模型负责日常应用"的分工格局,让AI服务更加多样化和普及化。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

北航大学团队推出Easy Dataset:让普通人也能制作AI训练数据的神奇工具
北航团队推出Easy Dataset框架,通过直观的图形界面和角色驱动的生成方法,让普通用户能够轻松将各种格式文档转换为高质量的AI训练数据。该工具集成了智能文档解析、混合分块策略和个性化问答生成功能,在金融领域实验中显著提升了AI模型的专业表现,同时保持通用能力。项目已开源并获得超过9000颗GitHub星标。

网络安全AI助手:让电脑漏洞危险等级一秒识别的RoBERTa智能系统
卢森堡计算机事件响应中心开发的VLAI系统,基于RoBERTa模型,能够通过阅读漏洞描述自动判断危险等级。该系统在60万个真实漏洞数据上训练,准确率达82.8%,已集成到实际安全服务中。研究采用开源方式,为网络安全专家提供快速漏洞风险评估工具,有效解决了官方评分发布前的安全决策难题。

人工智能评判官:xVerify如何解决复杂推理模型的评估难题
中国电信研究院等机构联合开发的xVerify系统,专门解决复杂AI推理模型的评估难题。该系统能够准确判断包含多步推理过程的AI输出,在准确率和效率方面均超越现有方法,为AI评估领域提供了重要突破。

只需输入音频就能生成说话人视频?昆仑集团推出的Skywork R1V让AI同时看懂图片和推理数学
昆仑公司Skywork AI团队开发的Skywork R1V模型,成功将文本推理能力扩展到视觉领域。该模型仅用380亿参数就实现了与大型闭源模型相媲美的多模态推理性能,在MMMU测试中达到69.0分,在MathVista获得67.5分,同时保持了优秀的文本推理能力。研究团队采用高效的多模态迁移、混合优化框架和自适应推理链蒸馏三项核心技术,成功实现了视觉理解与逻辑推理的完美结合,并将所有代码和权重完全开源。

北航大学团队推出Easy Dataset:让普通人也能制作AI训练数据的神奇工具

网络安全AI助手:让电脑漏洞危险等级一秒识别的RoBERTa智能系统

人工智能评判官:xVerify如何解决复杂推理模型的评估难题

只需输入音频就能生成说话人视频?昆仑集团推出的Skywork R1V让AI同时看懂图片和推理数学
