 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
从人的本能看企业运用微信红包之道
年初,我与一位同事到拉斯维加斯参加CES,到了赌城,工作之余如不去赌,这似乎有些暴殄天物了,在带她进赌场之前,我郑重的告诉她:要给自己设立个目标,比如拿50美元在手上,赢钱不说,要是输了,输光了就出来,这是去感受一种另外的生活和娱乐,而不是去烧钱的。可惜知易行难,实际操作起来,完全变样了,在输掉50美元预算的最后一美分时,她下意识的第一个动作是再去掏钱包,而不是转身离开赌场,之后她心有余悸的和我说,在那一刹那之间,根本就没有多想,就是感觉快要赢了,着急再花钱赢回来,什么预算之类的完全抛到九霄云外了。
赌博这个古已有之的老行当,之所以让无数人沉迷其中,很多的原因就是对于未来的不可预知性但又抱有期望,你有赢钱的希望,也有输钱的可能,在完成一次公正的赌博之前,你永远不知道是输还是赢,只有一个概率摆在面前,因此,人们总因为对美好的希望而一次又一次的尝试下去。
实际上,我们每一个人都有赌徒心理,是不是程度的深浅以及体现的领域不同罢了,这其中最重要的原因也是未来的不可预知性,如果你可以判断一个事情100%会发生,那么生活的乐趣就会少了很多。
微信红包其实就是利用了人们这样的一个心理。年初红火的微信红包,相信很多人都有极为深刻的印象,红包最吸引人参与的一点就是领取金额的随机性,一份88元10人瓜分的红包,每一个人拿到的红包有可能是几十元也有可能是几分钱,对于美好的期望,会让人们投入一次又一次的领红包活动中。而如果在这个过程中,未来是可预知的会发生什么呢?比如,直接告诉你,有一个88元的红包,分10分,每人8.8,用户的参与热情就会指数级别的下跌,可预知的未来直接导致的就是无趣感的上升。
这个可预知与不可预知存在着一个极为微妙的平衡,如果一个赌场100%会输钱,只不过输多输少而已,那么不会有人去光顾这个黑店的,平衡就在于,你有希望赢,并且你可以看到这个希望,而实际上这个希望并不大。
回到企业的营销上,企业为了达成很多目的,往往会投入大量的金钱做营销,比如抽奖、赠礼等,但这些活动的吸引力有多大呢?还是回到“不可预知但又抱有期望的未来”这个上,抽奖和赠礼,要么就是让用户觉得完全没有获奖的希望,要么就是未来完全可预知,没有一种可知与不可知之间的微妙平衡,这种平衡恰恰是微信红包可以做到的,这才是人类真实的心理表现。
也就是说,企业完全可以利用微信红包这种特质,利用人类赌博心理的固有天性,来进行市场营销活动。
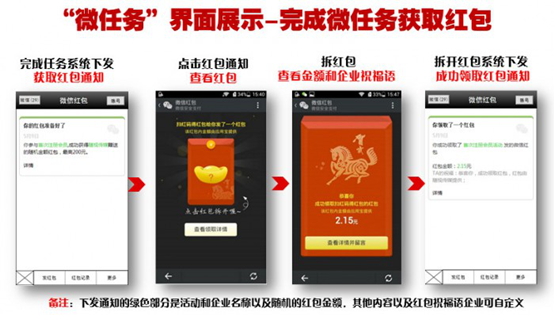
 图1:随视微任务的实现流程
图1:随视微任务的实现流程
一个最为简单的应用就是将线下用户吸聚到线上,形成传统企业的CRM管理体系。传统企业的渠道以线下为主,而且还涉及大量的经销、分销体系,CRM根本无从建立,但利用微信红包,实际上就可以解决这个问题,期望所有用户都自发的关注企业的微信服务号,这显然是不现实的,但如果所有的用户在关注之后,都可以获得企业发放的微信红包,这就不一样了,用户不会期望用这个赚钱,但是这种对未来的不可预知和某种程度的期待,会让用户有着极大的参与热情,这种参与热情远超过固定期待的礼品礼金或者让用户完全感觉不到期待的抽奖。
更为复杂些的应用,企业可以设定一两个线上任务,比如绑定邮箱、手机号之类,完成这些任务之后,同样可以获取红包奖励,相比于传统的抽奖,或者简单粗暴的“送充值卡”之类的活动,这样的活动,用户能够对于活动奖励的发放有更高的信赖感,同时对于活动也有着更大的参与热情。
红包的工作当然不仅于此,只要发挥你的想象,它可以实现一些意想不到的内容。比如仍然对于传统零售的“品牌+加盟”模式,一个统一的市场活动,在各门店的运行状况究竟如何,这是品牌方很难进行统计的,传统的解决方式就是组建一个专门的团队进行巡店,这样效率低、易含水分、主观色彩过于浓厚这些问题姑且不论,对于企业的成本也是不小的负担,尤其是零售门店众多的企业,但如果我们转换下思路,发起一个微任务,让消费者拍摄活动现场的照片,就可以获得红包奖励,这不仅大量节约了巡店人员的成本,还将原来很难统计、很难量化的状态清楚直接的描绘出来。
接下来的问题就是作为一个企业,你怎么去发红包了,众所周知,微信对于红包接口的把控非常严格,除了微信官方自己,目前几乎没有企业服务号可以从技术上实现对用户发放红包,当下开放的红包体系是个人对个人的,而非企业对个人的。
很高兴的是,随视已经解决了这个问题,作为微信的战略合作伙伴,随视传媒已经提前拿到了微信红包的开发接口,在这个接口上进行了大量开发,推出了完善微任务流程体系,企业可以制定规则不一的任务,并针对任务发放红包,当用户完成任务并拆开红包的时候,可获得随机金额的奖励,当然,这个金额的区间也是可以设定的。
图2:随视微任务流程
确实,随视交付给了企业这样的产品和解决方案,但更重要的是,随视交付给了企业一种方法,我们叫做“随视方法”,这个方法可以将一把没有开刃的铁板磨成一把刀,刀的原理都是一样的,利用压强差来切割,但你是削水果还是切菜,就需要结合企业自身的状况再进一步分析和选择了。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。
 2026-07-01 16:42
2026-07-01 16:42阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区
MemoBench是哈佛大学等机构联合推出的视频生成评测基准,专测AI在物体消失再重现场景下的记忆能力,揭示了当前所有主流模型的核心盲区。

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
研究发现AI代码修复工具默认的"写代码→跑测试→再改"流程中,禁止运行测试几乎不影响修复成功率,却能节省超过一半的时间和费用。

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片

阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
