 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
微信测试朋友圈广告遭吐槽 调查称超80%用户不接受

作者:CNET科技资讯网
2015-01-21 09:53
分享至:
根据微信用户反馈,今日早间微信开始在朋友圈测试广告,此举遭到众多吐槽,而一份调查显示,超过80%的用户对于微信朋友圈广告表示不接受。
----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.-
2015-01-21 09:53 • CNET科技资讯网根据微信用户反馈,今日早间微信开始在朋友圈测试广告,此举遭到众多吐槽,而一份新浪的调查显示,超过80%的用户对于微信朋友圈广告表示不接受。
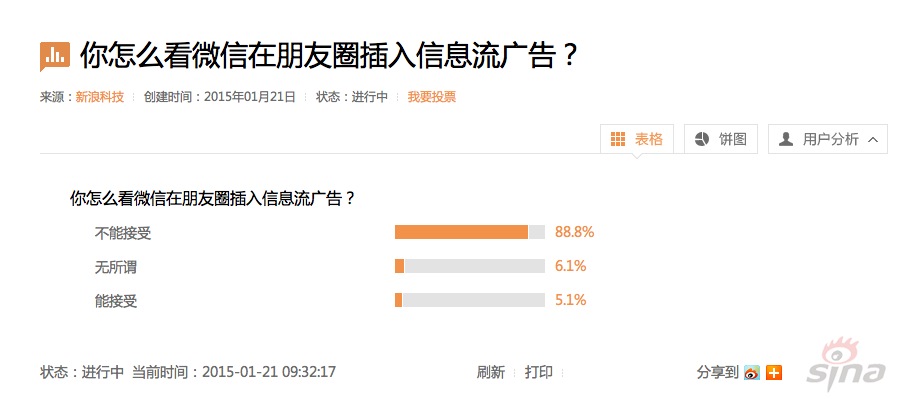
微信对于朋友圈广告是这样描述的:广告也可以是生活的一部分。目前朋友圈广告形式包括图文、链接、推广标识和评论,利用这些形式可以在营销上作出很多创新,并且利用熟人关系的广告,其效果也会很明显。不过重要的是,微信用户并不买账。根据新浪发起的“你怎么看微信在朋友圈插入信息流广告”的调查截止9点32分显示,高达88.8%的用户表示不能接受,6.1%无所谓,仅有5.1%表示可以接受。
许多用户在朋友圈纷纷吐槽,有用户在朋友圈称:想赚钱想疯了!一位用户的说法很贴切:“你以为是自家院子,其实还是公共广场吧?”另一位用户很直白的表示:“我不太能接受,你给我信息就算了,还发我朋友圈。”
目前还无法预测此举会否产生微信用户的流失。不过如果微信一定要商业化,挡也挡不住。
分享至


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。
 2026-07-01 16:42
2026-07-01 16:42阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区
MemoBench是哈佛大学等机构联合推出的视频生成评测基准,专测AI在物体消失再重现场景下的记忆能力,揭示了当前所有主流模型的核心盲区。

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
研究发现AI代码修复工具默认的"写代码→跑测试→再改"流程中,禁止运行测试几乎不影响修复成功率,却能节省超过一半的时间和费用。

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片
2026-07-01 17:11

阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?
2026-07-01 16:42

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区
2026-07-01 16:16

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
2026-07-01 15:44

----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.-