 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
谷歌开放搜索历史记录供用户下载
作者:凤凰网
2015-04-21 09:17
分享至:
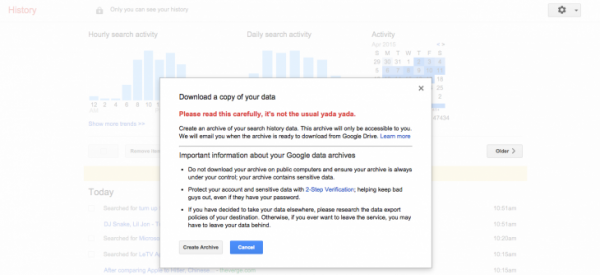
谷歌非官方博客博主发现,现在用户可在谷歌下载自己的搜索历史记录。需要注意的是,用户只有在账户设置当中打开保存搜索记录功能,并且登陆到谷歌账户,才能下载搜索历史记录。下载搜索历史记录是谷歌Takeout政策的新内容,让用户更容易获得他们自己的数据。
----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.-
2015-04-21 09:17 • 凤凰网谷歌非官方博客博主发现,现在用户可以在谷歌下载自己的搜索历史记录。操作方法很简单,用户登陆自己的谷歌账户之后,在谷歌主页右上方点击齿轮图 标,选择下载即可。谷歌为每个用户保存了一段时间的搜索历史记录,按照季度存档供用户下载。一旦用户要求下载搜索历史记录,用户会立即通过Gmail获得 在谷歌Drive上的下载链接,用户可以用zip格式,将其下载到本地硬盘。
https://support.google.com/websearch/answer/6068625?p=ws_history_download&rd=1
需要注意的是,用户只有在账户设置当中打开保存搜索记录功能,并且登陆到谷歌账户,才能下载搜索历史记录。下载搜索历史记录是谷歌Takeout政策的新内容,让用户更容易获得他们自己的数据。

分享至


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏
腾讯混元提出CPPO方法,通过位置权重和累积前缀预算两个机制改进AI强化学习训练,在多个Qwen3模型的数学推理任务上超越现有方法,最大提升达5.56分。

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文
PaperMentor是多伦多大学等机构联合开发的AI论文写作导师,通过12个专业智能体和40余份专家技能文件,在Overleaf中为科研人员提供行内批注式的写作建议。

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"
论文揭示AI安全测试的"审计缺口":模型外表安全但内部可能脆弱,并提出潜在脆弱性分数(LVS)量化内部风险。

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
这项研究提出ICMIL框架,让AI通过在合成数据上预训练,无需针对新任务重新训练即可完成多示例学习分类,在十二个基准上超越需要调参的监督方法。

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏
2026-06-17 17:36

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文
2026-06-17 17:18

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"
2026-06-17 17:08

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
2026-06-17 16:50

----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.-