 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
Chromebook处境艰难 高端超便携设备瓜分更多PC市场份额
市场格局正在改变,其中至少部分原因是个人电脑本身的形状也正在发生着变化。
根据美国市场研究公司Gartner最近的研究显示,增长最快的设备类别之一已经为其自己的品牌博得了足够的势头:最新的高端超便携设备(Premium Ultramobile)类别包括苹果MacBook Air、微软Surface Pro以及其他轻便设备,它们有着一台PC或Mac的全部功能,但均对其移动性进行了优化。
相比之下,Chromebook笔记本和向Surface 2这类基于Windows RT系统的设备却陷入困境。
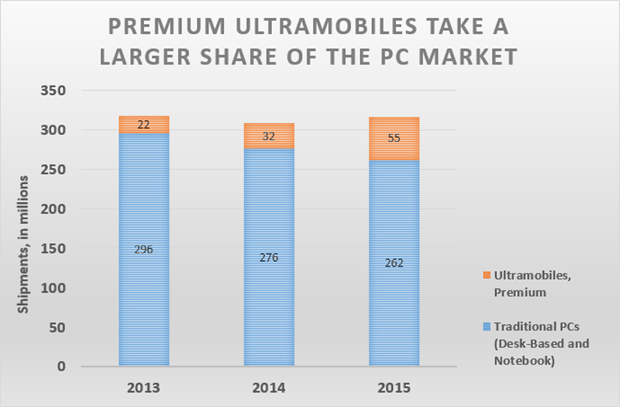
这些均来自于Gartner刚刚发布的全球设备出货量最新预测。正如昨日发布的报道,该研究公司预计在2013年全球PC出货量持续下滑之后,2014年全球PC总出货量将略有增长。而最令人关注的是,这种增长来自哪里。
Gartner预测,高端设备瓜分市场大幅盈利,例如Surface Pro和Macbook Air
近年来,人们对传统台式机和笔记本电脑的需求一直在缓慢下降,但这种下降趋势不仅正在被Gartner称为高端超便携类别的设备强劲的增长所抵消,而且此类设备的增长甚至超过了传统PC的下降速度。
该类别定义如下:高端超便携设备通过优化设备物理特性,将笔记本电脑的应用模式延伸至平板电脑,如设备机身更轻、更小,屏幕尺寸更小(更加方便携带使用),而且能够即时启用。高端超便携设备通常重1.6千克(公斤)或更轻。这类设备均为其媒体消费采用最优化的用户界面,同时保留用于大规模数据处理的功能。这样一台装置能够为用户提供可以媲美基本超便携设备的动力与功能。因此,它将成为一款笔记本电脑的替代品,用户可根据其喜欢的设备特性和他们预期的使用模式在二者之间进行选择。这一设备类别包括采用英特尔x86处理器、搭载Windows 8系统的微软产品和苹果MacBook Air。
其中“采用英特尔x86处理器、搭载Windows 8系统的微软产品”,当前只包含微软更新了三代的Surface Pro系列产品。除MacBook air(并非MacBook Pro)以外,该设备类别还包括了来自联想、戴尔、惠普、宏碁及其他个人电脑制造商的高端超级本和混合设备产品。
Gartner从2012年开始首次发布了超便携设备的销量,当时所报销量为980万台,其中包括苹果MacBook Air和一些早期的Windows混合PC。到2013年,超便携设备的总出货量增长至2150万台,该研究公司预计,超便携设备市场将在2014年增长50%,继而还会在2015年增长70%,预计到2015年,高端超便携设备的出货量将达到5500万台。
如果这些数据准确,那么在2013年,苹果公司共售出1720万台所有配置的Mac,2012年则售出1700万台。其中包括iMac、MacBook Pro、Mac Mini以及计算在传统PC类别中的Mac Pro设备销量。
如果Gartner的预测是准确的,那么到2015年底,高端超便携设备用户基础将在不到三年内便超过1亿。其中,基于Windows的设备大致应占80%左右,其余部分主要由MacBook Air设备组成。
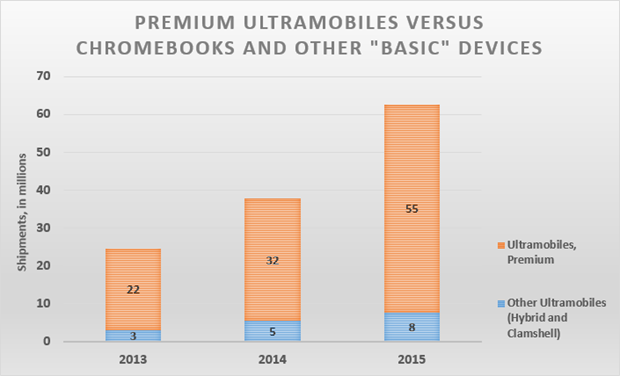
与此同时,Gartner将超便携设备分为了两个子类:基本超便携设备(Basic Ultramobiles)和实用超便携设备(Utility Ultramobiles)。该类别还包括Chrome笔记本以及Windows RT设备,如Surface 2和诺基亚Lumia 2520。Chrome笔记本之所以被认为是基本而非高端超便携设备,是因为在连接不到互联网时,它们的功能非常有限。
基本超便携设备
Gartner预计,从2013年到2015年这三年间,Chrome笔记本、Windows RT设备以及其他混合设备和翻盖式设备总出货量仅1600万台。这一数据与该研究公司对高端超便携设备在同一时期总出货量的预计相比可谓小巫见大巫,Gartner预计后者总出货量为1.08亿台。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
