 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
微软发布新广告 再度贬低Siri
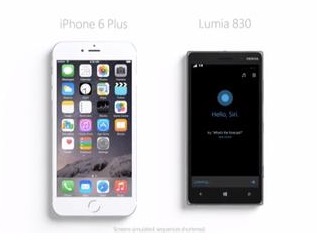
微软在日前发布的一则关于智能语音助手——Cortana的广告中再度贬低Siri。
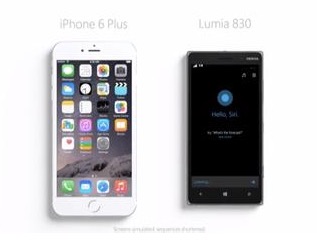
微软在广告中称,作为一款语音助手产品,应当能够根据交通状况信息提示用户出行时间,否则毫无用途。在该广告中,微软采用拟人化表现手法,让Cortana和苹果Siri进行了对话。
微软Cortana对苹果Siri表示,自苹果发布屏幕尺寸更大的iPhone 6以来,Siri需要更多的功能。但Cortana认为,如果智能语音助手不能根据来电或短信向用户做出提醒,那它就不是一款名副其实的“助手”产品。
而这则最新广告,只是微软近来发布的一系列贬低Siri广告之一。很显然,在这一系列广告中,微软瞧不起Siri,这一略显丑陋的灰姑娘。
这则广告体现了微软爽朗的一面,但同时透露出微软“精神分裂”的一面,因为微软开始接受其他硬件产品,试图将自己打造成一个所谓的“生产力”平台。比如,微软在一则关于Sway应用的广告中重点突出了iPad。
在此一天前,微软还在自己的Facebook页面上展示了一张图片和一条通过MacBook使用Skype的视频链接,但坚称这不是一条广告。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。
 2026-07-01 16:42
2026-07-01 16:42阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区
MemoBench是哈佛大学等机构联合推出的视频生成评测基准,专测AI在物体消失再重现场景下的记忆能力,揭示了当前所有主流模型的核心盲区。

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
研究发现AI代码修复工具默认的"写代码→跑测试→再改"流程中,禁止运行测试几乎不影响修复成功率,却能节省超过一半的时间和费用。

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片

阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
