 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
围绕“霄龙”扩大产业链,或是AMD重返中国服务器市场的一个策略

CNET科技行者 8月24日 北京消息(文/周雅):继6月20日奥斯汀发布会之后,AMD昨天正式将全套EPYC 7000系列数据中心处理器家族带到中国。

整场发布会的重头戏,是包括腾讯、京东、百度、联想、曙光等十余家产业链合作伙伴带着产品和合作成果为AMD站台点赞,仿佛台上的AMD重返巅峰,可见中国市场将是AMD复兴之路的一个重要阵地,当然更是一个考验——曾在巅峰时刻,AMD服务器最高市场占有率达到27%。
可见,围绕EPYC(霄龙)处理器进一步扩大产业链合作,是AMD打开中国市场的一个策略。
比如,腾讯、百度、京东的站台就能代表互联网市场和云计算市场对EPYC的认可,当然同样能代表这两个市场的阿里巴巴也是AMD的合作伙伴。
实际上,腾讯此前已经在自身的数据中心小规模部署一批采用EPYC(霄龙)CPU的服务器,而京东和百度也直接表态,下半年开始陆续部署EPYC服务器产品。
- 腾讯云高级总监邹贤能表示,腾讯云将于年底前推出基于AMD EPYC(霄龙)处理器的2路云服务器,最高可提供多达64个处理核心(128个线程),拥有超强单机计算能力,为业界提供更多样化的云产品和云服务。
- 百度公司总裁张亚勤表示,搭载AMD EPYC(霄龙)处理器的单插槽服务器能够大幅增加百度数据中心的运算效率,减少总拥有成本,降低能源消耗。百度将随AMD EPYC(霄龙)的发布上市进行同步部署。
- 京东硬件系统部技术负责人王中平表示,中国的互联网、电商企业都需要更多的计算核心和更高的内存带宽。AMD EPYC(霄龙)的资料报告中显示,最高达到32个内核,足以媲美业界通用的两路服务器,8通道的内存接口有利于实现更高的内存通信带宽,相信这些将更加贴近国内互联网企业的需求。京东也将同AMD EPYC(霄龙)一起,不断优化服务器系统的总体拥有成本(TCO),以及未来在大数据,人工智能,云计算等领域方面展开技术合作。
当然,EPYC也覆盖了OEM市场:与AMD合作逾15年的曙光这次带来9款服务器新品,全部基于EPYC平台,涵盖工作站、机架、刀片、整机柜服务器,面向高性能计算、云计算、大数据分析和深度学习等应用;联想、惠普、戴尔、宏碁、华硕五大PC厂商也在跟进EPYC的产品规划,联想将与AMD、Hyperscale共同开发与部署单插槽和双插槽的EPYC。
发布会一大亮点,是多次被提及的人工智能应用,EPYC一大性能,是机器学习。一个重磅消息随之公布,AMD与百度将成立GPU技术联合实验室,推进GPU在人工智能技术的演进。
双方将共同测试、评估和优化AMD的Radeon Instinct加速器,在需求分析、性能优化、定制化开发等多方面密切合作,探索将AMD GPU技术应用于百度数据中心,助力百度人工智能战略的落地。
显而易见的是,在人工智能领域的落地层面,少不了中美大量的企业、机构、研究者积极投身于人工智能技术的研究和商业化。但鲜为人知的是,据公开资料显示,近几年人工智能开始大爆发,很大一部分是由于GPU的广泛应用,使得并行计算变得更快、更便宜、更有效,再加上无限拓展的存储能力和骤然爆发的大数据这两个组合拳,也使得图像数据、文本数据、交易数据、映射数据全面爆发。
资料还显示,传统的通用CPU之所以不适合人工智能算法的执行,主要原因在于其计算指令遵循串行执行的方式,没能发挥出芯片的全部潜力,相较而言,GPU具有高并行结构,在处理图形数据和复杂算法方面拥有比CPU更高的效率。对比GPU和CPU在结构上的差异,CPU大部分面积为控制器和寄存器,而GPU拥有更多的ALU(ARITHMETIC LOGIC UNIT,逻辑运算单元)用于数据处理,这样的结构适合对密集型数据进行并行处理。CPU执行计算任务时,一个时刻只处理一个数据,不存在真正意义上的并行,而GPU具有多个处理器核,在一个时刻可以并行处理多个数据。程序在GPU系统上的运行速度相较于单核CPU往往提升几十倍乃至上千倍。 因此,面向通用计算的GPU已成为加速可并行人工智能应用程序的重要手段。
而AMD Radeon Instinct正在推动真正的新一代异构计算。AMD近日推出的Radeon Instinct MI25、MI8和MI6加速器,结合AMDROCm 1.6软件平台(包括优化的MIOpen框架库),提高了性能、效率和易实施性,加速深度学习推理和工作负载培训等。这些加速器能够满足范围广泛的机器智能应用,包括在学术、政府实验室、能源、生命科学、金融、汽车和其他行业的以数据为中心的HPC级系统。
从这两个角度看,AMD与百度的GPU技术联合实验室,显得既恰逢其实又有的放矢。
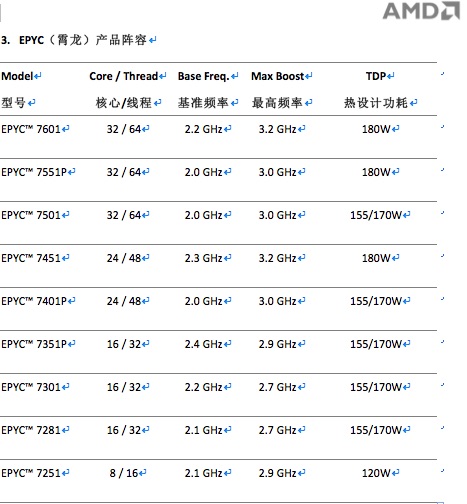
彩蛋,附全套EPYC 7000系列数据中心处理器家族性能一览:




好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来
韩国KAIST开发的Vector Prism系统通过多视角观察和统计推理,解决了AI无法理解SVG图形语义结构的难题。该系统能将用户的自然语言描述自动转换为精美的矢量动画,生成的动画文件比传统视频小54倍,在多项评估中超越顶级竞争对手,为数字创意产业带来重大突破。

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
华为诺亚方舟实验室提出VersatileFFN创新架构,通过模仿人类双重思维模式,设计了宽度和深度两条并行通道,在不增加参数的情况下显著提升大语言模型性能。该方法将单一神经网络分割为虚拟专家并支持循环计算,实现了参数重用和自适应计算分配,为解决AI模型内存成本高、部署难的问题提供了全新思路。

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法

周雅
主编
