 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
iOS系统存在安全漏洞 大多iPhone和iPad用户易受攻击
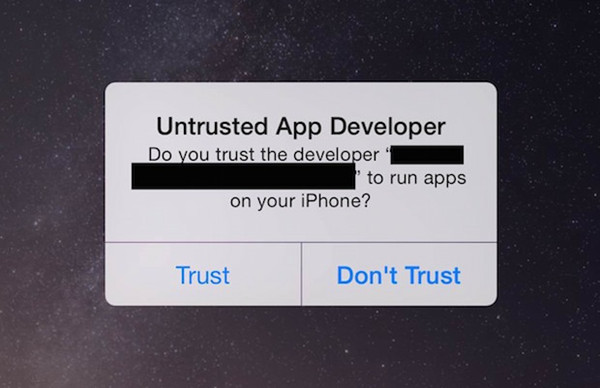
安全研究公司FireEye周一发布的一份最新报告称,在苹果iOS 7.1.1及之后的系统,包括最新的iOS 8和iOS 8.1更新在内,存在一处安全漏洞,该漏洞可导致黑客入侵用户系统并安装恶意程序、窃取用户数据。
FireEye公司研究人员表示,黑客利用该漏洞进行“化妆攻击”(Masque Attack),即引诱用户点击恶意链接、邮件和短信页面而下载恶意程序,从而使这些恶意程序替代来自苹果应用程序商店的银行或社交网络应用。
研究人员称:“该漏洞之所以存在,是因为iOS无法执行相同应用程序标识符匹配的证书所导致。攻击者可以通过无线网络和USB利用这一漏洞。”
研究人员还称,在今年10月的一些专业安全论坛上,曾流出关于该漏洞的一些相关消息。但在此前的7月份,FireEye曾向苹果反馈过这一漏洞。
FireEye表示,公司之所以公开该漏洞,是因为最近Palo Alto Networks公司发现了首个利用该漏洞的恶意代码“WireLurker”攻击案例。“WireLurker”代码可以对苹果的台式机、笔记本以及其他移动设备发起攻击。
FireEye建议,为避免遭到相关攻击,iOS用户最好不要从苹果应用商店之外的其他渠道下载应用,特别是使用那些贴有“不受信任的应用开发者”标签的应用程序。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏
腾讯混元提出CPPO方法,通过位置权重和累积前缀预算两个机制改进AI强化学习训练,在多个Qwen3模型的数学推理任务上超越现有方法,最大提升达5.56分。

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文
PaperMentor是多伦多大学等机构联合开发的AI论文写作导师,通过12个专业智能体和40余份专家技能文件,在Overleaf中为科研人员提供行内批注式的写作建议。

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"
论文揭示AI安全测试的"审计缺口":模型外表安全但内部可能脆弱,并提出潜在脆弱性分数(LVS)量化内部风险。

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
这项研究提出ICMIL框架,让AI通过在合成数据上预训练,无需针对新任务重新训练即可完成多示例学习分类,在十二个基准上超越需要调参的监督方法。

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
