 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
清华大学团队突破AI图像检测:让计算机像侦探一样揪出假图片
在这个AI生成图片满天飞的时代,辨别真假图片已经成了一个让人头疼的问题。就在最近,清华大学自动化系和电子工程系的研究团队为我们带来了一个令人兴奋的解决方案。这项研究由张彦然、于炳尧、郑宇、郑文钊、段月琪、陈雷、周杰和卢继文领导,发表于2025年10月的arXiv预印本平台,论文编号为arXiv:2510.05891v1。有兴趣深入了解的读者可以通过这个编号查询完整论文。
说起AI生成图片,大家可能最先想到的是那些能画出美丽风景或者虚构人物的程序。但你知道吗,现在有一类叫做"自回归"的AI模型正在悄然改变游戏规则。这就像是有一个特别聪明的画家,它不是一口气画完整张画,而是一个小块一个小块地画,每画一块都要参考前面已经画好的部分。这种方法生成的图片质量非常高,几乎能以假乱真。
问题就出现在这里。当假图片变得越来越逼真,我们该如何分辨它们呢?传统的检测方法就像是用放大镜查看画布上的笔触来判断是不是名画,但这些新型AI模型生成的图片在表面上看起来完全没有破绽。清华大学的研究团队想到了一个绝妙的办法:既然这些AI模型在创作过程中有自己独特的"思维方式",那我们就从这个"思维方式"入手来识别它们。
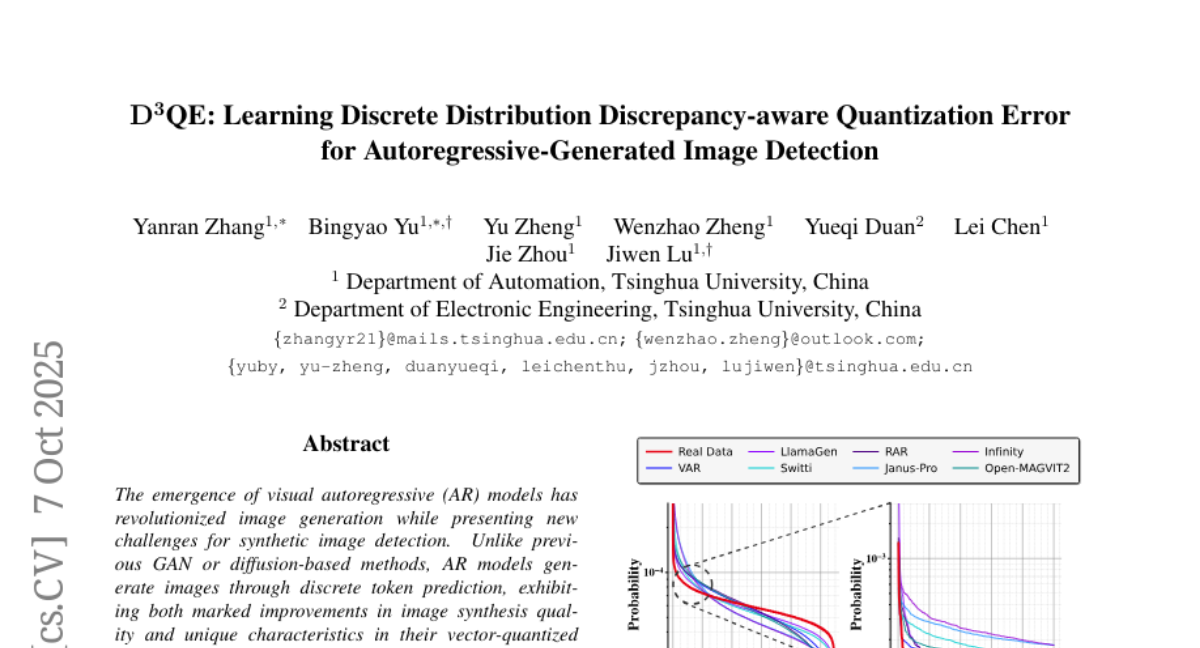
研究团队发现了一个有趣的现象。这些自回归AI模型在生成图片时,就像是在使用一本特殊的"颜色字典"。真实照片使用这本字典的方式非常均匀,就像一个有经验的画家会平衡地使用调色板上的所有颜色。但AI生成的图片却表现出明显的偏好,总是过度使用某些特定的"颜色",而忽略其他的。这种差异就像是每个画家都有自己的用色习惯一样明显。
基于这个发现,研究团队开发了一套名为D3QE的检测系统。这个名字听起来很复杂,但其实就是"离散分布差异感知量化误差"的缩写。简单来说,这个系统就像是一个超级敏锐的侦探,专门观察AI模型在创作过程中留下的"指纹"。
这个检测系统的工作原理可以比作一个经验丰富的艺术鉴定师。当面对一幅可疑的画作时,鉴定师不仅会观察画面本身,还会分析画家的用色习惯、笔触特点等细节。D3QE系统也是如此,它不仅分析图片的表面特征,更重要的是分析图片背后的"创作过程"。
具体来说,这个系统包含三个核心组件。第一个组件负责提取AI模型在创作过程中产生的"量化误差"。这就像是分析画家在调色时产生的细微差异,虽然肉眼看不出来,但确实存在。第二个组件是一个特殊的注意力机制,它能够识别真实图片和AI生成图片在"颜色字典"使用上的差异。第三个组件则负责提取图片的语义特征,相当于理解图片的整体内容和风格。
为了验证这个系统的有效性,研究团队还专门构建了一个名为ARForensics的数据集。这个数据集包含了当前最先进的7种自回归AI模型生成的图片,总共有152,000张真实图片和152,000张AI生成图片。这就像是为侦探提供了一个庞大的案例库,让他们能够学习和识别各种不同"作案手法"的特征。
在实验中,这个系统表现得相当出色。面对训练时见过的LlamaGen模型生成的图片,系统达到了97.19%的准确率。更令人印象深刻的是,即使面对训练时从未见过的其他自回归模型,比如VAR、RAR、Open-MAGVIT2等,系统仍然保持了很高的检测准确率,平均达到82.11%。
有趣的是,研究团队还测试了这个系统对付传统GAN模型和扩散模型的能力。结果发现,虽然这个系统主要是为检测自回归模型而设计的,但它对其他类型的AI生成图片也有不错的识别能力。在GAN生成的图片测试中,系统达到了83.73%的平均准确率,在扩散模型生成的图片测试中也达到了78.61%的准确率。
研究团队特别关注了系统的实用性。在现实世界中,图片经常会经历各种处理,比如JPEG压缩、裁剪等。他们发现,即使在这些"干扰"条件下,D3QE系统仍然保持了良好的检测性能。当图片经过质量为60的JPEG压缩时,系统的检测准确率仍然保持在85%以上。即使面对严重的裁剪(只保留原图50%的内容),系统的准确率仍然超过80%。
为了更好地理解系统的工作原理,研究团队还进行了详细的分析。他们发现,真实图片在使用"颜色字典"时表现出均匀的分布模式,而AI生成的图片则显示出明显的集中性。具体来说,AI生成图片在高频使用的"颜色"上的激活率比真实图片高3到5倍,而在低频区域则覆盖不足。这种分布模式的差异为检测提供了强有力的线索。
这项研究的意义远不止于技术层面的突破。随着AI生成内容技术的快速发展,如何维护数字媒体的真实性和可信度已经成为一个重要的社会问题。这个检测系统为我们提供了一把新的"武器",帮助我们在信息泛滥的时代保持清醒的判断。
研究团队在论文中详细描述了系统的各个组件是如何协同工作的。量化误差表示模块首先使用一个冻结的离散自编码器将图片转换为离散表示。这个过程就像是把一幅画转换成数字代码,每个小区域都对应一个特定的编号。然后,系统计算连续表示和离散表示之间的差异,这个差异就是所谓的"量化误差"。
离散分布差异感知变换器是系统的核心创新。它不是简单地分析图片特征,而是将"颜色字典"的使用统计信息融入到注意力机制中。这就像是给侦探装上了特殊的眼镜,让他们能够看到普通人看不到的线索。这个模块能够动态地调整对不同特征的关注程度,重点关注那些最能区分真假图片的特征。
语义特征提取模块则利用预训练的CLIP模型来捕捉图片的高层语义信息。CLIP是一个能够理解图片内容的AI模型,它就像是一个能够描述画面内容的专家。通过结合这种语义理解能力,系统能够识别出AI生成图片在语义层面可能存在的不一致性。
在实际应用中,这三个模块的输出会被融合在一起,形成一个综合的判断。这就像是三个不同专业背景的专家共同对一幅画作进行鉴定,每个人都从自己的专业角度提供意见,最终形成一个更可靠的结论。
研究团队还进行了大量的对比实验,将他们的方法与现有的最先进检测方法进行比较。结果显示,D3QE系统在几乎所有测试场景中都表现出色。特别是在检测新型自回归模型方面,它的优势更加明显。传统的检测方法主要针对GAN或扩散模型设计,面对自回归模型时往往力不从心,而D3QE系统则能够有效地应对这个挑战。
除了技术层面的创新,这项研究还为整个AI安全领域提供了新的思路。它告诉我们,要有效地检测AI生成内容,不能仅仅依赖表面特征,而要深入理解不同AI模型的内在工作机制。这种"知己知彼"的方法论对于应对未来可能出现的新型生成模型具有重要的指导意义。
研究团队特别强调了他们构建的ARForensics数据集的价值。这个数据集不仅包含了当前最先进的自回归模型生成的图片,还为每种模型提供了详细的技术参数和生成策略信息。这为其他研究者提供了一个宝贵的研究平台,有助于推动整个领域的发展。
在实验设计方面,研究团队采用了严格的科学方法。他们将数据集分为训练集、验证集和测试集,确保模型在评估时面对的是从未见过的数据。训练集包含100,000张LlamaGen生成的图片和相应数量的真实图片,验证集包含10,000对图片,而测试集则包含了所有7种自回归模型各6,000张图片及对应的真实图片。
为了确保实验结果的公平性,研究团队还特别注意了数据的平衡性。真实图片都是从ImageNet数据集中独立采样的,避免了数据重叠可能带来的偏差。对于文本到图像的模型,他们使用了标准的提示模板,而对于其他模型则直接使用了预训练版本进行类别条件生成。
在模型训练过程中,研究团队采用了冻结部分参数的策略。具体来说,他们冻结了CLIP编码器、VQVAE主干网络和码本,只训练新增的模块。这种做法既保证了预训练模型的稳定性,又允许新模块学习特定的检测特征。训练使用了AdamW优化器,学习率设置为0.0001,权重衰减为0.01,批次大小为32,训练了10个轮次。
研究团队还进行了详细的消融研究,分析了系统各个组件的贡献。结果显示,仅使用CLIP语义特征的基础模型准确率为79.56%,加入VQVAE残差特征后提升到79.92%,使用离散特征和普通变换器的组合达到80.39%,而采用残差特征和普通变换器的组合达到80.72%。最终,使用残差特征和D3AT模块的完整系统达到了82.11%的准确率,验证了每个组件的有效性。
在参数敏感性分析中,研究团队发现D3AT模块在512维时达到最佳性能。较低的维度(如128维)限制了表示能力,导致准确率下降到80.83%,而较高的维度(如1024维)则可能导致过拟合,准确率降至80.37%。这个发现为系统的优化提供了重要指导。
说到底,这项研究为我们提供了一个强有力的工具来应对AI生成内容带来的挑战。它不仅在技术上实现了突破,更重要的是为维护数字世界的真实性和可信度贡献了力量。随着AI技术的不断发展,这样的检测技术将变得越来越重要。
当然,这场"真假图片"的较量还远未结束。就像历史上所有的攻防战一样,生成技术和检测技术会在相互促进中不断发展。但至少现在,我们有了更好的武器来保护自己不被欺骗。这项研究为我们在数字时代保持清醒的判断力提供了重要支撑,让我们能够更好地区分真实与虚假,维护信息的可信度。
Q&A
Q1:D3QE检测系统是什么,它是如何工作的?
A:D3QE是清华大学团队开发的AI图像检测系统,专门用来识别自回归模型生成的假图片。它的工作原理类似艺术鉴定师,通过分析AI模型在创作过程中的"用色习惯"和量化误差来判断图片真假。系统包含三个核心组件:量化误差提取、离散分布差异感知变换器和语义特征提取,三者协同工作形成综合判断。
Q2:为什么传统的AI图片检测方法对自回归模型效果不好?
A:传统检测方法主要针对GAN和扩散模型设计,它们通过寻找像素级的伪影来识别假图片。但自回归模型采用完全不同的生成方式,是一个小块一个小块地生成图片,其伪影存在于离散潜在空间而非像素层面,所以传统方法很难检测到。D3QE系统专门针对这种特殊的生成机制设计,能够有效识别自回归模型的"指纹"。
Q3:D3QE检测系统的准确率如何,在实际应用中表现怎样?
A:D3QE系统表现相当出色,对训练时见过的LlamaGen模型达到97.19%的准确率,对其他未见过的自回归模型平均准确率达82.11%。更重要的是,系统在面对现实世界的图片处理时依然稳定,即使经过JPEG压缩(质量60)仍保持85%以上准确率,面对严重裁剪(保留50%内容)时准确率仍超过80%,显示出良好的实用性。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来
韩国KAIST开发的Vector Prism系统通过多视角观察和统计推理,解决了AI无法理解SVG图形语义结构的难题。该系统能将用户的自然语言描述自动转换为精美的矢量动画,生成的动画文件比传统视频小54倍,在多项评估中超越顶级竞争对手,为数字创意产业带来重大突破。

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
华为诺亚方舟实验室提出VersatileFFN创新架构,通过模仿人类双重思维模式,设计了宽度和深度两条并行通道,在不增加参数的情况下显著提升大语言模型性能。该方法将单一神经网络分割为虚拟专家并支持循环计算,实现了参数重用和自适应计算分配,为解决AI模型内存成本高、部署难的问题提供了全新思路。

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
