 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
穹顶之外恶意APP泛滥 安全将成移动分发基石
在满朋友圈、微博都刷满了柴静“穹顶之下”的视频时,北京市通信管理局发出的“加强应用商店整改”的要求,几乎被“雾霾”消息挤出视线。但实际上,手机已经成为人们必不可少的外挂器官,恶意APP如同雾霾一样,肉眼难以分辨,且其危害性容易被眼前的“利益”所蒙蔽,所产生的影响十分恶略。

图1:穹顶之外恶意APP丛生
众所周知,国内的安卓分发市场常年处于军阀割据的状态,大大小小的移动市场数十家,且马太效应越发显著。已经形成了由360手机助手居首、腾讯应用宝及百度手机助手三家主导格局。其余中小型分发平台争夺剩余的市场,竞争激烈程度可想而知,部分中小型分发平台并未树立良好的安全意识、为盗版APP的生存与传播提供了温床。
而同时,无本万利的经济驱使了专业“二次打包”APP的灰色产业链,这些投机分子挑选最热门的APP进行二次打包,植入恶意程序、广告、木马,并打着“破解”的旗号招摇撞骗,吸引用户下载,继而达成吸费、窃取隐私等目的,实现盈利。
恶意APP泛滥 应用商店缺乏安全意识
不同于苹果应用商店的封闭式系统,安卓天生的开放性为市场提供了机会,也带来了挑战。究竟国内安卓生态环境中国,盗版APP猖獗到什么程度?据360发布的《移动互联网APP分发行业报告》显示,我国平均每个安卓正版APP有26.3个盗版,而这些盗版应用中隐藏着相当数量的恶意软件。恶意APP横行的现象在安卓平台上尤为严重,知名信息安全公司FireEye发布的一份最新报告指出,96%的移动恶意软件针对的Android操作系统,有超过50亿个被下载的Android应用处在黑客攻击的威胁之下。
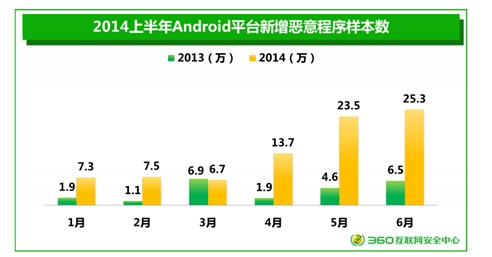
图2:国内安卓平台恶意APP泛滥情况愈演愈烈
另一方面,由于部分移动应用商店缺乏安全审核机制及安全意识,导致部分盗版APP通过有资质的移动应用商店流入市场,对用户产生威胁。在14年11月,国家互联网信息办公室、工业和信息化部、公安部等国家主管部门的统一部署下,共有21家应用商店中有67款恶意应用程序被下架,其中不乏百度、安卓商店等大家耳熟能详的分发平台。
而近日,由北京市通信管理局召开的会议再次对2014年Q4抽查的13家应用平台的73款违规产品进行了通报批评,所通报产品主要存在未经用户同意收集用户信息、恶意扣费、强行捆绑推广其他无关应用软件等违规问题,加强应用商店整改迫在眉睫。
安全应为应用商店第一原则
虽然至今并没有确切的法律法规出台,目前仍靠行业自律及个别机构不定期抽查来督促行业自律。对此,相关负责人表示,应用商店的安全性应该是发展的根基,360手机助手已经构建了一套完善的安全检测系统,所有上架的APP并需经过QVS引擎、云引擎、自动审核、定期回归、人工审查以及用户举报六层安全防护体系的考验。

图3:360手机助手审核过程严格
此外,安卓应用的下载渠道多种多样,移动应用商店并非单一渠道,搜索引擎、二维码下载仍占有一定的比例。但由于这些“游击”的存在模式,更加加大了抽检的难度,安全检测更是无从谈起,用户应尽量避免下载。
行业监管 安全审核机制亟待完善
虽然行业法规尚未出台,但不定期的抽查行为已经说明了国家对于移动应用安全的重视程度,从无抽查到不定期抽查已经迈出了历时性的一步。可以说手机APP面对的问题与雾霾一样的严峻,一样的会对“不知情”的大众产生难以预估的影响。也就是在行业自律和法律法规完善的同时,用户也需要了解山寨APP的危害,尽量选择具有安全审核机制的平台下载。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
