 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
看不见摸不着的虚假声音,为何让我们的大脑如此"上当"?——卡迪夫大学解密语音感知新机制
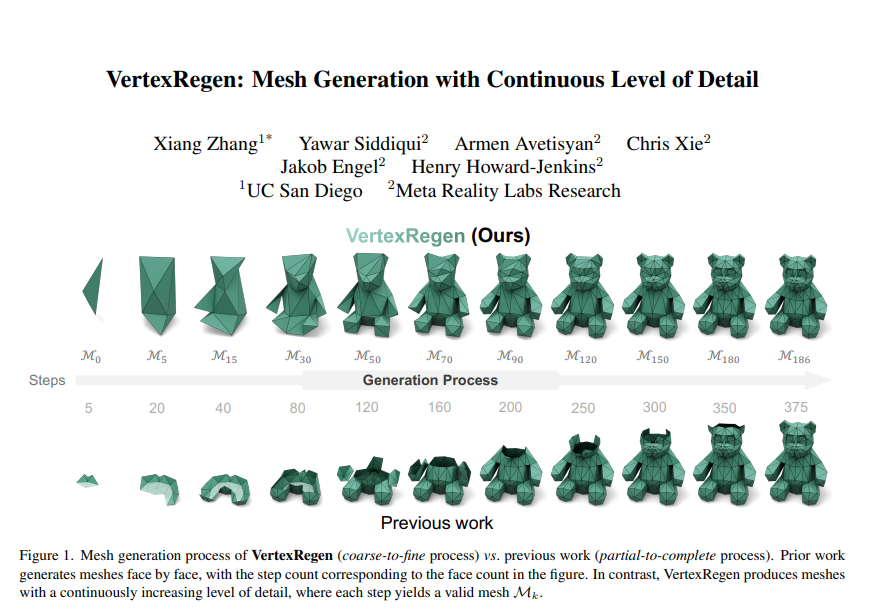
这项由英国卡迪夫大学心理学院的研究团队发表在2024年《认知科学》期刊上的研究,揭示了一个令人意外的发现:当我们听到虚假的语音信号时,大脑的反应竟然和听到真实声音时几乎一样。这项研究的主要作者包括该校的认知神经科学专家们,他们通过精巧的实验设计,为我们打开了理解人类语音感知机制的新窗口。对这一领域感兴趣的读者,可以通过该期刊的官方网站查阅完整论文。
说起来,我们每天都在进行一项看似简单却极其复杂的活动——听懂别人说话。然而,你可曾想过,当周围环境嘈杂,或者信号不清晰时,我们的大脑是如何"补全"那些缺失的语音信息的?更有趣的是,有时候我们明明"听到"了某个词,但实际上那个声音根本不存在,这究竟是怎么回事?
卡迪夫大学的研究团队决定深入探索这个谜题。他们发现,人类的听觉系统就像一位经验丰富的修复师,能够根据上下文线索,在我们的脑海中"重建"那些实际上并不存在的语音片段。更令人惊讶的是,这种虚假的听觉体验在大脑中引发的神经活动,与真实听到声音时的反应模式竟然高度相似。
这一发现不仅仅是学术上的突破,它还能帮助我们理解为什么有些人在嘈杂环境中听懂对话比其他人更困难,为什么某些听觉障碍患者会出现"幻听"现象,以及为什么我们有时会在根本没有声音的情况下"听到"手机铃声。研究团队通过一系列巧妙的实验,让参与者体验这种"虚假听觉",同时用先进的脑电图技术记录他们的大脑活动,从而揭示了这一现象背后的神经机制。
一、当大脑成为"声音魔术师"——虚假听觉的神奇世界
要理解这项研究,我们首先需要认识一个奇妙的现象:有时候,我们会"听到"实际上并不存在的声音。这听起来可能有些不可思议,但实际上,这种情况在我们的日常生活中经常发生。
研究团队选择了一个特别有趣的实验场景来展现这种现象。他们让参与者听一段经过特殊处理的录音,其中某些关键的语音片段被完全删除,取而代之的是一些无关的噪音,比如咳嗽声。神奇的是,当人们听到这样的录音时,他们的大脑会自动"填补"那些缺失的声音,让他们感觉自己听到了完整的句子。
这就好比你在看一幅被部分遮挡的图画,虽然某些部分被遮住了,但你的大脑会根据可见的部分推测出完整的图像。同样,当语音信号不完整时,我们的听觉系统会根据上下文和语言经验,在脑海中"重建"那些缺失的声音片段。
更有趣的是,这种"虚假听觉"的体验是如此真实,以至于参与者往往坚信自己确实听到了那些被删除的声音。他们会告诉研究人员,录音听起来完全正常,没有任何缺失的地方。这说明,大脑的这种"补全"机制不仅存在,而且运作得相当完美,几乎可以欺骗我们的意识。
卡迪夫大学的研究团队意识到,这种现象为理解人类语音感知提供了一个独特的窗口。通过研究大脑如何处理这些"虚假"的听觉体验,他们可以更好地理解正常听觉处理的机制,以及当这些机制出现问题时会发生什么。
二、解码大脑的"声音密码"——神经活动的秘密揭示
为了深入了解这种虚假听觉现象背后的神经机制,研究团队采用了一种名为脑电图的技术,这种技术能够实时监测大脑的电活动。可以把脑电图想象成大脑的"心电图"——就像心电图能显示心脏的跳动模式一样,脑电图能够显示大脑不同区域的活动模式。
研究团队精心设计了一系列实验条件。他们准备了三种不同的声音材料:第一种是完整的、未经处理的语音录音;第二种是被噪音(如咳嗽声)替换了部分内容的录音,但听起来仍然像完整的句子;第三种是同样被噪音替换了内容,但听起来明显不完整的录音。
通过比较参与者在听这三种不同录音时的脑电图反应,研究团队发现了一个令人震惊的结果:当人们体验到虚假听觉时(即听被噪音替换但感觉完整的录音时),他们的大脑活动模式与听到真实完整语音时的模式几乎一模一样。
这个发现就像是在大脑中发现了一个"声音魔术师"。这个魔术师不仅能够创造出不存在的声音,而且能够让整个大脑相信这些声音是真实存在的。更具体地说,研究团队观察到,当虚假听觉发生时,大脑中负责语音处理的区域会产生与处理真实语音时相同的神经反应模式。
特别值得注意的是,这种神经反应不仅仅局限于听觉皮层(大脑中专门处理声音的区域),还扩展到了语言理解和语音产生相关的脑区。这表明,虚假听觉不是一个简单的听觉错觉,而是涉及整个语言处理网络的复杂现象。
研究团队还发现,这种神经反应的强度和模式与参与者对虚假听觉体验的主观感受高度相关。换句话说,那些报告听到"更清晰"虚假声音的参与者,他们的大脑反应也更接近听到真实声音时的反应。这进一步证实了大脑在创造这些虚假听觉体验时的精确性和一致性。
三、语言经验的力量——为什么有些"空白"我们能填补
深入分析实验结果后,研究团队发现了虚假听觉现象背后的一个关键机制:我们的语言经验和知识在其中发挥着至关重要的作用。这就好比一位经验丰富的拼图高手,即使缺少几块拼图片,也能根据现有的片段推断出完整图案的样子。
研究团队注意到,并不是所有被噪音替换的语音片段都能引发虚假听觉。只有当缺失的部分能够被参与者的语言知识合理"预测"时,大脑才会进行这种自动补全。例如,如果一个常见的词汇中间的音节被咳嗽声替换,而这个词在语境中具有高度的可预测性,那么听者就更容易体验到虚假听觉。
这个发现揭示了人类语言处理的一个重要特征:我们的大脑不是被动地接收和处理声音信号,而是主动地运用我们的语言知识和经验来理解和"完善"我们听到的内容。这种主动的处理方式使我们能够在嘈杂的环境中更好地理解对话,即使某些声音被环境噪音掩盖。
研究团队进一步验证了这一点,他们发现当被替换的语音片段在语境中的可预测性较低时,参与者就不太容易体验到虚假听觉,相应的神经反应也会减弱。这说明,大脑的"声音补全"机制不是随意的,而是基于语言规律和概率的精确计算。
更有趣的是,研究团队发现不同的人对同样的刺激可能会有不同的反应。那些语言能力更强、词汇量更丰富的参与者,往往能够体验到更强烈和更准确的虚假听觉。这表明,我们的语言经验越丰富,大脑的"补全"能力就越强。
四、从实验室到现实生活——虚假听觉的实际意义
这项研究的意义远远超出了学术实验室的范围。事实上,虚假听觉现象在我们的日常生活中无处不在,只是我们通常没有意识到它的存在。
在嘈杂的餐厅里与朋友聊天时,我们经常能够理解对方的话语,即使某些音节被周围的噪音完全掩盖。这正是大脑虚假听觉机制在发挥作用。我们的听觉系统会根据能够听清的部分,结合语境和语言知识,在脑海中"重建"那些被噪音掩盖的声音。
对于有听力障碍的人群来说,这一发现具有特别重要的意义。研究表明,某些类型的听力问题可能会影响大脑的这种"补全"能力,导致患者在理解不完整的语音信号时遇到更大困难。理解这一机制有助于开发更有效的听力康复方法和辅助技术。
这项研究还为我们理解某些神经系统疾病提供了新的视角。例如,一些精神分裂症患者会出现听觉幻觉,即听到实际上不存在的声音。虽然这种病理性的听觉幻觉与实验中观察到的虚假听觉在性质上有所不同,但它们可能涉及类似的神经机制。通过研究正常的虚假听觉现象,科学家们可能能够更好地理解和治疗这些疾病。
在技术应用方面,这一研究对语音识别和人工智能系统的发展也具有启发意义。目前的语音识别系统在处理不完整或有噪音的语音信号时,往往表现不如人类。如果能够模拟人脑的这种"补全"机制,可能会显著提高人工智能系统的语音理解能力。
此外,这项研究还为语言学习和教育提供了有价值的见解。它表明,我们的语言理解能力不仅依赖于准确的声音感知,还依赖于丰富的语言知识和经验。这提示我们,在语言教学中,不仅要注重发音的准确性,还要帮助学习者建立丰富的语言知识网络,以增强他们在实际交流中的理解能力。
五、未来的探索方向——开启听觉研究新篇章
卡迪夫大学的这项研究虽然揭示了虚假听觉现象的一些重要特征,但同时也提出了许多新的问题,为未来的研究指明了方向。
研究团队认为,下一步需要更深入地了解这种虚假听觉机制在不同人群中的变异性。例如,儿童的虚假听觉能力与成人是否相同?不同语言背景的人是否会表现出不同的虚假听觉模式?这些问题的答案将有助于我们更全面地理解人类语言处理的发展和变化规律。
另一个重要的研究方向是探索虚假听觉与其他认知能力之间的关系。研究团队推测,虚假听觉能力可能与工作记忆、注意力控制和语言流畅性等认知能力密切相关。如果这一推测得到证实,那么虚假听觉测试可能成为评估认知能力的一个新工具。
在技术应用方面,研究团队设想将这一发现应用于改进助听器和人工耳蜗等听力辅助设备。传统的助听设备主要关注信号的放大和降噪,但如果能够模拟大脑的虚假听觉机制,可能会帮助使用者更好地理解不完整的语音信号。
研究团队还计划利用更先进的神经成像技术,如功能性磁共振成像,来更精确地定位和分析虚假听觉相关的大脑活动。这将有助于绘制出更详细的"虚假听觉神经网络图",为理解这一现象的神经基础提供更丰富的信息。
从临床角度来看,这项研究可能为诊断和治疗某些听觉和语言障碍开辟新途径。通过评估患者的虚假听觉能力,医生可能能够更准确地诊断问题所在,并制定更有针对性的治疗方案。
说到底,卡迪夫大学的这项研究为我们打开了理解人类听觉和语言处理的新窗口。它揭示了我们的大脑不仅是一个高效的信息处理器,更是一个创造性的"艺术家",能够在缺失信息的基础上创造出完整的感知体验。这种能力不仅帮助我们在复杂的声音环境中更好地交流,也展现了人类认知系统的精妙和复杂。
随着研究的深入,我们有理由相信,这一发现将为改善听力障碍患者的生活质量、提高人工智能系统的性能,以及加深我们对人类认知本质的理解做出重要贡献。对于每一个对人类大脑奥秘感兴趣的人来说,这项研究都提醒我们:我们每天进行的看似简单的听觉活动,实际上涉及着极其复杂而精妙的神经机制。如果您想了解更多技术细节,建议查阅发表在《认知科学》期刊上的完整论文。
Q&A
Q1:什么是虚假听觉现象?它在日常生活中常见吗?
A:虚假听觉是指我们"听到"实际上并不存在的声音的现象。当语音中某些片段被噪音替换时,大脑会根据上下文自动"填补"缺失的声音,让我们感觉听到了完整的话语。这种现象在日常生活中很常见,比如在嘈杂环境中聊天时,我们经常能理解被噪音掩盖的词语。
Q2:虚假听觉现象的发生需要什么条件?
A:虚假听觉的发生主要依赖于语言经验和上下文的可预测性。只有当缺失的语音片段能够被我们的语言知识合理预测时,大脑才会进行自动补全。词汇量丰富、语言能力强的人往往能体验到更强烈的虚假听觉。
Q3:这项研究对听力障碍患者有什么帮助?
A:这项研究揭示了大脑处理不完整语音信号的机制,有助于开发更有效的听力康复方法。某些听力问题可能影响大脑的"补全"能力,理解这一机制可以帮助改进助听器等设备,让它们不仅放大声音,还能模拟大脑的补全功能。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

从“互联”到“智联”:荣耀MagicOS 10如何用“自进化”重构人机关系?
过去十年,终端厂商比拼的是“性能”和“参数”,如今,竞争的焦点正转向“智能程度”。


让AI学会深度搜索:Fractal AI Research实验室开发出能像侦探一样追踪真相的智能助手
Fractal AI Research实验室开发了Fathom-DeepResearch智能搜索系统,该系统由两个4B参数模型组成,能够进行20多轮深度网络搜索并生成结构化报告。研究团队创新了DUETQA数据集、RAPO训练方法和认知行为奖励机制,解决了AI搜索中的浅层化、重复性和缺乏综合能力等问题,在多项基准测试中显著超越现有开源系统,为AI助手向专业研究工具转变奠定了基础。

快手科技重磅突破:AI语言模型训练的"权重平衡术"让机器学习更聪明
快手科技与清华大学合作发现当前AI语言模型训练中存在严重的权重分配不平衡问题,提出了非对称重要性采样策略优化(ASPO)方法。该方法通过翻转正面样本的重要性权重,让模型把更多注意力放在需要改进的部分而非已经表现良好的部分,显著提升了数学推理和编程任务的性能,并改善了训练稳定性。

从“互联”到“智联”:荣耀MagicOS 10如何用“自进化”重构人机关系?

开源红帽,加速AI

让AI学会深度搜索:Fractal AI Research实验室开发出能像侦探一样追踪真相的智能助手

快手科技重磅突破:AI语言模型训练的"权重平衡术"让机器学习更聪明
