 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
走进甲骨文易用性实验室 像对待艺术品一样雕琢软件

在一般人的概念中,软件看不见摸不着,抽象而冰冷。消费类软件还好,因为或绚或酷的体验让人记住,而企业级软件呢,什么财务啦、考勤啦、客户关系管理啦...要多枯燥有多枯燥,要多刻板有多刻板。
这个印象,在走进甲骨文位于其硅谷总部的应用软件易用性实验室(Oracle Applications User Experience)后,被彻底颠覆了。应用软件易用性实验室负责人Jeremy Ashley学的是艺术设计专业,穿着时尚,在我们给他拍照时像明星般熟练地摆Pose。在他看来,科技人性化特质少,艺术人性化特质多,如果一个软件产品不够人性化,技术上再先进也没有意义。甲骨文易用性实验室要做的,是像对待艺术品一样“雕琢”甲骨文的企业级软件,其最终目标是让使用者的体验更好。
甲骨文应用软件易用性实验室
提起体验,这是一个虽然很抽象,但事实上想象空间巨大的语汇,时代在变化,但Jeremy Ashley认为人类追求的体验的精髓是不变的的,尽管平板电脑、智能手机出现没有几年,但是人们对这些产品的体验感受,其实跟千百年来的体验感受没有本质差异。

应用软件易用性实验室负责人Jeremy Ashley
而既然软件也能是一件艺术品,那么就能表现气质,甲骨文的软件是什么气质?Jeremy Ashley概括为两个词:简约、优雅。这种气质不仅仅让用户体验到,还希望用户借使用这些产品也传达出简约、优雅的气质。这真是艺术家的思维。
在甲骨文,易用性实验室分布在全球各地,已经有20年的历史,而且这是一个由来自20个国家的员工组成的绝对堪称国际化的团队。按照甲骨文软件产品的类别和功能,易用性实验室分为应用软件、BI(商务智能)和中间件3个团队。
Jeremy Ashley的团队,负责应用软件类产品的客户体验。在他看来,再复杂的软件,也只要让用户完成三步:扫一眼、稍微找一找、点击。
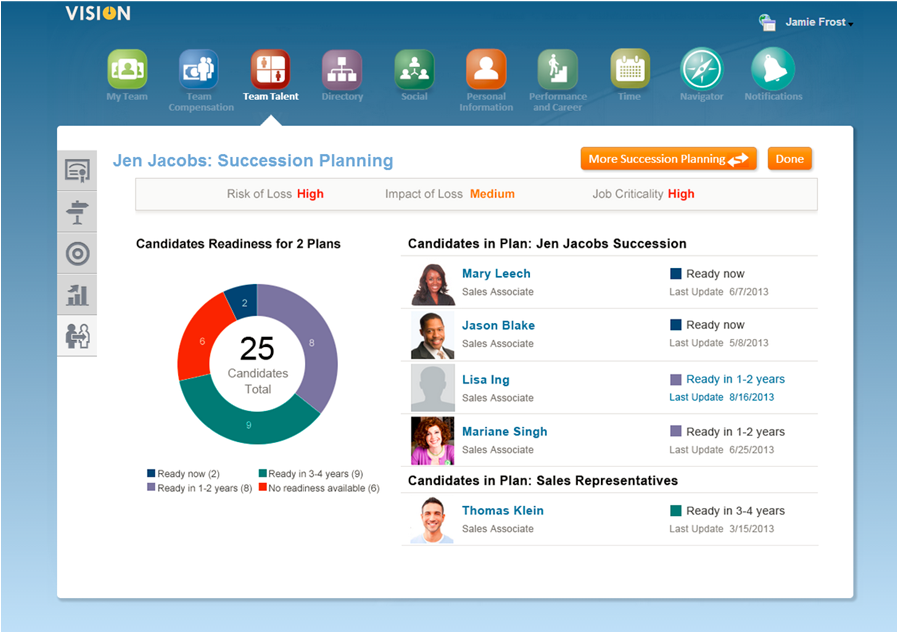
再复杂的软件,让用户用起来也最好只需要三步:扫一眼、稍微找一找、点击。
有句俗语说得好,“由俭入奢易,由奢入俭难”。对Jeremy Ashley团队来说,想做与别人不一样的产品容易,但是想做比别人更好的产品难,也就是说易用性体验以极简为核心,并不追求出风头或者制造噱头。而且看似简单的三步,其背后要做的事情太多了。Jeremy Ashley给我们演示的一个报表操作界面,其背后是8000人通力合作才呈现出我们看到的效果。而且其实这个界面只是一个表面现象,其背后支持界面的内部流程才更为重要,这就好像是冰山露出水面的只有一角,而其实水下的部分才更大。
采访中记者发现,Jeremy Ashley的团队中,所擅长的专业领域真是五花八门,有学艺术的,有学工业设计的,有学社会学的,有学管理工程的。只有把软件当做一个丰满的艺术品,可能才需要各学科赋予这件艺术品智慧,如果单把软件当做有着高科技的产品,庞杂的学科知识反而没有用武之地了。
当今时代,其实对甲骨文易用性实验室提出的挑战也并不仅仅给用户更好体验这么简单。当一个消费者在不同时间、空间变魔术般地切换使用PC、平板设备、智能手机甚至智能手表、智能眼镜等可穿戴设备时,不仅要带给客户单一设备上的良好体验,还要让设备间无论如何切换,体验都不打折扣。索性,因为云计算技术的发展,这一切都能够实现。
然而话说起来容易做起来难。一个PC上呈现的界面,跟一块智能手表呈现的界面当然不能一样。但是PC界面再大也不能把什么都往上放,而智能手表界面再小也不能把某些软件功能砍掉。这时候对于甲骨文易用性实验室来说的挑战,在于你是否能够预先帮助用户去设定好他可能遭遇的场景,并且按照场景设定出终端设备上呈现的体验。
这一体验,依旧是三个步骤:扫一眼、稍微找一找、点击。不会改变。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏
腾讯混元提出CPPO方法,通过位置权重和累积前缀预算两个机制改进AI强化学习训练,在多个Qwen3模型的数学推理任务上超越现有方法,最大提升达5.56分。

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文
PaperMentor是多伦多大学等机构联合开发的AI论文写作导师,通过12个专业智能体和40余份专家技能文件,在Overleaf中为科研人员提供行内批注式的写作建议。

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"
论文揭示AI安全测试的"审计缺口":模型外表安全但内部可能脆弱,并提出潜在脆弱性分数(LVS)量化内部风险。

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
这项研究提出ICMIL框架,让AI通过在合成数据上预训练,无需针对新任务重新训练即可完成多示例学习分类,在十二个基准上超越需要调参的监督方法。

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
