 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
2014版ThinkPad X1 Carbon

在CES2014上,联想发布了旗下最新ThinkPad超极本产品2014版ThinkPad X1 Carbon。
2014版Thinkpad X1 Carbon拥有主流的尺寸, 14英寸的屏幕浓缩了高达2560x1440的惊人分辨率;采用碳纤维的材质,刷新14英寸超极本轻量记录;秉承Thinkpad精致商务风格,坚固、轻薄、沉稳的外观,接口齐全;全新按键布局设计,新元素虚拟按键融入,触控功能键设计,非常洋气。
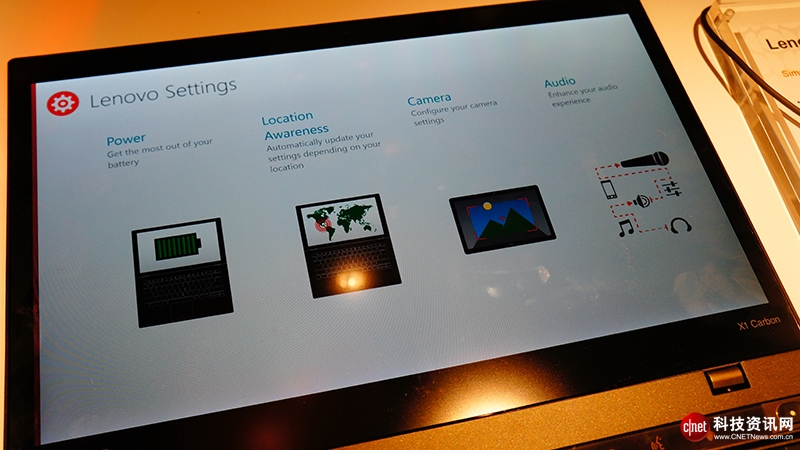
在软件方面,配合Windows 8.1,同时还集成了联想增强版的开始菜单程序,为了简化设置,联想还提供了一个基于触控界面的设置中心,极大程度方便了用户操作。
我们在现场看到,这款产品搭载酷睿i7的高配版本的售价为1299美元,算上税款,含税价格大约是8500元人民币,相信如果是针对主流的i5版本,售价会相当有竞争力。
在联想发布的23款新品中,2014版ThinkPad X1 Carbon绝对是此次CES2014中耀眼的明星之一,是时下全球最轻薄的14英寸超极本产品。
以下是我们在CES2014的现场评测。

首先我们来看看2014版ThinkPad X1 Carbon的外观全景图,仍然继承了小黑的酷黑外观,但同时你也能够感受到很多的时尚元素融入其中,而屏幕上,触摸屏成为了标准的配置,令人惊喜的是,尽管采用了触摸屏,屏幕的厚度对比上一代非触摸版本,并没有太大的变化,从而很好的控制了整机厚度。




再来看看接口部分,超极本为了轻薄设计,往往省略了大量的接口,而2014版ThinkPad X1 Carbon在这点上表现尚可,两个USB 3.0,一个标准HDMI,一个miniDP,还有扩展口,算是比较全的设计了,从侧面我们也可以看到,2014版ThinkPad X1 Carbon真的很薄!


接下来是小黑迷们最关注的键盘以及输入设备部分了,先说触摸板吧,很多小黑迷可能又失望了,2014版ThinkPad X1 Carbon仍然采用了一体式的触摸板,这主要是为了降低产品的整体厚度,不过从现场极其简单的使用感受来看,2014版ThinkPad X1 Carbon的一体式触控板相比之前的产品似乎有所改进。再来看键盘部分,这个部分变动非常大,从原来的六行变成了五行的物理按键加上一行的虚拟按键,虚拟按键部分是原来的F1-F12以及功能快捷键,这样的设计非常时尚,隐隐还有种Android的感觉,但比Android的虚拟按键感觉上更高端,让超极本和平板电脑之间的界限更加模糊了。电源开关和指纹识别基本还保持在了老地方。




接下来来看看屏幕角度,2014版ThinkPad X1 Carbon的屏幕分辨率达到了2560x1440的惊人程度,而开合角度方面和之前的Carbon一样,2014版ThinkPad X1 Carbon的屏幕最大角度是180度,可以放平,但不能折叠,这在保证实用性的同时,也保证了铰链的寿命,提升整机可靠性。



最后看看软件部分,Windows 8.1,同时屏幕右下方还集成了联想增强版的开始菜单程序,这个非常方便,甚至比原版Win7的开始菜单都方便,同时为了简化设置,联想还提供了一个基于触控界面的设置中心,即便是新手也可以快速的在这里调节部分设置选项。

总结下这款产品,并提供下参考价格信息,2014版ThinkPad X1 Carbon无疑是我们在CES2014上看到的优秀超极本产品之一,尤其是触控的功能键设计,非常洋气,我们在现场看到,这款产品搭载酷睿i7的高配版本的售价为1299美元,算上税款,含税价格大约是8500元人民币,相信如果是针对主流的i5版本,售价会相当有竞争力。
最后预告下,明天我们将会对2014版ThinkPad X1 Carbon以及其他联想产品的发布做现场图文直播,欢迎大家到时围观。



好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
