 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
南京大学团队揭秘:仅用8亿数据就让AI既会翻译又会推理,打破传统认知
这项突破性研究由南京大学国家重点实验室的高长江教授团队联合香港大学、卡内基梅隆大学和上海人工智能实验室共同完成,研究成果于2025年10月发表在arXiv预印本库,论文编号为arXiv:2510.09189v1。有兴趣深入了解的读者可以通过该编号查询完整论文。
这个研究解决了一个让人工智能领域头疼已久的问题:为什么那些翻译能力超强的AI模型在数学推理和编程方面却表现得像个初学者?就好比一个精通多国语言的翻译官,却连简单的算术题都算不对。这种现象在AI界被称为"能力分化",一直困扰着研究人员。
研究团队发现了一个令人惊讶的现象。传统的多语言AI训练就像是在建造一座房子,大家都习惯从地基开始重新搭建,需要海量的数据和资源。比如目前最先进的多语言模型Tower-Plus需要320亿个数据tokens,而Hunyuan-MT甚至需要1.3万亿个tokens,这相当于要读完几万个图书馆的书籍才能学会。
但南京大学团队提出了一个全新的思路:既然基础推理能力(比如数学计算和逻辑思维)在任何语言中都是通用的,为什么不从一个已经具备这些能力的"聪明学生"开始,只教它如何用不同语言表达这些能力呢?这就像是找一个数学天才,然后只教他如何用法语、德语或阿拉伯语来解释数学概念,而不是从头教他数学。
团队开发的Qwen3-XPlus模型采用了一种叫做"分层选择性调优"的巧妙方法。可以把AI模型想象成一个有32层楼的大脑建筑,每一层负责不同的思维功能。传统方法是把整栋楼都拆了重建,而新方法只改造其中关键的几层楼——最底层的4层(负责理解输入)和最顶层的15层(负责生成输出),中间的层级保持不变。这样既保留了原有的推理能力,又增强了多语言表达能力。
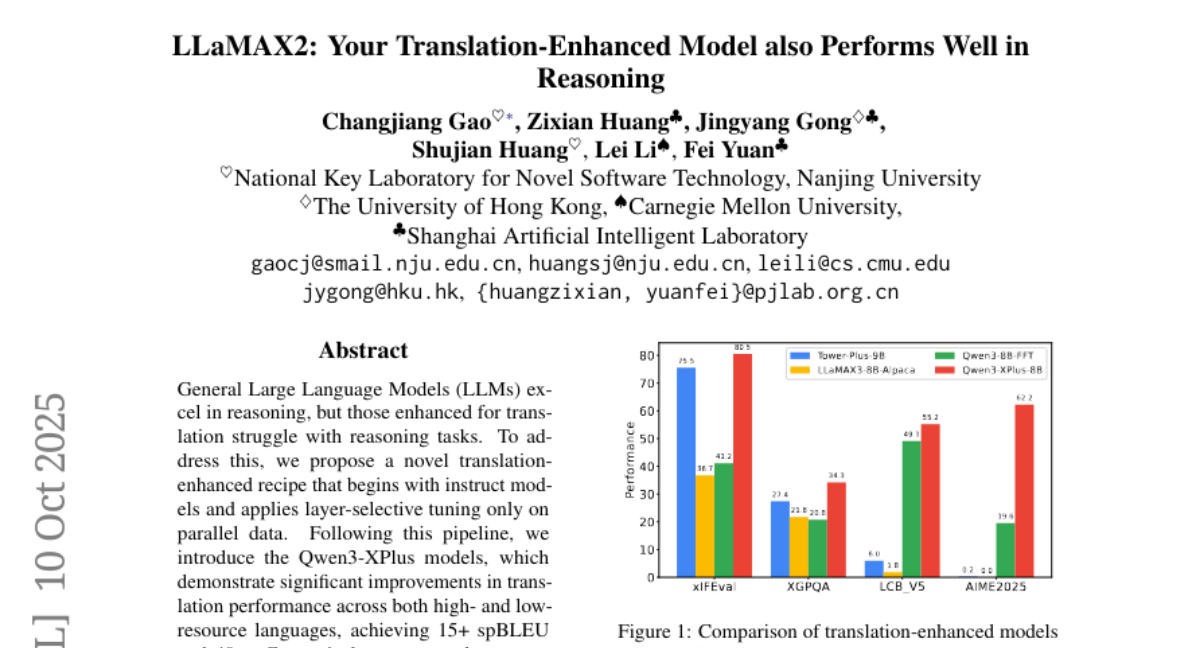
更令人惊叹的是训练数据的精简程度。研究团队只用了8亿个高质量的平行数据tokens,就达到了其他模型用数千倍数据才能实现的效果。他们对训练数据进行了六道精细的处理工序:首先统一格式,然后清除无效字符,接着用先进算法去除重复内容,再用语言识别技术过滤错误标注的数据,随后评估翻译质量剔除低质量样本,最后转换成指令格式。整个过程就像是在淘金,从大量原始矿石中提炼出最纯净的黄金。
实验结果让人眼前一亮。在翻译任务中,Qwen3-XPlus在低资源语言(如斯瓦希里语)上实现了15+的spBLEU分数和40+的xComet分数,这意味着翻译质量达到了前所未有的水平。更重要的是,它在保持翻译能力的同时,在7个多语言任务上平均提升了1分以上,在15个主流推理数据集上的表现与原始模型不相上下。
这项研究的意义不仅仅在于技术突破。传统的多语言模型训练就像是用大炮打蚊子,需要巨额投资和专业团队。而Qwen3-XPlus的方法更像是精准的激光手术,大大降低了技术门槛,让更多的研究机构和公司能够开发出高质量的多语言AI系统。
团队还验证了这种方法的通用性。他们在不同的AI模型架构上测试了这种分层训练方法,结果都显示出显著的改进效果。这就像是发现了一个通用的"学习秘诀",不管是什么类型的学生,都能用这个方法快速掌握多语言能力。
研究过程中有一个特别有趣的发现:AI模型的中间层(大约第20层)对翻译能力有负面影响。当研究团队只训练这一层时,翻译性能反而下降了。这个发现支持了他们的假设:在类似人脑的模型结构中,底层负责"编码"输入信息,顶层负责"解码"输出结果,而中间层则储存着核心的推理能力,不应该被轻易改动。
更令人惊喜的是,Qwen3-XPlus还展现出了良好的泛化能力。即使在训练过程中没有见过的语言上,它也能表现出色。研究团队在12种未曾训练过的代表性语言上进行测试,结果显示Qwen3-XPlus consistently(一致性地)超越了基础模型,证明了这种方法不仅仅是记忆训练数据,而是真正学会了跨语言的推理能力。
这项研究为AI领域开辟了一条新的道路。以往大家认为要让AI既聪明又多语言,就必须投入海量资源从零开始训练。现在证明,通过巧妙的方法设计,我们可以在保持AI原有智慧的基础上,高效地赋予它多语言能力。这种思路不仅适用于翻译任务,还可能推广到其他需要跨语言能力的AI应用中。
说到底,这项研究告诉我们一个简单而深刻的道理:在AI训练中,方法比资源更重要。与其盲目地堆积数据和计算力,不如深入理解AI模型的内在机制,找到最有效的改进方式。Qwen3-XPlus的成功证明,通过精心设计的训练策略,我们可以用更少的资源实现更好的效果,这对于推动AI技术的普及和应用具有重要意义。
对于普通人来说,这项研究意味着未来我们可能会看到更多既智能又多语言的AI助手,它们不仅能够进行高质量的翻译,还能用不同语言进行复杂的推理和问题解决。这将大大降低语言障碍,让全球的知识和信息更容易分享和获取。有兴趣深入了解技术细节的读者,可以通过arXiv:2510.09189v1查询完整的研究论文。
Q&A
Q1:Qwen3-XPlus相比传统多语言模型有什么优势?
A:Qwen3-XPlus的最大优势是用极少的数据就能同时保持翻译和推理能力。传统模型需要数千亿甚至万亿个数据tokens,而Qwen3-XPlus只用了8亿个高质量数据就达到了更好的效果。更重要的是,它不会出现传统模型"翻译强但推理弱"的问题,在数学推理和编程任务上表现依然出色。
Q2:分层选择性调优是怎么工作的?
A:分层选择性调优就像是对AI大脑进行精准手术。AI模型有32层结构,传统方法是全部重新训练,而新方法只改造底层4层(负责理解输入)和顶层15层(负责生成输出),保持中间层的推理能力不变。这种方法既增强了多语言能力,又避免了损害原有的逻辑推理能力。
Q3:这项技术什么时候能应用到实际产品中?
A:研究团队已经开源了Qwen3-XPlus-8B和Qwen3-XPlus-14B两个模型,开发者可以直接使用。由于这种方法大大降低了训练成本和技术门槛,预计很快就会有公司将其集成到翻译软件、多语言客服系统等实际产品中,让普通用户享受到更智能的多语言AI服务。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

从“互联”到“智联”:荣耀MagicOS 10如何用“自进化”重构人机关系?
过去十年,终端厂商比拼的是“性能”和“参数”,如今,竞争的焦点正转向“智能程度”。


让AI学会深度搜索:Fractal AI Research实验室开发出能像侦探一样追踪真相的智能助手
Fractal AI Research实验室开发了Fathom-DeepResearch智能搜索系统,该系统由两个4B参数模型组成,能够进行20多轮深度网络搜索并生成结构化报告。研究团队创新了DUETQA数据集、RAPO训练方法和认知行为奖励机制,解决了AI搜索中的浅层化、重复性和缺乏综合能力等问题,在多项基准测试中显著超越现有开源系统,为AI助手向专业研究工具转变奠定了基础。

快手科技重磅突破:AI语言模型训练的"权重平衡术"让机器学习更聪明
快手科技与清华大学合作发现当前AI语言模型训练中存在严重的权重分配不平衡问题,提出了非对称重要性采样策略优化(ASPO)方法。该方法通过翻转正面样本的重要性权重,让模型把更多注意力放在需要改进的部分而非已经表现良好的部分,显著提升了数学推理和编程任务的性能,并改善了训练稳定性。

从“互联”到“智联”:荣耀MagicOS 10如何用“自进化”重构人机关系?

开源红帽,加速AI

让AI学会深度搜索:Fractal AI Research实验室开发出能像侦探一样追踪真相的智能助手

快手科技重磅突破:AI语言模型训练的"权重平衡术"让机器学习更聪明
