 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
图灵大学等多所高校联手:视频生成速度提升3倍,内存节省8GB的"轻量缓存"技术震撼问世
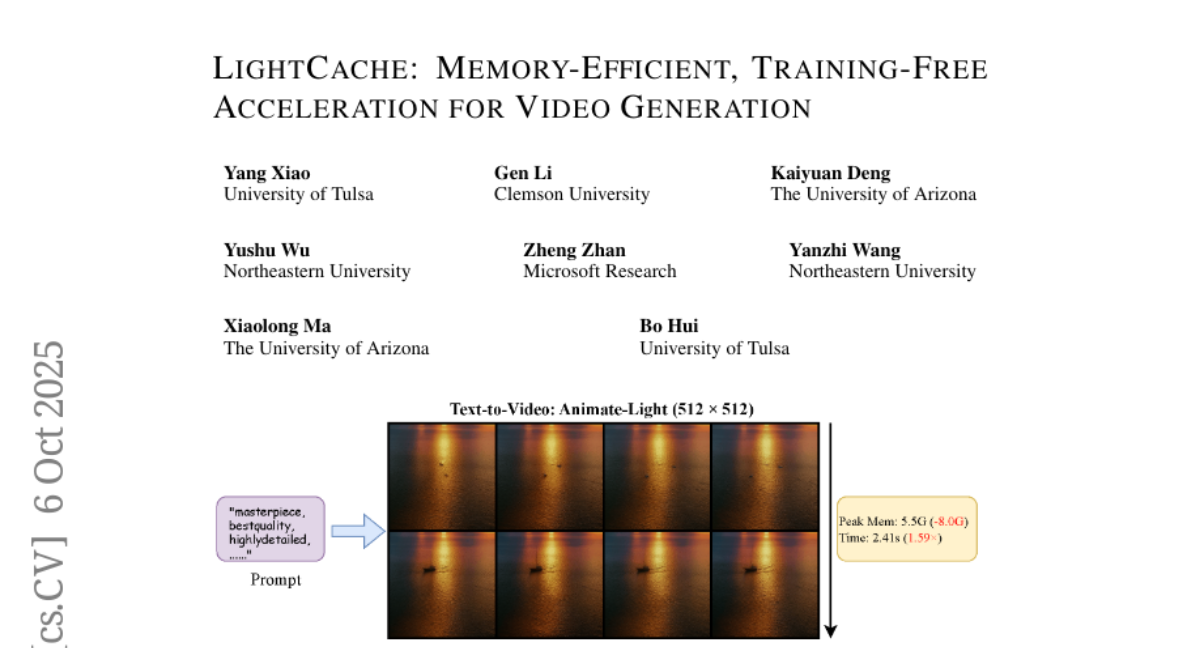
这项由图灵大学(University of Tulsa)杨晓教授领导的国际研究团队的最新成果发表于2025年10月的ArXiv预印本论文库,论文编号为arXiv:2510.05367v1。该研究汇集了克莱姆森大学(Clemson University)、亚利桑那大学(The University of Arizona)、东北大学(Northeastern University)以及微软研究院(Microsoft Research)等多个顶尖机构的专家智慧,他们共同开发了一种名为"LightCache"的革命性技术,专门解决AI视频生成中的"又慢又耗内存"这个老大难问题。
说到AI视频生成,你可以把它想象成一个非常挑剔的画家,需要一笔一笔地慢慢画出每一帧画面。这个过程不仅时间漫长,还需要大量的"画布空间"(内存)来存放中间作品。研究团队发现,现有的加速技术就像给画家配了个助手来重复使用一些已经画好的部分,虽然画得快了,但需要的画布空间却大大增加了。这就好比你的助手虽然帮你节省了时间,但桌子上堆满了各种草稿和半成品,反而让工作空间变得更拥挤。
研究团队通过深入分析发现,整个视频生成过程就像一条流水线,包含三个主要环节:编码(把输入信息转化为机器能理解的格式)、去噪(逐步清晰化画面)和解码(把最终结果转换成我们能看到的视频)。他们惊讶地发现,虽然现有的缓存加速技术能让流水线跑得更快,但内存的大量消耗主要集中在去噪和解码这两个环节,就像工厂里最耗电的不是总开关,而是特定的几台大机器。
基于这个洞察,研究团队设计了三套互相配合的优化策略。第一套策略叫"异步缓存交换",就像一个聪明的仓库管理员,当某些材料暂时用不到时,就悄悄地把它们搬到便宜的远程仓库(CPU内存),需要时再快速调回来,这样既不影响生产效率,又大大节省了昂贵的本地仓库空间(GPU内存)。
第二套策略叫"特征分块",这个方法就像把一张大画布切成几块小画布来分别处理。研究团队发现,画面的高度和宽度可以被巧妙地分割,每次只处理一小块,这样既保证了画面质量,又显著降低了每一时刻需要的内存容量。这种方法特别适用于去噪环节,就像把一个复杂的拼图游戏变成几个简单的小拼图。
第三套策略叫"切片解码",专门针对最后的解码环节。由于AI视频生成通常需要同时处理多个版本的画面(条件版本和无条件版本,用于提高生成质量),最终解码时需要处理的数据量会成倍增加。研究团队的解决方案就像把一大盘菜分成几小盘来上菜,一次只解码几帧画面,虽然需要跑几趟,但每次的压力都大大减小了。
为了验证这些策略的有效性,研究团队在多个主流的AI视频生成模型上进行了广泛测试,包括AnimateDiff-Lightning、Stable-Video-Diffusion-Img2vid-XT等知名系统。测试结果令人印象深刻:在AnimateDiff-Lightning上,他们的方法实现了1.59倍的速度提升,同时节省了8.0GB的内存使用;在Stable-Video-Diffusion上更是达到了2.86倍的速度提升和1.4GB的内存节省。
研究团队还进行了细致的对比实验。他们发现,传统的DeepCache技术虽然能加速生成过程,但会导致内存使用量增加11%到40%,在处理长视频时甚至可能增加96%。另一种名为FME的技术虽然能减少内存使用,但却会让生成速度变慢,而且明显降低视频质量。相比之下,LightCache技术在保持视频质量几乎不变的情况下,既实现了加速又减少了内存消耗,真正做到了"鱼和熊掌兼得"。
在技术细节上,研究团队采用了非常严谨的实验设计。他们使用了四张NVIDIA L40S GPU(每张45GB内存)进行测试,固定使用Euler调度器,分辨率设置为512×512(SVD使用1024×576)。为了确保结果的客观性,他们使用了多种评估指标,包括LPIPS(感知图像差异)、PSNR(峰值信噪比)和SSIM(结构相似性),这些指标就像不同角度的"体检报告",全面评估生成视频的质量。
研究团队还特别关注了实际应用场景。他们测试了不同类型的视频生成任务,从文本到视频、图像到视频等多种应用模式。结果显示,无论是哪种应用场景,LightCache技术都能稳定地提供性能提升。特别值得一提的是,对于一些内存需求极高的模型(如EasyAnimate),传统的DeepCache技术甚至无法正常运行(出现内存不足错误),而LightCache技术却能让这些模型顺利运行并实现显著加速。
为了验证技术的通用性,研究团队还测试了不同的采样调度器,包括DDIM、PNDM和Euler等。结果表明,LightCache技术不依赖于特定的调度器,在各种配置下都能保持良好的性能表现,这意味着这项技术具有很强的适应性和实用价值。
通过详细的消融实验,研究团队进一步验证了三套策略各自的贡献。实验结果显示,异步缓存交换主要影响所有三个处理阶段的内存使用,切片解码主要优化解码阶段,而特征分块则专门针对去噪阶段。三套策略相互配合,就像一个精心设计的团队,每个成员都有自己的专长,合作起来效果显著。
这项研究的意义远不止于技术层面的突破。随着AI生成内容在社交媒体、广告制作、教育培训等领域的广泛应用,生成效率和硬件成本一直是制约其普及的重要因素。LightCache技术的出现,意味着更多的创作者和开发者能够用更便宜的硬件设备制作高质量的AI视频,这将大大降低AI视频制作的门槛。
从技术发展的角度来看,这项研究代表了AI加速技术的一个重要发展方向。与需要重新训练模型的传统加速方法不同,LightCache采用的是"训练无关"的优化策略,这意味着它可以直接应用到现有的各种AI视频生成模型上,无需重新训练或修改模型结构。这种即插即用的特性使其具有巨大的实用价值。
研究团队在论文中也坦诚地讨论了技术的局限性和未来改进方向。他们指出,虽然LightCache在大多数情况下都能保持很好的视频质量,但在某些极端参数设置下可能会出现轻微的质量下降。此外,异步缓存交换虽然能节省内存,但会带来少量的时间开销,尽管这个开销远小于获得的加速收益。
展望未来,研究团队计划将LightCache技术扩展到更多类型的生成模型,包括DiT(Diffusion Transformer)架构,并探索在更长视频序列和多模态生成任务中的应用。他们还考虑将LightCache与其他优化技术结合,进一步提升整体性能。
这项研究的开源精神也值得赞赏。研究团队已经将相关代码发布在GitHub平台上,地址为https://github.com/NKUShaw/LightCache,这使得全世界的研究者和开发者都能受益于这项技术创新。这种开放式的研究方式正是推动AI技术快速发展的重要动力。
从更广阔的视角来看,LightCache技术的成功体现了当前AI研究的一个重要趋势:在追求模型能力提升的同时,越来越多的研究者开始关注效率优化和资源节约。这种平衡发展的理念对于AI技术的可持续发展和广泛应用具有重要意义。
说到底,LightCache技术就像给AI视频生成装上了一个"智能管家",它既不改变原有的"工作流程",又能巧妙地优化资源配置,让整个系统跑得更快、用得更少。这种技术突破不仅解决了当前AI视频生成面临的实际问题,更为未来更复杂、更高质量的AI内容创作铺平了道路。对于普通用户来说,这意味着在不久的将来,我们可能用更便宜的设备就能体验到高质量的AI视频生成服务,AI创作将真正走进千家万户。
Q&A
Q1:LightCache技术是什么?它能解决什么问题?
A:LightCache是一种新的AI视频生成加速技术,专门解决现有视频生成系统"又慢又耗内存"的问题。它就像给AI视频生成装了个智能管家,通过三套策略优化资源使用,既能提升生成速度2-3倍,又能大幅节省内存使用。
Q2:LightCache技术相比其他加速方法有什么优势?
A:与传统的DeepCache技术相比,LightCache在加速的同时还能减少内存使用,而不是增加内存负担。与FME技术相比,LightCache既不会降低生成速度,也不会明显影响视频质量,真正实现了速度、内存和质量的平衡优化。
Q3:普通开发者能使用LightCache技术吗?
A:可以的。研究团队已经将LightCache的代码开源发布在GitHub上,任何开发者都可以免费获取和使用。而且这是一种"即插即用"的技术,不需要重新训练模型,可以直接应用到现有的各种AI视频生成系统中。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来
韩国KAIST开发的Vector Prism系统通过多视角观察和统计推理,解决了AI无法理解SVG图形语义结构的难题。该系统能将用户的自然语言描述自动转换为精美的矢量动画,生成的动画文件比传统视频小54倍,在多项评估中超越顶级竞争对手,为数字创意产业带来重大突破。

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
华为诺亚方舟实验室提出VersatileFFN创新架构,通过模仿人类双重思维模式,设计了宽度和深度两条并行通道,在不增加参数的情况下显著提升大语言模型性能。该方法将单一神经网络分割为虚拟专家并支持循环计算,实现了参数重用和自适应计算分配,为解决AI模型内存成本高、部署难的问题提供了全新思路。

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的"稀疏化魔法"

不用再训练AI模型,香港科技大学团队发明"智能管家",让AI一眼就知道该抓哪里用哪里

韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的"语义迷宫"让静态图标活起来

华为诺亚方舟实验室新突破:不加内存也能让AI变聪明的神奇方法
