 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
大数据重构风控体系 或成为互联网金融核心竞争武器
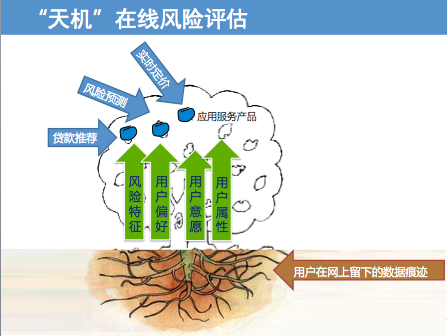
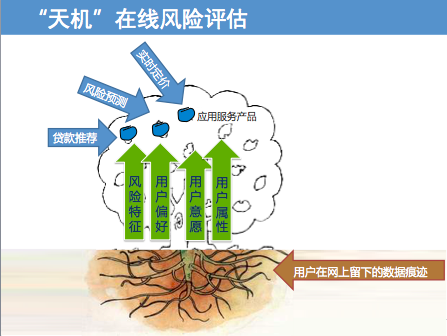
针对5万元以下的个人信用贷款申请,在线金融搜索服务融360开始悄然使用了一个名为“天机”的风控系统。这个系统包含一组模型,会根据身份认证、还款意愿和还款能力三个大维度,给申请贷款的用户进行信用评分,依据分值来决定是否应放款。融360联合创始人、CEO叶大清现场介绍,融360开发大数据风控系统,是要通过积累的数据和风险技术更好服务于自有平台的贷款人和合作伙伴,“天机”满足2千-5万的个人信贷需求。
融360负责风控业务的副总裁李英浩透露,目前“天机”系统已经极大支持了平台的某些小额贷款产品。基于借款申请人自主提交的个人数据,可以做到10分钟左右完成审批,最快当天放款。
大数据重构风控体系
李英浩指出,信用评估自动化加速了整个信贷决策过程,申请人可以更迅速地得到答复,提高了从申请到获批整个流程的效率。据李英浩解释,针对特定细分市场,融360的目标是力争5万以内的小额贷款平均12小时放款。而相比而言,人工审核一般需要一周以上才能放款,慢的可能两个月。
除了贷款审批速度实现了突破,贷款获批率也得到了显著提升,同一类用户,用抵押物、收入流水证明等粗放式的传统风控方式,贷款获批率在15%左右,而使用大数据模型结合人工后获批率可以达到30%以上。至于贷款的逾期率,以12个月违约风险举例,通过“天机”模型筛选的用户,逾期率比没有经过筛选的低一半。
融360并不是第一家在大数据风控系统上发力的互联网金融企业,事实上蚂蚁金服旗下的芝麻信用、一些P2P网贷平台都在陆续开始研发大数据信用评估模型。基于大数据的风控模型正在成为互联网金融领域一个热门的战场,这是因为谁在这个领域实现突破,谁将致胜下一步互联网金融市场。
多年来,金融机构很大程度上都依赖于央行征信报告来决定是否给个人客户授信。但13亿人中有10亿人并没有信贷记录,加之个人客户往往是贷款额度小、需求分散、个性化需求多,使得大多传统银行想做零售贷款而力不从心。因获客、评估、审核和风控都靠人工,传统银行的运营成本过高,面对广大个人消费者这一潜在客户群,银行只能望洋兴叹。
融360联合创始人、CEO叶大清表示,互联网金融不能简单将传统金融服务模式往线上一搬了之。互联网金融的核心竞争力并不是营销获客能力,而是大数据风控能力。即借助于更加广泛的数据,让那些在央行征信系统没有信用记录的个人消费者和小微企业主也有可能申请到贷款。
风险评估主要靠智能模型
大数据风控系统之所以成为可能,是因为每个人在网上留下的数据痕迹,通过大数据的分析和预测技术,就可以智能化判断一个人的信用风险。例如融360正在广泛的收集数据、并深入挖掘数据中衍生的特征,这些特征会被分类成多个维度,如风险特征、用户偏好、用户意愿、用户属性等。通过丰富的用户特征,融360综合应用传统金融模型和机器学习模型,搭建整体“天机”系统的架构,并通过模型构建贷款推荐、风险预测、实时定价等一系列应用服务产品。
用户在互联网上留下的足迹有社交媒体上的动态、电商消费行为、网站浏览痕迹。李英浩介绍,通过风控模型的梳理和分析,就能得出有关贷款行为的需求、申请什么类型贷款、申请金额,逾期及违约可能性等结论,这构成了对个人用户进行信用风险评估。用户看不到自己的信用分值,只能看到最终获批的额度、利率和期限。
叶大清表示,天机风控系统的诞生,意味着融360逐渐演变成金融机构的技术服务合作伙伴,对于用户和合作伙伴来说,融360最大的价值是隐藏于后台的专业风控模型和风控管理能力。
或将成为互联网金融核心竞争武器
去年4月份融360就成立了风控数据部门,并于当年初步完成风控系统的开发。李英浩表示,大数据风控是一个需要不断完善优化的过程,从来就没有标准的解决方案。因此融360采取了开放合作的态度,李英浩透露,芝麻信用和融360在模型和产品方面正在进行深入合作的探讨。
目前,大数据风控最有条件的仍然是阿里和腾讯。阿里推出了面向社会的信用服务体系芝麻信用,除了接入阿里的电商数据和蚂蚁金服的互联网金融数据外,还与外部的公共机构、商业机构达成广泛的合作。腾讯掌握着基于微信的社交信息数据,也即将推出自己的大数据征信。
作为金融垂直搜索服务,融360过去三年半积累了大量的信贷用户数据,帮助用户成功获取了超过3000亿元贷款。在借款人访问数据、用户申请资质信息、网站行为数据、批贷信息和贷后信息方面也拥有独一无二的优势。叶大清特别强调,融360开发大数据风控系统,不是要做征信服务,而是通过积累的数据和风险技术更好服务于自有平台的贷款人和合作伙伴。
可以预见,大数据风控正在成为包括融360在内的几乎所有互联网金融平台争相抢占的一个市场高地。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
