 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
解读百度移动搜索生态体系
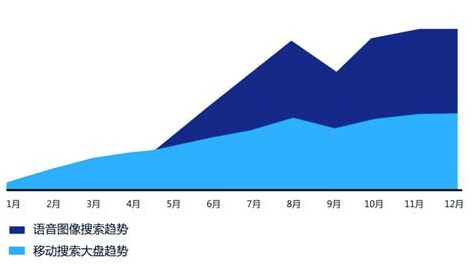
1月21日,百度对外发布《2015年中国移动网站趋势报告》,报告中有三个结果非常值得关注。第一,在百度移动搜索每天导出的十亿量级web流量中,包含教育培训、生活服务、人物、新闻资讯在内四个领域的搜索需求增幅均超过100%并跑赢移动搜索大盘;第二,以语音搜索、图像搜索为代表的以新技术驱动的搜索方式在增幅上也超过了移动搜索的大盘;第三,2015年移动需求缺口最大的将会是生活服务、教育培训和新闻资讯,这三大板块将成为移动搜索的三个极,驱动整个生态的高速成长。
以上三个结果表明,百度移动搜索试图从平台建设、流量引导到技术支持等方面建设的一个从满足用户需求到促进网站收益完整的生态系统已经达成。之所以这么说,是因为打造如上生态体系,需要满足几个硬性条件:是不是多方共赢?是否有导流能力?是否有开放的实力以及提供技术支持的实力?客观的说,百度具备以上能力与实力。
移动网站从百度将获得哪些红利?
百度与移动网站的共赢体现在三个方面,首先体现在流量上:百度移动搜索会为生态内的移动站点提供足够的导流,使移动站点自建立起就有充分的流量保证和持续的增长,而移动站点的流量增长也同时反哺了百度移动搜索流量,增加整个百度移动搜索生态的用户粘性。
其次是收益共赢:想获得收益,抓住用户是关键。双方的合作在促使流量增长的同时,一方面,流量转换率得到提高,因为移动站的建设更加注重优化用户体验,增加了用户粘性和访问停留量。另一方面,受益于流量的增长,拉动移动站和百度双方广告收益。和讯网方面曾经透露,受移动端流量激增影响,今年签下了一宗600万的移动广告大单。
此外,移动网站与百度的共赢还体现在未来成长上:依托百度移动搜索的大数据,可以分析用户的行为习惯、喜好等,分享行业趋势、报告、经验,优化网站、体验等技巧等。据此,为移动网站建设如何优化用户体验提供依据、方向,在竞争中抢占先机。
百度如何为移动站导流?
没有人否认百度是一个超级流量王国,流量是其最大的资本与优势,也助其成为一个平台级的互联网公司。由于百度移动搜索在业内领先,因此处于该生态内的移动站点可以获得的导流量级非常大,百度移动搜索在2014年的日导流已经达到十亿量级。
以魔方格为例,其PC站到目前已经运行16个月,移动端运行8个月,截至2014年11月,二者的流量贡献配比为9:13。其中,移动端54%的流量来自用户的直接访问,42%的流量来自移动搜索的导流,而移动搜索的导流占比有99%来自百度移动搜索,且来自百度移动搜索的留存率高。
从用户访问来说,移动站建设以后,魔方格移动端页面浏览量日均240万,这个数据是PC端PV的近4倍。这个数字并不奇怪,在百度2014年Q3的财报中就显示,来自移动端搜索的流量已经超过PC端,数以万计的移动站的合力创造了这样的成绩,魔方格M站是其中之一。截至2014年11月,魔方格M站每月独立访客已达PC端的80.7%,并呈高速增长趋势。预计今年底,移动端每月的访客量将会超过PC端。可以说百度移动超PC的“完成时”,带动了魔方格移动超PC的“将来时”。
平台资源与技术双开放
百度移动搜索为移动站长提供了一个免费建设移动网站的平台资源,移动站长不需要为建站平台费心。
除了平台资源的开放外,百度也在技术上提供支持。通过技术的支持,降低了移动网站的建设成本。移动网站不是单纯PC端网页的转码,需要解码、转码、适配等技术,百度为移动站长开放了相应的技术支持。同时百度推出一系列服务站长的教程、工具、培训、沙龙,帮助站长更好地建设移动网站,服务网民。
搜索向来是一个生态体系,在移动端更是如此。百度移动搜索不是一个孤立的产品,而是一个以整个移动互联网资源为基础、以网民的需求为导向,将服务提供给网民的多方共赢生态系统。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
