 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
UC Santa Cruz团队大幅精简视觉编码器训练:OpenVision 2让AI"看图说话"训练速度提升1.5倍
这项由加州大学圣克鲁兹分校的刘彦青、李先航等研究人员,联合苹果公司和加州大学伯克利分校共同完成的研究,发表于2025年9月的arXiv预印本平台。感兴趣的读者可以通过项目页面https://ucsc-vlaa.github.io/OpenVision2 或论文链接arXiv:2509.01644v1访问完整研究内容。
想象一下教孩子认识世界的过程。传统方法就像同时让孩子看图片、听描述,还要他们把图片和文字配对连线,这样虽然学得全面,但过程繁琐耗时。而现在,研究团队发现了一个更简单高效的方法:只要让AI直接看图片然后描述出来就够了,就像让孩子看到苹果直接说"这是红色的苹果"一样自然。
在人工智能的世界里,教会机器"看懂"图片一直是个复杂的工程。就好比培养一个艺术鉴赏家,传统做法需要让他既学会看画,又学会读文字,还要学会把画和文字对应起来。这种叫做"对比学习"的方法虽然效果不错,但就像同时学三门课程一样费时费力。UC Santa Cruz的研究团队却发现,其实只要专心训练机器"看图说话"这一项技能就足够了。
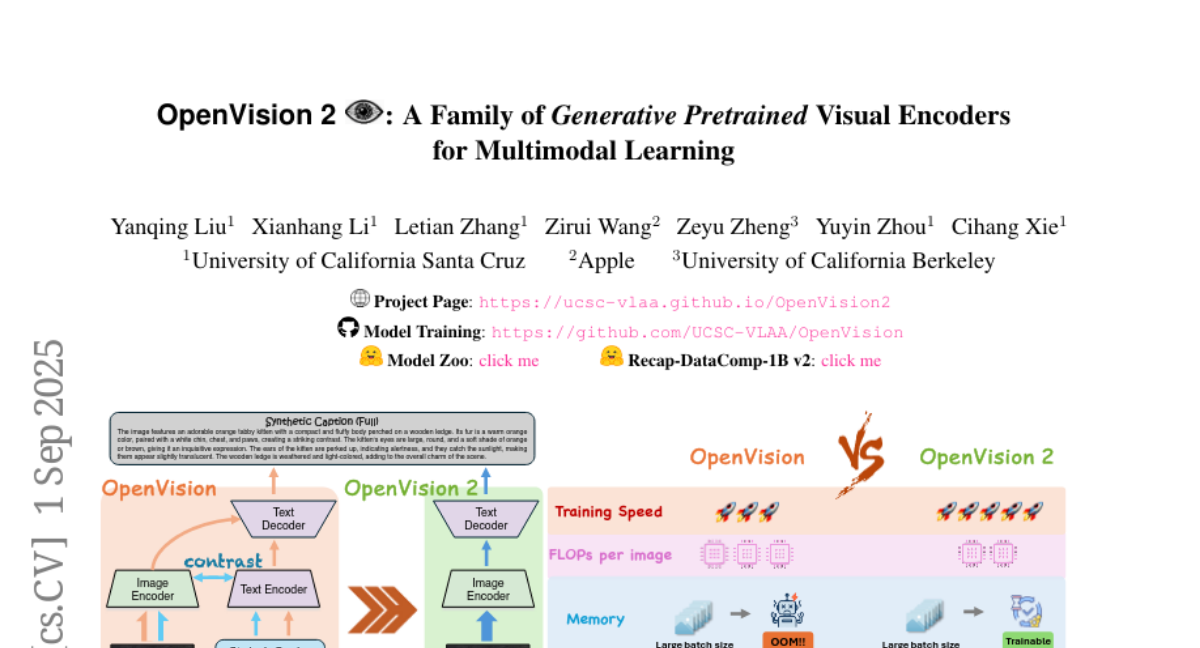
他们开发的OpenVision 2系统,就像把原来的三合一课程简化成了单科集训。原本的OpenVision需要一个图像编码器来"看图",一个文本编码器来"读字",还需要一个文本生成器来"说话"。而OpenVision 2直接砍掉了文本编码器这个中间环节,让图像编码器直接和文本生成器对话,就像让学生跳过复杂的理论课,直接进入实践操作一样。
这种简化带来的效果令人惊喜。以ViT-L/14模型为例,训练时间从83小时缩短到57小时,内存使用量从24.5GB降到13.8GB,这意味着研究人员可以用更小的计算资源训练更大的模型。更重要的是,这种简化并没有牺牲性能。在各种视觉理解任务上,OpenVision 2的表现与原版不相上下,在某些OCR(光学字符识别)任务上甚至表现更好。
研究团队的发现挑战了长期以来的一个观念:要训练出优秀的视觉编码器,就必须使用CLIP式的对比学习方法。他们证明,纯粹的生成式训练(也就是"看图说话"的方法)不仅可行,而且在很多情况下更好。这就像发现了一条更直接的学习路径,既省力又高效。
一、从复杂到简单的革命性转变
OpenVision的原始设计就像一个全能型学习系统。它需要处理两种不同类型的图片描述:一种是从网上抓取的原始描述,通常比较简单粗糙,比如"一只橙色的猫坐在台阶上";另一种是由高级AI模型生成的详细描述,能够描述"图片中有一只毛茸茸的橙色虎斑小猫,坐在风化的浅色木质台阶上,它的眼睛大而圆,呈现柔和的橙棕色,给人以好奇的表情"这样的细致内容。
原来的训练过程就像开办一个三重课程的学习班。首先,系统要学会对比不同的图像和文本对,就像让学生练习看图识字的配对游戏。同时,它还要学会根据图像和简单描述来生成详细描述,这相当于看图作文的练习。整个过程需要维护三个独立的神经网络组件,每个都需要大量的计算资源和存储空间。
OpenVision 2的革命性改变就在于彻底抛弃了这种复杂的三重结构。新系统就像一个专心致志的学生,只专注于一件事:看图说话。当给它一张图片时,它直接学习如何生成相应的文字描述,不再需要复杂的对比和配对过程。这种方法借鉴了近年来CapPa和AIMv2等研究的思路,同时也与现代多模态系统如LLaVA的设计理念高度一致。
更巧妙的是,研究团队还加入了一个"部分遮挡"的训练技巧。就像让学生练习看不完整的图片也能写出完整描述一样,系统在训练时会随机遮住大约三分之二的视觉信息,只用剩余的三分之一来生成描述。这不仅进一步减少了计算负担,还意外地提升了系统的理解能力,因为它必须学会从有限的信息中推断出更多内容。
这种简化设计的另一个重要优势是解决了训练和应用之间的不一致问题。原来的OpenVision在训练时使用对比学习,但在实际应用中(比如接入LLaVA这样的对话系统)却要进行生成式任务,这就像学生在课堂上练习选择题,考试时却要写作文。OpenVision 2从一开始就专注于生成式训练,使得预训练阶段与后续应用完美对接。
二、数据质量的关键突破
数据就像烹饪的原材料,质量决定了最终成品的水准。OpenVision 2的成功很大程度上依赖于一个叫做"ReCap-DataComp-1B v2"的高质量数据集。这个数据集的诞生过程就像请了一位顶级大厨来重新制作菜谱。
传统的网络爬取数据就像从各家小餐厅收集的菜谱,质量参差不齐,有些描述过于简单("一只猫"),有些又完全跑题。研究团队决定用强大的LLaMA-3模型来重新"翻译"这些图片。这就好比请一位经验丰富的美食评论家重新品尝每道菜,然后写出详细而准确的评价。
ReCap-DataComp-1B v2数据集的制作过程特别精妙。它不是简单地让AI看图写话,而是同时参考原始的简单描述和图片内容,生成更加丰富和准确的描述。这就像让评论家不仅要品尝菜品,还要参考菜单说明,写出既忠于原意又更加详尽的评价。通过这种方法生成的描述既保持了多样性,又确保了准确性。
实验结果显示,使用高质量合成描述训练的模型在各项测试中都显著优于使用原始网络描述训练的模型。在TextVQA任务上,性能提升了5.1分,在OCR任务上更是提升了53分。这种巨大的改进证明了"好的老师胜过复杂的教学方法"这一朴素道理。
研究团队还发现,完全使用合成数据训练的效果比混合使用真实和合成数据更好。这个发现颇有些颠覆性,就像发现标准化的教科书比各种杂七杂八的参考资料更适合学习一样。这种一致性和高质量的训练数据使得模型能够学习到更加稳定和可靠的视觉-语言对应关系。
三、训练效率的显著提升
OpenVision 2在训练效率方面的提升就像从手工制作转向工业化生产。所有实验都在Google Cloud的TPU v4上进行,这些专门为机器学习优化的芯片就像是为AI训练量身定制的超级工厂。
最直观的改进体现在训练时间上。使用ViT-L/14模型在224分辨率下训练时,时间从83小时缩短到57小时,相当于节省了约1.5倍的时间。当模型规模扩大到SoViT-400M时,这种效率提升更加明显,训练时间从241小时减少到121小时,几乎缩短了一半。这就像把一个需要一周完成的项目压缩到三天内完成,而质量丝毫不受影响。
内存使用量的改善同样令人印象深刻。在相同的批处理大小下,OpenVision 2的内存需求大约是原版的一半。这意味着研究人员可以在相同的硬件上训练更大的批次,或者用更少的设备完成同样的训练任务。具体来说,ViT-L/14模型的内存使用从24.5GB降到13.8GB,这使得最大批处理大小可以从2000提升到8000。
这种效率提升不仅仅是数字上的改进,它还开启了新的可能性。研究团队成功训练出了参数量超过10亿的视觉编码器,这在原来的OpenVision架构下几乎是不可想象的。就像更高效的生产线不仅能降低成本,还能制造出以前无法生产的大型产品一样。
研究还详细分析了不同优化策略的贡献。CLIPA优化技术和token掩码策略都对效率提升起到了重要作用,但两者结合使用时效果最佳。CLIPA技术通过先在低分辨率图像上预训练再在高分辨率上微调的方式大幅减少计算量,而token掩码则进一步减少了文本解码器的工作负担。两种技术的结合就像同时使用了高效的教学方法和精简的课程内容。
四、性能表现的全面验证
为了验证OpenVision 2的实际效果,研究团队在两个主要的多模态框架LLaVA-1.5和Open-LLaVA-Next上进行了全面测试。这就像让一个新培养的学生同时参加不同学校的考试,以确保其能力的普适性。
测试涵盖了八个不同类型的任务,包括文本问答(TextVQA)、图表问答(ChartQA)、光学字符识别(OCR)、多模态评估(MME)、种子基准测试(SEED)、科学问答(SQA)、通用问答(GQA)和教皇测试(POPE)。这些测试就像全科考试,从不同角度检验AI系统的视觉理解能力。
在LLaVA-1.5框架下的测试结果显示,OpenVision 2不仅保持了与原版相当的性能,在某些任务上甚至表现更好。特别是在OCR相关任务上,新系统表现尤为突出。以ViT-L/14模型在224分辨率下的表现为例,TextVQA得分从57.7提升到59.0,OCR任务得分从315提升到327。这种提升就像学生不仅保持了原有的优势科目,还在薄弱环节有了显著进步。
更令人惊喜的是,当模型规模扩大时,这种优势变得更加明显。使用更大的H/14模型在448分辨率下训练时,OpenVision 2在TextVQA上达到65.6分,ChartQA达到18.1分,OCR任务达到416分,这些数字都显著优于同等条件下的基线模型。
在Open-LLaVA-Next框架下的测试进一步证实了这些发现。OpenVision 2在保持高性能的同时,显著减少了训练成本。这种一致性表明,新方法的优势不是偶然现象,而是一种可靠的改进。
特别值得注意的是,研究团队还成功训练出了参数量达到10.1亿的超大模型OpenVision 2-g/14。这个巨型模型在各项测试中都表现出色,证明了新方法的可扩展性。这就像证明了一种新的教学方法不仅适用于小班教学,也能在大规模教育中发挥作用。
五、技术细节的深入探索
OpenVision 2的核心创新可以通过几个关键的设计决策来理解。首先是架构简化,原来需要三个独立网络组件的复杂系统被精简为两个组件。这种简化就像把复杂的多道工序合并成流水线作业,不仅减少了中间环节的损耗,还提高了整体效率。
token掩码策略是另一个重要创新。在训练过程中,系统会随机隐藏大约三分之二的视觉token,只用剩余的信息来生成文本描述。这种做法看似反直觉,但实际上促使模型学习更有效的信息提取方式。就像让学生练习从不完整的材料中提取关键信息,反而能提高他们的理解和推理能力。
实验发现,保留25-35%的视觉token时效果最佳,这个比例既能提供足够的信息支持文本生成,又能强制模型学会抓住最重要的视觉特征。如果保留太多token(如100%),模型可能会过度依赖细节而忽略整体理解;如果保留太少(如10%),则信息不足以支撑准确的描述生成。
与之前的研究相比,OpenVision 2在多个维度上都有所改进。相比CapPa,它使用了更高质量的合成标注,采用了更简单的融合方式,并且扩展到了更大的模型规模。相比AIMv2,它专注于纯文本生成而不涉及图像重建,使用了不同的token掩码策略,并且数据完全基于合成标注。
数据处理方面,ReCap-DataComp-1B v2的生成策略特别值得关注。它在生成合成标注时同时考虑原始图像和网络标注,使用加权top-k采样来平衡多样性和准确性。这种方法就像让AI评论家既要看作品又要参考别人的评价,写出既有独特见解又有一定共识基础的评论。
六、对现有认知的挑战
OpenVision 2的成功对计算机视觉领域的一个基本假设提出了挑战。长期以来,研究界普遍认为CLIP式的对比学习是训练高质量视觉编码器的必要条件。这就像人们一直相信学习外语必须同时练习听说读写四项技能一样。
然而,OpenVision 2证明了纯粹的生成式学习同样可以达到甚至超越对比学习的效果。这个发现的意义不仅仅在于技术层面,它还暗示着我们对机器学习本质的理解可能需要更新。生成式学习让模型直接学习从视觉到语言的映射,这种端到端的学习方式可能更加符合人类认知的自然过程。
这种认知转变的实际意义是深远的。对于研究人员而言,它意味着可以用更简单的方法达到更好的效果。对于产业界而言,它意味着更低的计算成本和更高的开发效率。对于整个AI发展而言,它可能指向一个更加高效和可持续的发展方向。
研究团队特别强调了这种方法与下游应用的一致性优势。由于OpenVision 2在预训练阶段就使用生成式目标,它与LLaVA等多模态对话系统的架构天然匹配。这种一致性就像让学生从一开始就按照考试标准来学习,避免了后期的适应问题。
更重要的是,这种方法的成功为未来的研究开辟了新的方向。如果纯生成式学习确实优于复杂的对比学习,那么我们可能需要重新审视很多现有的技术假设。这就像发现了一条更直接通往山顶的路径,虽然看起来简单,但实际效果更好。
七、实际应用的广阔前景
OpenVision 2的技术突破不仅仅停留在学术层面,它在实际应用中的潜力同样令人兴奋。更高的训练效率意味着更多的研究团队和公司能够负担得起训练高质量视觉编码器的成本,这将大大降低AI技术的准入门槛。
在商业应用方面,这种效率提升直接转化为成本节约。企业可以用更少的计算资源训练出更好的模型,或者在相同预算下训练更大更强的模型。这就像找到了一种更高效的生产方式,既降低了成本又提高了产品质量。
对于科研机构而言,OpenVision 2使得大规模视觉编码器的训练变得更加可行。研究团队已经成功训练出了10.1亿参数的模型,这在原有架构下是极其昂贵的。现在,更多的研究小组可以尝试训练大规模模型,推动整个领域的快速发展。
在具体的应用场景中,OpenVision 2训练的视觉编码器可以用于各种多模态任务。从图像描述生成到视觉问答,从文档理解到图表分析,这些经过优化训练的编码器都能提供更好的性能。特别是在OCR相关任务上的突出表现,使得它在处理文档、标志、图表等包含文字信息的图像时具有明显优势。
更重要的是,OpenVision 2的开源特性使得整个社区都能受益于这些改进。研究团队不仅公布了完整的训练代码和预训练模型,还提供了ReCap-DataComp-1B v2数据集。这种开放态度就像建设了一个公共图书馆,让所有人都能获得高质量的学习资源。
展望未来,这种高效的训练方法可能会成为视觉编码器训练的新标准。随着技术的进一步优化和硬件的持续发展,我们可能会看到更大规模、更高性能的视觉编码器不断涌现,推动整个人工智能领域的快速发展。
说到底,OpenVision 2的成功证明了一个简单而深刻的道理:有时候,最好的解决方案不是最复杂的那个,而是最简单有效的那个。就像老话说的"大道至简",在AI的世界里,简单优雅的方法往往比复杂花哨的技术更有生命力。这项研究不仅为我们提供了一个更好的工具,更重要的是,它让我们重新思考了解决问题的方式。当我们面对复杂挑战时,也许答案并不在于增加更多的复杂度,而在于找到问题的本质,用最直接的方式去解决它。
对于那些想要深入了解技术细节或在自己的项目中应用这些创新的读者,完整的研究论文和相关资源都已在项目网站https://ucsc-vlaa.github.io/OpenVision2 上公开提供。这种开放共享的精神正是推动科技进步的重要动力,让更多的人能够站在巨人的肩膀上,继续探索AI的无限可能。
Q&A
Q1:OpenVision 2相比原版OpenVision有什么主要改进?
A:OpenVision 2的核心改进是大幅简化了训练架构,去掉了原版中的文本编码器和对比学习损失,只保留图像编码器和文本解码器,专注于"看图说话"的生成式训练。这使得训练时间缩短1.5倍,内存使用减少1.8倍,同时性能保持不变甚至更好。
Q2:为什么OpenVision 2能够在简化架构的同时保持甚至提升性能?
A:关键在于使用了高质量的合成数据集ReCap-DataComp-1B v2和巧妙的token掩码策略。高质量的训练数据就像好的教材,而掩码策略强制模型学会从不完整信息中提取关键特征,提高了模型的理解能力。同时,生成式训练与下游应用更匹配。
Q3:OpenVision 2的技术突破对普通AI开发者有什么实际意义?
A:最直接的好处是大幅降低了训练成本和硬件要求,让更多研究团队和小公司能够训练高质量的视觉编码器。研究团队还开源了所有代码、预训练模型和数据集,开发者可以直接使用这些资源构建自己的多模态AI应用。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

从“互联”到“智联”:荣耀MagicOS 10如何用“自进化”重构人机关系?
过去十年,终端厂商比拼的是“性能”和“参数”,如今,竞争的焦点正转向“智能程度”。


让AI学会深度搜索:Fractal AI Research实验室开发出能像侦探一样追踪真相的智能助手
Fractal AI Research实验室开发了Fathom-DeepResearch智能搜索系统,该系统由两个4B参数模型组成,能够进行20多轮深度网络搜索并生成结构化报告。研究团队创新了DUETQA数据集、RAPO训练方法和认知行为奖励机制,解决了AI搜索中的浅层化、重复性和缺乏综合能力等问题,在多项基准测试中显著超越现有开源系统,为AI助手向专业研究工具转变奠定了基础。

快手科技重磅突破:AI语言模型训练的"权重平衡术"让机器学习更聪明
快手科技与清华大学合作发现当前AI语言模型训练中存在严重的权重分配不平衡问题,提出了非对称重要性采样策略优化(ASPO)方法。该方法通过翻转正面样本的重要性权重,让模型把更多注意力放在需要改进的部分而非已经表现良好的部分,显著提升了数学推理和编程任务的性能,并改善了训练稳定性。

从“互联”到“智联”:荣耀MagicOS 10如何用“自进化”重构人机关系?

开源红帽,加速AI

让AI学会深度搜索:Fractal AI Research实验室开发出能像侦探一样追踪真相的智能助手

快手科技重磅突破:AI语言模型训练的"权重平衡术"让机器学习更聪明
