 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
国人对社交媒体满意度下降:都是内容质量惹的祸
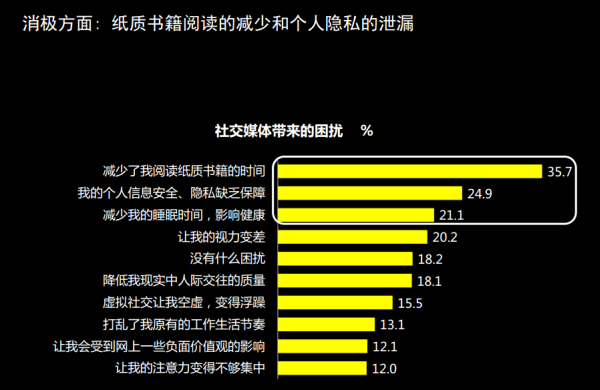
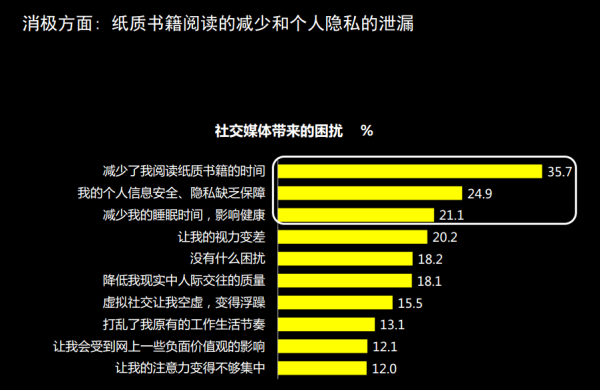
今天,调研机构凯度发布的一项社交媒体满意度调查显示,中国用户开始担心社交媒体给生活所带来的影响,只有64.7%的受访者认为社交媒体带来了正面影响,与去年相比大幅下降了12.1个百分点。
全球调研机构凯度集团(Kantar Group)连续第二年发布了《中国社交媒体影响报告》。该报告同时也指出,社交媒体的使用正在从大城市里接受过高等教育的年轻人群扩张到更小的城市、更多年龄组别和教育水平不那么高的人群。另外,随着中国人越来越多地使用移动互联网,腾讯的微信已经成为了中国社交媒体领域的霸主。
凯度集团是广告传播集团WPP的市场调查分支机构。本次调查利用了大数据挖掘,微博文本分析,微信订阅号文本分析和网上实名制调查四个渠道,共覆盖60个城市,6.6万个实名样本,7.11亿次微信文章点击行为和200万条原创微博内容。
有13,341名实名注册用户参与了该报告的网上调研部分,其中64.7%的用户表示社交媒体对他们生活的影响是正面的,与一年前相比下降了12.1个百分点。与此同时,有12.2%的用户表示社交媒体让他们的生活变糟了,几乎是去年6.7%的两倍。余下的23.3%认为社交媒体对他们的生活没有什么影响,也较一年前的16.5%更高。根据这些数据所折算出的平均满意度得分为68.0分,比去年的73.4分有明显下降。
该报告中还通过针对53,112名中国城市居民的连续性调查发现了社交媒体用户特征的变迁。与一年前相比,城市居民中使用社交媒体的比例从去年的28.6%上升到了34%。90后替代了80后成为了社交媒体用户中最大的年龄组别(37.7%),而60后、50后及年龄更高人群的比例也都在上升,唯一下降的是曾经“一家独大”的80后—他们的比例从44.8%大幅下降到了30.8%。
“任何新生事物都容易受到大家追捧,随着时间的推移,这种追捧会出现下降。社交媒体也不例外,”央视市场研究股份有限公司(CTR)媒介与消费行为研究总经理沈颖评论道。“与此同时,微信使用时间的加长,人们发现微信所关联的人已经从比较小的朋友圈扩展到大的宽泛的交际圈,抓屏的时间越来越长,频次越来越多,且垃圾和重复信息充斥,这引起只浏览不评论不互动的人群从39%上升至46%,增加了7个点,而且社交疏离型人群增长2.1个点。”
“另外,社交媒体的无孔不入也让大家对隐私更重视,希望最高度保护隐私。有不少人因为社交媒体而被别人打扰到了正常的生活,”沈颖解释说。
凯度旗下专业社交媒体分析公司CIC跟踪了50个最热门微信订阅号在107天中所获得的71,276,971次用户点击以分析什么样的订阅号受欢迎,以及人们在微信平台上愿意看什么内容。监测时间段为2014年8月1日至11月15日。
CIC发现50个最热门微信订阅号中有15个娱乐账户,它们所发表的文章获得了49%的点击。相比之下,新闻信息类订阅号虽然有10个挤进了前50,但加起来只占了5%的点击。
对于这50个最热门订阅号而言,它们平均每篇文章有39,531个阅读,154个赞。令人意外的是,热门订阅号发表的文章数并不多:平均一周只有21篇文章。对于前三名(搞笑视频、生活小助手、关爱八卦成长协会)而言,平均数更是低到每周16篇。
CIC的微博文本监测项目跟踪了1万名真实微博用户在一整年中(2013年11月16日至2014年11月15日)所发布的2,098,575条原创微博,以理解人们在微博上聊的热门话题。
娱乐依然是最热门的分类(25.4%),但是新闻事件在微博上很明显更受到关注,它以接近20%的份额(19.6%)排名第二,其它的分类是健康美容(15.7%),工作学习(14.3%),旅游(12%),和其它(13%)。
尽管有不少人认为人们在社交媒体上会更多地表现出负面情绪,但CIC研究了微博上发表的表情符号,证明了这种假设是错误的:有67%的表情符号是正面的,只有33%是负面的。最常用的三种正面表情符号依次是[哈哈],[偷笑]和[呵呵]。而最常见的三种负面表情符号则是[怒]、[泪]和[悲伤]。
“中国社交媒体领域依然在快速变化。营销人员需要通过系统化的研究来更好地了解消费者们是如何各种平台的,他们是如何通过微信和微博来创造、接收和分享信息的,”CIC的创始人兼CEO费嘉明(Sam Flemming)表示。“我们相信尽管现在微信占据了统治地位,但这个领域并不是赢家通吃的。你可以通过微博来感知人们在讨论什么,而微信的订阅号们更像是各种更现代、更适合分享的杂志。我们的研究表明了只有综合利用多个平台才能实现与消费者进行有意义、吸引人和有效的沟通。”


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
