 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
微软亚洲研究院重磅突破:让大模型用上4位浮点数训练,算力压缩四分之三
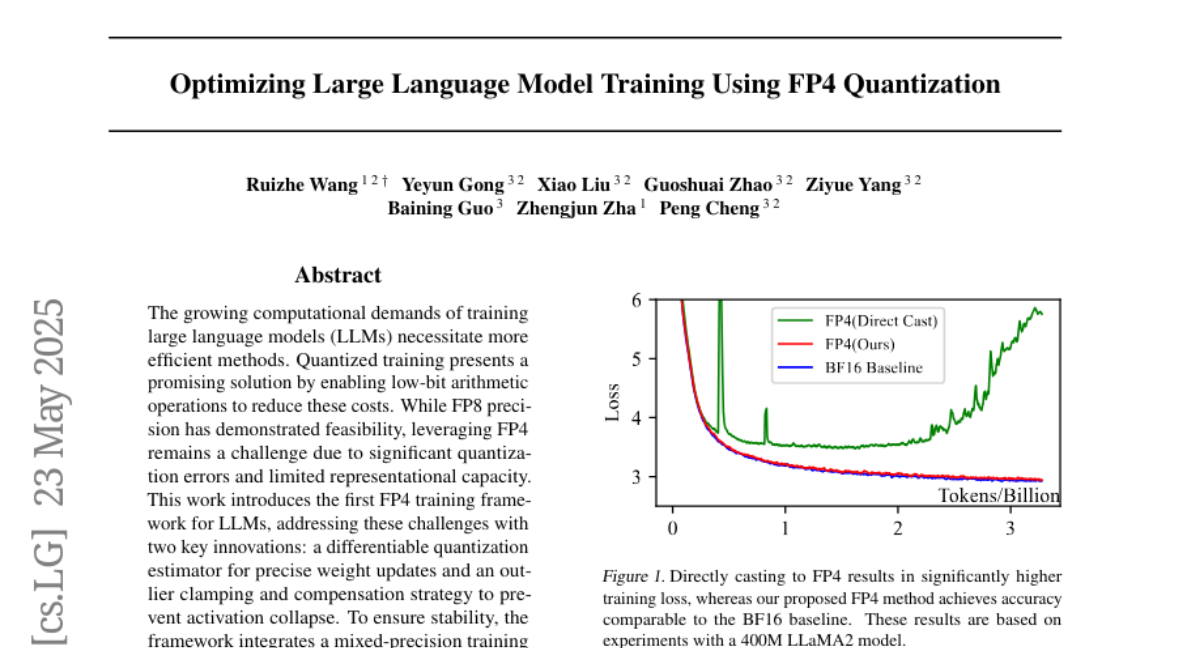
这项由微软亚洲研究院的龚也筠和程鹏等研究人员领导的开创性研究发表于2025年在加拿大温哥华举行的第42届国际机器学习会议(ICML)。有兴趣深入了解的读者可以通过论文地址 arXiv:2501.17116v2 访问完整论文。
当下的大型语言模型训练就像在建造一座摩天大楼,需要消耗惊人的资源。以Meta的Llama 3 405B为例,这个庞然大物需要在16000块H100显卡上连续跑54天才能训练完成,消耗的电力足够一座小城市使用数月。而GPT-4这样拥有万亿参数的模型,其训练成本更是天文数字。面对这样的现状,如何在保证模型效果的前提下大幅降低训练成本,成了整个AI行业急需解决的问题。
研究团队就像是在寻找一把能够四两拨千斤的钥匙。他们的目标是让计算机在处理数据时使用更少的"数字精度"——就好比原本需要用精确到小数点后16位的数字来计算,现在只需要4位就够了。这听起来似乎会损失很多精度,但研究团队通过巧妙的技术手段,几乎完全消除了这种损失,同时获得了接近4倍的计算效率提升。
这项研究的创新之处在于,这是首次有人成功实现了FP4(4位浮点数)格式的大型语言模型训练。过去,业界最多只能做到FP8(8位浮点数)训练,而且还要付出一定的精度代价。研究团队不仅实现了更低精度的FP4训练,还保证了训练效果与传统高精度训练几乎相同。他们在高达130亿参数的模型和1000亿个训练样本上验证了这一技术,为未来更加高效的AI训练开辟了全新道路。
一、数字精度的魔术:从16位到4位的惊险跳跃
要理解这项技术的难度,我们可以用摄影来做个比喻。传统的大模型训练就像用专业单反相机拍照,每张照片都有极高的分辨率和色彩深度,能捕捉到最细微的光影变化。而研究团队尝试做的事情,就像是用一台只有16种颜色的古董游戏机屏幕来拍摄同样精美的照片,还要保证最终效果几乎看不出差别。
在计算机的世界里,数字的表示方式就像不同规格的容器。传统的BF16格式就像一个精密的量杯,能够精确测量从一滴水到几升的任何液体量。而FP4格式更像是一个只有16个刻度的简陋量筒,看似无法胜任精密测量的工作。但研究团队通过创新的技术,让这个简陋的量筒也能做出专业级的测量。
FP4格式采用了E2M1的编码方式,这意味着用2个比特来表示数字的"数量级"(就像科学计数法中的指数部分),用1个比特来表示精确的数值。这种设计虽然只能表示16个不同的数值,但覆盖的数值范围却能从-6到+6,这样的设计在有限的比特空间内实现了动态范围和精度的平衡。
当研究团队第一次尝试直接将模型训练从BF16格式转换为FP4格式时,结果就像用放大镜看蚂蚁却看到了大象——训练损失急剧飙升,模型完全无法正常学习。这种现象并不意外,因为4位浮点数的表示能力实在太有限了,大量的数值信息在转换过程中丢失了。
面对这个挑战,研究团队没有放弃,而是开始深入分析问题的根源。他们发现,传统的量化方法就像用生硬的四舍五入来处理所有数字,这种简单粗暴的方式在精度极低的情况下会造成严重的信息损失。于是,他们开始寻找更加智能的解决方案。
二、权重优化的微积分魔法:让梯度计算起死回生
在深度学习的训练过程中,梯度就像登山者手中的指南针,指示着通向最优解的方向。但当使用极低精度的FP4格式时,这个指南针就会出现严重的偏差,甚至完全失灵。研究团队面临的挑战就是如何修复这个"损坏"的指南针。
传统的直通估计器(STE)方法就像给坏掉的指南针简单地校准一下指针,表面上看起来没问题,但实际指示的方向可能完全错误。这种方法假设量化前后的梯度完全相同,这在高精度情况下或许可行,但在FP4这种极低精度下就完全不够用了。
研究团队提出的可微分梯度估计器(DGE)就像给指南针装上了一套精密的校准系统。这个系统不是简单地假设量化不会影响梯度,而是用数学的方法精确计算出量化过程对梯度造成的影响,然后在反向传播时加上一个修正项来补偿这种影响。
具体来说,DGE方法使用一个特殊的数学函数来近似量化过程。这个函数就像一条光滑的曲线,能够很好地模拟阶梯状的量化函数,同时还能计算出精确的导数。函数的形式是:f(x) = δ/2 × (1 + sign(2x/δ - 1) × |2x/δ - 1|^(1/k)),其中δ表示量化间隔,k是控制近似精度的参数。
这个函数的巧妙之处在于,当k值较大时,它几乎与真实的量化函数完全重合,但又能提供连续可微的特性。就像用一条非常接近阶梯的光滑曲线来代替真正的阶梯,既保持了原有的形状特征,又获得了计算导数的能力。
在实际训练中,研究团队发现这个方法的导数在量化区间的中点附近会变得非常大,甚至趋向无穷。为了防止这种"梯度爆炸"现象,他们将导数的最大值限制在3.0。这就像给汽车的油门加上限速器,防止加速度过大导致失控。
通过大量实验验证,DGE方法相比传统的STE方法,在权重量化的准确性上有了显著提升。特别是在处理多层神经网络时,这种改进的累积效应非常明显,最终训练出的模型质量接近全精度训练的水平。
三、激活值的离群点大作战:驯服数据中的"狂野分子"
如果说权重量化像是整理书架上的书籍,那么激活值量化就像是管理一个热闹的菜市场。在书架上,书本大小相对均匀,容易分类摆放;但在菜市场里,有小如豆子的调料,也有大如西瓜的水果,还有各种形状奇异的蔬菜,管理起来复杂得多。
激活值在大型语言模型中就表现出这样的特点。研究团队通过深入分析发现,激活值的分布非常不均匀,大部分值都比较小,聚集在一个较窄的范围内,但总有一些"异常大"的值突然出现,这些就是所谓的离群点。这些离群点就像菜市场里突然出现的一头大象,虽然数量很少,但会严重影响整体的管理秩序。
当使用传统的量化方法时,这些离群点会强迫整个量化系统采用一个非常大的数值范围来容纳它们。结果就是,为了容纳少数几个"大象",整个"菜市场"都要扩建,而原本密集分布的"小商品"们却因为空间变大而变得稀疏,精度大大降低。更糟糕的是,大多数正常的数值在这种扩展后的量化系统中会被舍入为零,造成严重的信息丢失。
为了解决这个问题,研究团队提出了离群点钳制和补偿(OCC)方法。这个方法就像给菜市场制定了一套巧妙的管理规则:首先,对于那些过分巨大的"商品",不允许它们直接进入市场,而是在入口处进行"尺寸限制",将它们切割到合适的大小。
具体的操作方式是通过分位数识别来确定离群点。研究团队选择了99%分位数作为阈值,也就是说,只有最大的1%的数值被认为是离群点。这些被识别出的离群点会被"钳制"到阈值范围内,就像给过高的树枝修剪到合适的高度。
但是,简单的钳制会丢失信息,就像把大西瓜切成小块后,虽然能装进标准的篮子里,但总重量可能会有损失。为了避免这种损失,研究团队引入了补偿机制。他们用一个稀疏矩阵来记录被钳制掉的部分,就像用一个特殊的账本记录所有被"修剪"掉的信息。
在实际计算时,这个系统采用了双轨制处理方式:主要的计算使用经过钳制的激活值,通过高效的FP4计算完成;而被钳制掉的部分则通过高精度的稀疏矩阵计算来处理。由于离群点非常稀少(通常只占总数的1-2%),这种稀疏计算的开销很小,但能够显著提高整体精度。
通过量化分析,研究团队发现这种方法能将激活值的余弦相似度从直接量化的92.19%提升到99.61%,均方误差从0.1055降低到0.0245,信噪比从8.31提升到15.31。这意味着经过OCC处理后的激活值几乎与原始高精度激活值没有区别。
更重要的是,这种方法在实际的模型训练中表现出色。当研究团队尝试仅对激活值进行4位量化时(保持权重为8位),如果不使用OCC方法,训练过程会直接崩溃,损失值变成NaN(非数值)。但使用OCC方法后,训练能够稳定进行,最终收敛到与高精度训练相近的水平。
四、精密工程的协奏曲:混合精度训练的平衡艺术
将FP4量化技术应用到实际的大型语言模型训练中,就像指挥一个庞大的交响乐团,需要让不同的乐器在不同的时机发出不同音高的声音,最终汇聚成和谐的乐章。研究团队面临的挑战不仅仅是让某个单一组件工作,而是要让整个复杂系统协调运行。
在现代的Transformer架构中,矩阵乘法运算占据了超过95%的计算量,这些运算就像交响乐中的主旋律,是整个系统的核心。研究团队将FP4量化主要应用在这些矩阵乘法运算上,同时保持其他运算(如归一化、激活函数等)使用更高的精度。这种做法就像让小提琴组演奏主旋律时使用特殊的演奏技巧来节约体力,而让其他乐器组保持标准演奏方式来确保音质。
在量化的具体实施中,研究团队采用了向量级的量化粒度,而不是简单的张量级量化。这意味着对于激活矩阵,他们按照序列长度维度进行量化;对于权重矩阵,则按照输出通道维度进行量化。这种精细化的处理就像调音师为每个乐器单独调音,而不是对整个乐团使用统一的调音标准。
研究团队还发现,量化的粒度对最终效果有着关键影响。当他们尝试使用更粗糙的张量级量化时,训练效果会显著下降,特别是对激活值进行粗粒度量化时,甚至会导致训练失败。这个发现说明,在极低精度的量化中,细节的处理变得极其重要,就像在精密仪器的制造中,哪怕是微米级的误差都可能导致整个系统失效。
为了验证技术的有效性,研究团队进行了大规模的实验验证。他们使用LLaMA 2架构,在DCLM数据集上训练了1.3B、7B和13B三种不同规模的模型,每个模型都使用1000亿个token进行训练。这相当于让三个不同规模的乐团都演奏同一首复杂的交响曲,来测试新的演奏技巧是否适用于不同的配置。
实验结果令人鼓舞。在1.3B参数的模型上,FP4训练的最终损失为2.55,而BF16训练的损失为2.49,差距仅为0.06。在7B参数模型上,这个差距是0.10(2.17 vs 2.07)。在最大的13B参数模型上,差距仍然控制在0.09(1.97 vs 1.88)。这些结果表明,即使使用了如此激进的量化策略,模型的学习能力几乎没有受到影响。
更重要的是,研究团队在多个下游任务上测试了训练好的模型。这些任务包括常识推理、阅读理解、逻辑推理等多个方面,就像让乐团不仅要会演奏古典音乐,还要能够演奏爵士、摇滚等不同风格的音乐。结果显示,FP4训练的模型在这些任务上的表现与BF16训练的模型几乎相同,有些任务上甚至略有超越。
例如,在1.3B模型上,FP4训练的平均准确率为53.13%,而BF16训练的准确率为53.23%,差距仅为0.10%。在7B模型上,FP4训练的结果甚至略好于BF16(54.42% vs 53.87%)。这些结果有力地证明了FP4训练技术的实用性和可靠性。
五、硬件加速的未来图景:从理论到现实的最后一跃
尽管研究团队在算法和方法上取得了重大突破,但他们也坦诚地指出了当前面临的一个重要限制:现有的硬件还不支持原生的FP4计算。这就像设计出了一种全新的高效汽车发动机,但目前的道路基础设施还无法完全发挥其优势。
目前的实验都是在NVIDIA的H100 GPU上进行的,这些GPU原生支持FP8计算,研究团队通过FP8来模拟FP4的计算过程。虽然这种模拟能够验证算法的正确性,但无法直接体现FP4带来的性能优势。就像在现有的道路上测试新发动机,虽然能证明发动机确实更高效,但无法展现它在专用道路上的全部潜力。
不过,这种情况很快就会改变。NVIDIA即将发布的B200系列GPU将原生支持FP4和FP6计算,这意味着研究团队的技术将能够在真正的硬件上发挥作用。根据理论分析,FP4相比FP8能够提供2倍的计算吞吐量提升,这将带来显著的训练加速。
研究团队还进行了详细的理论性能分析。他们计算了在一个标准的Transformer层中,各个组件在不同精度下的计算量。对于一个典型的7B参数模型,理论上FP4训练相比FP32训练能够获得约3.12倍的加速比。即使考虑到DGE和OCC方法带来的额外计算开销,最终的加速比仍然能够达到2.95倍左右。
这种加速不仅仅意味着训练时间的缩短,更重要的是能源消耗的大幅降低。在当前AI训练消耗巨大的背景下,这种技术的普及将对整个行业产生深远影响。一个需要在16000块GPU上训练54天的模型,使用FP4技术后可能只需要在5000-6000块GPU上训练相同的时间,或者在相同的硬件上只需要18天左右就能完成训练。
除了直接的性能提升,FP4训练还将显著降低内存占用。由于数据精度的降低,相同的硬件能够处理更大的模型或更大的批次大小,这进一步提升了训练效率。这种内存效率的提升对于那些硬件资源有限的研究机构和公司来说特别有意义。
研究团队也指出了技术推广面临的一些挑战。首先是硬件的普及需要时间,新一代支持FP4的GPU需要逐步替换现有设备。其次是软件生态系统的完善,需要深度学习框架、编译器和相关工具链的支持。最后是算法的进一步优化,虽然当前的结果已经很好,但仍有改进空间。
不过,研究团队对这项技术的前景非常乐观。他们认为,随着硬件支持的到位和算法的持续优化,FP4训练将成为大型语言模型训练的标准选择之一,特别是在资源受限或对能效有高要求的场景中。
六、技术细节的精妙设计:魔鬼藏在实现里
要真正理解这项技术的价值,我们需要深入看看那些不起眼但至关重要的实现细节。这些细节就像一座精美建筑的地基和钢筋,虽然不显眼,但决定了整个结构的稳固性。
在FP4的具体实现中,研究团队选择了E2M1格式,这是一个经过深思熟虑的决定。这种格式用2位表示指数,1位表示尾数,能够在极其有限的4位空间内实现最佳的数值范围和精度平衡。相比其他可能的4位格式,E2M1能够表示从-6到+6的数值范围,同时在关键的小数值区间保持足够的精度。
由于FP4格式只能表示16个不同的数值,传统的浮点运算单元无法直接处理,研究团队不得不开发专门的CUDA内核来实现量化操作。这个内核使用查找表的方式,将输入的任意浮点数映射到最接近的16个FP4数值之一。虽然听起来简单,但在GPU的并行计算环境中高效实现这种映射需要精密的工程设计。
在DGE方法的实现中,研究团队遇到了一个数学上的奇点问题。当输入值正好位于量化区间的中点时,导数会趋向无穷大,这在数值计算中是不可接受的。他们的解决方案是引入一个小的正数ε来平滑这个奇点,使得函数变为 |x| ≈ √(x? + ε?)。这种处理既保持了数学上的严谨性,又确保了计算的稳定性。
对于OCC方法,研究团队需要在训练过程中实时维护一个稀疏矩阵来记录被钳制的离群值信息。这个稀疏矩阵的维护是一个技术挑战,因为它需要在保持高效率的同时准确跟踪哪些位置有离群值、这些离群值的具体数值是多少。研究团队采用了混合精度的策略,主计算路径使用FP4,而稀疏补偿路径使用FP8,在效率和精度之间找到了最佳平衡点。
在量化粒度的选择上,研究团队通过大量实验发现了一个重要规律:激活值比权重值更难量化。这种差异的根源在于两者的数据分布特性不同。权重在训练过程中会逐渐收敛到相对稳定的分布,而激活值则会随着输入数据的变化而剧烈波动,特别是那些离群值的出现更加不可预测。
为了应对这种差异,研究团队为权重和激活值设计了不同的处理策略。对于权重,主要依赖DGE方法来提升梯度计算的精度;对于激活值,则重点使用OCC方法来处理离群值问题。这种差异化的处理体现了技术方案的精细化和专业化。
研究团队还发现,在实际的大规模训练中,不同Transformer层的激活值特性存在显著差异。浅层网络的激活值相对比较规整,容易量化;而深层网络的激活值则更加复杂,离群值现象更加严重。这种层间差异为未来的优化提供了新的思路,比如可能为不同的层采用不同的量化策略。
说到底,这项研究就像是给计算机的"大脑"安装了一套更高效的"思维方式"。原本需要用复杂精确的方式处理每个信息,现在可以用更简化但同样有效的方式来工作,大大提升了整体效率。更重要的是,这种技术民主化了AI训练的门槛——原本只有科技巨头才能承担的大模型训练成本,现在中小型研究机构和公司也有可能参与进来。
从长远来看,这项技术不仅仅是一个技术优化,更是推动AI技术普及和可持续发展的重要一步。当训练大型语言模型的成本降低到原来的四分之一时,我们可能会看到更多创新的应用场景涌现,更多研究者能够参与到AI技术的发展中来,最终受益的将是整个社会。
当然,技术的完善和普及还需要时间,特别是硬件支持的全面到位。但正如研究团队在论文中所展示的那样,这项技术已经在实验室环境中证明了其可行性和有效性。随着NVIDIA B系列GPU等支持FP4计算的硬件逐步发布,我们有理由期待这项技术在不久的将来能够真正改变AI训练的游戏规则,有兴趣深入了解技术细节的读者可以通过论文地址 arXiv:2501.17116v2 访问完整的研究报告。
Q&A
Q1:FP4量化训练是什么?能带来多少性能提升?
A:FP4量化训练是一种让大型语言模型使用4位浮点数进行训练的技术,相比传统的16位训练方法,理论上能够提供接近4倍的计算加速和显著的内存节省。微软的研究表明,即使使用如此低的精度,模型的训练效果几乎不受影响。
Q2:FP4训练会不会影响AI模型的智能水平?
A:根据微软研究院的实验结果,FP4训练的模型在各种任务上的表现与传统高精度训练的模型几乎相同,在某些测试中甚至略有超越。研究团队在130亿参数的模型上验证了这一点,证明极低精度训练不会损害模型的"智能"。
Q3:普通人什么时候能用上FP4训练技术?
A:目前这项技术还需要专门的硬件支持,NVIDIA即将发布的B200系列GPU将原生支持FP4计算。预计在未来1-2年内,随着新硬件的普及和软件生态的完善,这项技术将逐步应用到实际的AI训练中,大幅降低AI模型的训练成本。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来
韩国KAIST开发的Vector Prism系统通过多视角观察和统计推理,解决了AI无法理解SVG图形语义结构的难题。该系统能将用户的自然语言描述自动转换为精美的矢量动画,生成的动画文件比传统视频小54倍,在多项评估中超越顶级竞争对手,为数字创意产业带来重大突破。

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
华为诺亚方舟实验室提出VersatileFFN创新架构,通过模仿人类双重思维模式,设计了宽度和深度两条并行通道,在不增加参数的情况下显著提升大语言模型性能。该方法将单一神经网络分割为虚拟专家并支持循环计算,实现了参数重用和自适应计算分配,为解决AI模型内存成本高、部署难的问题提供了全新思路。

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
