 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
复旦大学团队让AI对话快10倍:像扔掉旧衣服一样清理计算机"记忆"
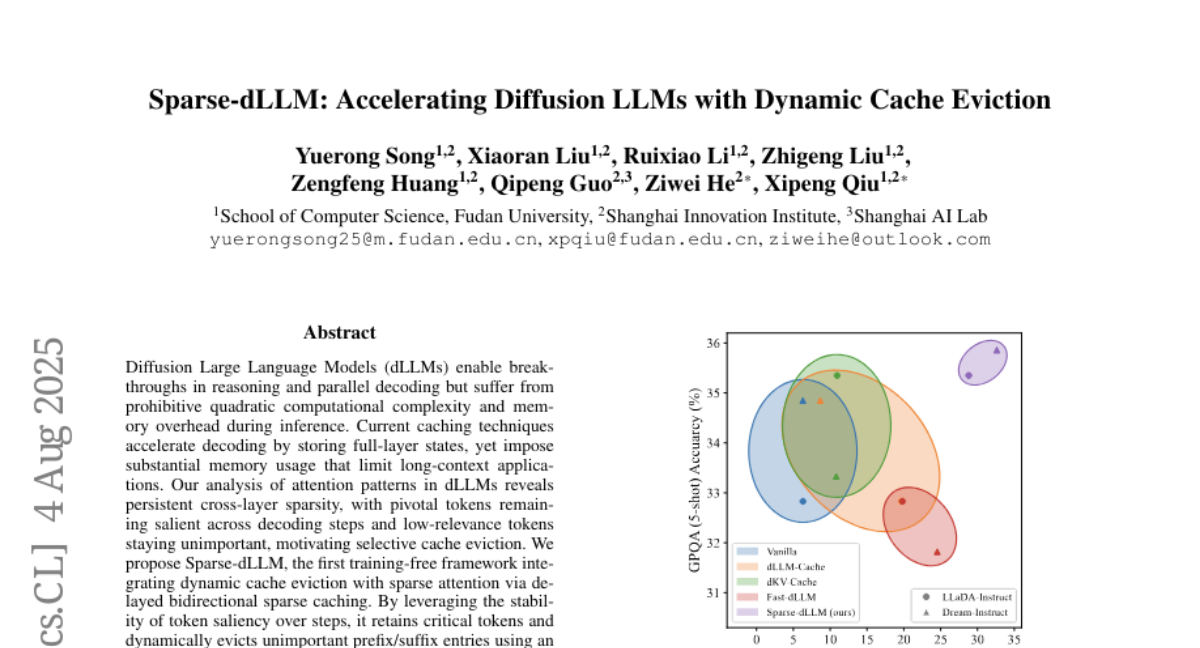
这项由复旦大学计算机科学学院的宋雨容、刘晓然等研究者领导的研究发表于2025年8月,论文名为《Sparse-dLLM: Accelerating Diffusion LLMs with Dynamic Cache Eviction》。有兴趣深入了解的读者可以通过arXiv:2508.02558v1访问完整论文。研究团队还包括来自上海创新研究院和上海AI实验室的科研人员,体现了产学研的深度合作。
当你和朋友聊天时,是不是会发现有些话题特别重要,需要反复提及,而有些闲聊内容很快就被遗忘了?计算机在处理语言时其实也面临类似的问题。最近几年,一种叫做"扩散大语言模型"的AI技术变得非常热门,它就像一个非常聪明的对话伙伴,不仅能进行复杂推理,还能同时处理多个任务。但这种技术有个大问题:它太慢了,而且消耗的计算资源多得惊人。
为了理解这个问题,我们可以把AI处理语言的过程想象成一个图书管理员在巨大的图书馆里工作。传统的AI就像一个效率很高的管理员,它按顺序一本一本地处理书籍,每次只能看前面已经处理过的书。而扩散大语言模型就像一个能力更强的管理员,它可以同时看到整个图书馆的所有书籍,并且能够反复审视和调整自己的理解。这种能力让它在处理复杂问题时表现出色,但也带来了巨大的工作量。
具体来说,当处理一段包含L个词的文本时,传统AI的计算量大约是L个单位,而扩散大语言模型的计算量却是L的平方,也就是L?个单位。如果文本长度翻倍,传统AI的工作量也翻倍,但扩散模型的工作量却要增加四倍。这就解释了为什么扩散大语言模型虽然能力强大,但在实际应用中速度却比传统AI慢得多。
为了解决这个问题,研究人员开始尝试一种叫做"缓存"的技术。这就像图书管理员不再每次都重新整理所有书架,而是把经常用到的书放在手边,需要时直接取用。这种方法确实能加快处理速度,但又引入了新的问题:存储这些"常用书籍"需要大量的存储空间,当处理很长的文本时,所需的存储空间会变得极其庞大,甚至超出了计算机的承受能力。
复旦大学的研究团队通过仔细观察发现了一个有趣的现象。他们发现AI在处理语言时的"注意力模式"非常像人类的注意力分配:总有一些信息特别重要,会被反复关注,而另一些信息相对不那么重要,很少被提及。更重要的是,这种重要性分配在整个处理过程中相当稳定——一开始重要的信息往往会一直重要,一开始不重要的信息通常也会一直不重要。
基于这个观察,研究团队提出了一个巧妙的解决方案,他们称之为Sparse-dLLM。这个方法的核心思想就像一个聪明的衣柜管理系统:定期清理那些很少穿的衣服,只保留经常使用的衣物,这样既节省了空间,又不影响日常需求。
一、智能识别:找出真正重要的信息
Sparse-dLLM的第一个创新在于它能够智能地识别哪些信息真正重要。就像一个经验丰富的图书管理员能够判断哪些书籍经常被借阅一样,这个系统通过分析AI的"注意力分数"来判断每个词语的重要程度。
在传统的缓存方法中,系统只能处理已经出现过的信息,就像只能整理已经读过的书籍。而Sparse-dLLM的独特之处在于它采用了"双向稀疏化"的策略,不仅能处理前面的信息,还能同时考虑后面即将出现的信息。这就像一个全能的管理员,既能记住之前处理过的内容,也能预见接下来可能需要的资料。
系统的工作方式非常巧妙。它会把正在处理的文本分成若干个"块",每个块包含大约32个词语。当处理当前块时,系统会同时分析前面所有块和后面所有块中词语的重要性。通过计算每个词语与当前处理内容的关联度,系统能够生成一个"重要性评分"。
为了确保评估的准确性,研究团队还引入了一个叫做"最大池化"的技术。这个技术就像使用放大镜来观察细节一样,它会将相邻词语的重要性信息进行综合分析,避免因为局部信息不完整而做出错误判断。通过这种方法,系统可以更准确地识别出真正重要的信息。
最终,系统会根据预设的"保留比例"(通常是50%)来决定保留哪些信息。这就像整理衣柜时决定保留一半最常穿的衣服,扔掉另一半很少穿的衣服。这个过程是动态进行的,随着处理的进行不断调整,确保始终保留最有价值的信息。
二、延迟更新:让系统更加稳定可靠
研究团队发现的另一个重要问题是"缓存稳定性"。通过大量实验,他们观察到一个有趣的现象:当AI开始处理一个新的文本块时,最初几步的判断往往不够稳定,就像刚开始阅读一本新书时,我们对内容的理解还不够深入。
为了解决这个问题,团队提出了"延迟缓存更新"的策略。这个策略的核心思想是给系统一点时间来"冷静思考"。具体来说,当AI开始处理一个新的文本块时,系统不会立即更新缓存,而是会等待一个处理步骤,让AI对新内容有了更稳定的理解后再进行缓存操作。
这种延迟策略就像买股票时的"冷静期"概念。当股市出现波动时,明智的投资者不会立即做出买卖决定,而是会观察一段时间,等市场稍微稳定后再采取行动。同样,AI系统也需要这样的"冷静时间"来确保做出正确的判断。
通过对比实验,研究团队发现这种一步延迟的策略在准确性和效率之间达到了最佳平衡。延迟时间太短,系统判断不够稳定;延迟时间太长,又会影响整体处理速度。一步延迟正好在两者之间找到了最优解。
三、动态管理:像整理房间一样管理缓存
Sparse-dLLM的缓存管理策略就像一个井井有条的房间整理系统。整个过程被设计成三个不同的状态,每个状态对应不同的处理策略。
第一个状态可以称为"全面分析状态"。在这个状态下,系统会对整个文本进行完整的分析,就像刚搬进新房时需要仔细查看每个角落一样。这个阶段系统不使用任何缓存,而是对所有信息进行全面处理,为后续的缓存策略奠定基础。
第二个状态是"缓存更新状态"。在这个状态下,系统会根据前面描述的智能识别方法来更新缓存内容。这就像定期整理房间,决定哪些物品应该放在容易取用的地方,哪些物品可以收纳到储物间。系统会保留最重要的信息,同时清理掉那些不太重要的内容。
第三个状态是"缓存复用状态"。在这个状态下,系统主要使用已经准备好的缓存内容进行处理,就像日常生活中直接使用已经整理好的物品一样。这个状态下的处理速度最快,因为系统不需要重新分析所有信息,只需要处理当前的新内容并结合缓存中的重要信息。
这种三状态管理机制的巧妙之处在于它的适应性。当AI遇到完全新的文本段落时,它会切换到全面分析状态;当需要更新理解时,它会进入缓存更新状态;而在大部分时间里,它都在高效的缓存复用状态下工作。
四、性能突破:速度提升效果显著
研究团队在多个知名的AI测试集上验证了Sparse-dLLM的效果,结果令人印象深刻。他们测试了包括LLaDA和Dream系列在内的多个先进的扩散大语言模型,涵盖了数学推理、科学知识、代码编写等多个领域。
在处理速度方面,Sparse-dLLM展现出了卓越的性能。以数学问题求解为例,原本的AI系统每秒只能处理4.57个词语,而使用Sparse-dLLM后,处理速度提升到了26.45个词语每秒,速度提升了近6倍。在某些科学问题测试中,速度提升甚至达到了5.2倍。总体而言,Sparse-dLLM在不同测试场景下都实现了3到10倍的速度提升。
更重要的是,这种速度提升并没有以牺牲准确性为代价。在大多数测试中,使用Sparse-dLLM的AI系统不仅运行更快,回答问题的准确率还略有提升。这就像一个效率更高的图书管理员,不仅工作速度更快,查找资料的准确性也更高。
在内存使用方面,Sparse-dLLM也表现出色。传统的缓存方法虽然能提升速度,但往往需要消耗大量额外的存储空间。而Sparse-dLLM通过智能的信息筛选,将内存消耗控制在了与原始系统几乎相同的水平。这意味着用户可以享受更快的处理速度,而不必担心计算机内存不足的问题。
五、长文本处理:解决实际应用中的关键挑战
在实际应用中,AI系统经常需要处理很长的文本,比如完整的学术论文、长篇小说或者详细的技术文档。这种长文本处理一直是扩散大语言模型面临的最大挑战之一,因为随着文本长度的增加,计算复杂度和内存需求都会急剧增长。
研究团队专门针对这个挑战进行了压力测试。他们使用了包含4000个词语的长文本来测试不同方法的表现。结果显示,Sparse-dLLM在处理长文本时的优势更加明显。当其他方法因为内存不足而无法运行时,Sparse-dLLM仍然能够稳定工作,并且保持了优异的处理速度。
特别值得注意的是,Sparse-dLLM的内存增长曲线几乎是平缓的。这意味着无论文本长度如何增加,系统的内存消耗增长都非常有限。相比之下,其他缓存方法的内存消耗会随着文本长度急剧增加,很快就会超出普通计算机的承受能力。
这种长文本处理能力对实际应用具有重要意义。比如在处理法律文档、医学论文或者大型项目报告时,AI系统需要理解和分析大量相互关联的信息。Sparse-dLLM的能力让这些应用场景变得更加现实可行。
六、参数调优:找到最佳平衡点
为了让Sparse-dLLM达到最佳性能,研究团队进行了大量的参数调优实验。他们主要关注两个关键参数:保留比例和处理窗口大小。
保留比例决定了系统应该保留多少比例的信息。研究团队测试了从10%到90%的不同保留比例,发现50%是一个非常好的平衡点。保留比例太低(比如只保留10%的信息),系统虽然运行很快,但准确性会明显下降,就像扔掉了太多重要物品的衣柜整理。保留比例太高(比如保留90%的信息),准确性提升有限,但内存消耗和处理时间会显著增加,失去了优化的意义。
处理窗口大小影响着系统分析信息的精细程度。研究团队发现,大小为3的处理窗口能够在准确性和效率之间达到最佳平衡。窗口太小会错过重要的上下文信息,窗口太大则会引入过多的噪声信息。
这些参数的选择体现了工程优化的智慧。就像调节汽车引擎一样,每个参数的微调都可能影响整体性能。研究团队通过系统性的实验找到了这些最优参数,为后续的实际应用提供了可靠的配置指南。
七、方法比较:突出独特优势
为了证明Sparse-dLLM的优越性,研究团队将其与多种现有方法进行了详细比较。这些对比方法包括传统的缓存策略、单向稀疏化方法以及其他加速技术。
与传统缓存方法相比,Sparse-dLLM的最大优势在于其双向处理能力。传统方法只能基于已经处理过的信息做出缓存决策,就像只能根据已经读过的书页来整理书架。而Sparse-dLLM能够同时考虑前后文信息,做出更加明智的保留决策。
与单向稀疏化方法相比,Sparse-dLLM在处理复杂任务时表现更加稳定。单向方法在处理数学问题时准确率会有所下降,而Sparse-dLLM不仅保持了准确率,在某些任务上甚至有所提升。这说明双向信息分析确实能够帮助系统更好地理解文本内容。
与其他加速技术相比,Sparse-dLLM在内存效率方面具有明显优势。其他方法虽然也能提升处理速度,但往往需要消耗更多内存,限制了其在长文本处理中的应用。Sparse-dLLM既实现了速度提升,又控制了内存消耗,是一个更加实用的解决方案。
八、技术原理:深入理解工作机制
Sparse-dLLM的核心技术原理可以用一个精密的信息过滤系统来理解。这个系统包含几个相互协作的组件,每个组件都有其特定的功能。
首先是注意力分析组件。这个组件的工作原理类似于一个经验丰富的编辑,能够快速识别文章中最重要的段落和句子。它通过计算每个词语与当前处理内容的"关联强度"来评估信息的重要性。关联强度高的词语被认为是重要信息,需要保留在缓存中;关联强度低的词语则被认为是次要信息,可以被清理掉。
其次是动态评估组件。这个组件负责实时监控信息重要性的变化。虽然研究发现信息的重要性相对稳定,但在某些情况下仍然可能发生变化。动态评估组件就像一个持续监控的传感器,确保系统能够适应这些变化。
第三是缓存管理组件。这个组件负责具体的缓存操作,包括信息的存储、更新和清理。它就像一个智能仓库管理系统,能够高效地组织和维护缓存内容,确保重要信息随时可用,同时及时清理过时信息。
最后是状态协调组件。这个组件负责协调不同处理状态之间的切换,确保整个系统在不同情况下都能选择最合适的处理策略。它就像一个智能指挥中心,根据当前情况决定系统应该采用哪种工作模式。
九、实验验证:全面测试系统可靠性
研究团队设计了一套全面的实验方案来验证Sparse-dLLM的可靠性和实用性。这些实验覆盖了多个维度,包括不同类型的任务、不同长度的文本、不同规模的模型等。
在任务类型方面,实验涵盖了常识推理、数学计算、科学问题、代码编程等多个领域。这种全面的测试确保了Sparse-dLLM不是只在某个特定领域表现良好,而是具有广泛的适用性。结果显示,在所有测试领域中,Sparse-dLLM都能够提供稳定的性能提升。
在文本长度方面,实验测试了从几百词到几千词的不同长度文本。随着文本长度的增加,Sparse-dLLM的优势变得更加明显。这证明了该方法特别适合处理实际应用中常见的长文本任务。
在模型规模方面,实验测试了从15亿参数到80亿参数的不同规模模型。结果表明,Sparse-dLLM的优化效果与模型规模无关,既适用于较小的模型,也适用于大型模型。这种通用性使得该方法具有广泛的应用前景。
研究团队还进行了稳定性测试,通过多次重复实验来验证结果的可靠性。实验结果的标准差很小,说明Sparse-dLLM的性能非常稳定,不会因为随机因素而出现大幅波动。
十、应用前景:开启AI应用新可能
Sparse-dLLM的技术突破为AI应用开辟了新的可能性。在教育领域,更快的AI系统可以为学生提供实时的学习辅导,处理复杂的学术问题。在医疗领域,AI可以更高效地分析长篇医学文献,为医生提供准确的诊断建议。在法律领域,AI可以快速处理大量法律文档,协助律师进行案例分析。
对于普通用户而言,这项技术的最直接影响是AI助手的响应速度大幅提升。无论是处理长篇文档、进行复杂推理还是回答详细问题,AI系统都能够提供更快、更准确的服务。这将使AI技术在日常工作和生活中变得更加实用。
从技术发展的角度来看,Sparse-dLLM代表了AI优化技术的一个重要方向。它不是通过增加计算资源来提升性能,而是通过更智能的资源使用来实现优化。这种思路对于推动AI技术的普及和应用具有重要意义。
研究团队已经将Sparse-dLLM设计成一个"即插即用"的解决方案,这意味着开发者可以很容易地将这项技术集成到现有的AI系统中。这种易用性将加速该技术的推广和应用。
说到底,复旦大学团队的这项研究解决了扩散大语言模型实用化的一个关键障碍。通过巧妙的缓存管理策略,他们让AI系统既能保持强大的能力,又能实现高效的运行。这就像为一辆强大但耗油的超级跑车安装了先进的节能系统,既保持了卓越性能,又提高了燃油效率。
这项技术的真正价值在于它的实用性和普适性。它不需要重新训练AI模型,不需要特殊的硬件设备,只需要通过软件优化就能实现显著的性能提升。这种"不重新发明轮子"的优化思路,为AI技术的发展提供了新的启示:有时候,智能的资源管理比增加资源更重要。
对于整个AI行业来说,Sparse-dLLM的成功表明,在追求更大、更强的AI模型的同时,优化现有技术的效率同样重要。这种平衡发展的思路,可能会引导AI研究走向更加可持续和实用的方向。有兴趣深入了解技术细节的读者,可以通过arXiv:2508.02558v1获取完整的研究论文。
Q&A
Q1:Sparse-dLLM技术是什么?它能解决什么问题?
A:Sparse-dLLM是复旦大学团队开发的一种AI加速技术,专门用于提升扩散大语言模型的运行速度。它通过智能缓存管理,像整理衣柜一样清理不重要的信息,保留关键内容,从而将AI对话速度提升3-10倍,同时几乎不增加内存消耗。
Q2:这项技术与现有的AI加速方法有什么不同?
A:Sparse-dLLM的独特之处在于采用双向稀疏化策略,既能处理前面的信息,也能考虑后面即将出现的信息,就像一个全能管理员。传统方法只能基于已处理的信息做决策,而Sparse-dLLM能同时分析前后文,做出更明智的信息保留决策。
Q3:普通用户什么时候能体验到这项技术带来的改进?
A:由于Sparse-dLLM被设计成"即插即用"的解决方案,开发者可以很容易地将其集成到现有AI系统中。这意味着用户可能很快就能在各种AI应用中体验到响应速度的显著提升,特别是在处理长文档、复杂推理等任务时。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站


大语言模型为什么老是"胡编乱造"?OpenAI团队揭开AI幻觉的真相
OpenAI团队的最新研究揭示了大语言模型产生幻觉的根本原因:AI就像面临难题的学生,宁愿猜测也不愿承认无知。研究发现,即使训练数据完全正确,统计学原理也会导致AI产生错误信息。更重要的是,现有评估体系惩罚不确定性表达,鼓励AI进行猜测。研究提出了显式置信度目标等解决方案,通过改革评估标准让AI学会诚实地说"不知道",为构建更可信的AI系统指明方向。

ByteDance AI实验室发布重磅研究:让计算机学会"逆向思考",解决创意写作难题
字节跳动AI实验室提出"逆向工程推理"新范式,通过从优质作品反推思考过程的方式训练AI进行创意写作。该方法创建了包含2万个思考轨迹的DeepWriting-20K数据集,训练的DeepWriter-8B模型在多项写作评测中媲美GPT-4o等顶级商业模型,为AI在开放性创意任务上的应用开辟了新道路。

电脑终于学会了像人类一样用键盘鼠标:ByteDance推出会玩游戏的AI助手
ByteDance Seed团队开发的UI-TARS-2是一个革命性的AI助手,能够通过观看屏幕并用鼠标键盘操作电脑,就像人类一样完成各种任务和游戏。该系统采用创新的"数据飞轮"训练方法,在多项测试中表现出色,游戏水平达到人类的60%左右,在某些电脑操作测试中甚至超越了知名AI产品,展现了AI从对话工具向真正智能助手演进的巨大潜力。

阿里要用AI将云计算重做一遍

大语言模型为什么老是"胡编乱造"?OpenAI团队揭开AI幻觉的真相

ByteDance AI实验室发布重磅研究:让计算机学会"逆向思考",解决创意写作难题

电脑终于学会了像人类一样用键盘鼠标:ByteDance推出会玩游戏的AI助手
