 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
内存技术革命? AMD推高带宽内存HBM
近期,AMD在纽约举办的分析师大会(Financial Analyst Day)上展示了很多新产品与新技术,其中,HBM晶片堆栈式高带宽内存吸引了很多人的目光,AMD总裁兼首席执行官苏姿丰博士表示,HBM是真正能够以更高的带宽、更低的功耗来提供很好的效能。
HBM有何优势?它会何时推出呢?带着这些问题,我们采访了AMD事业群首席技术官(Business Unit CTO) Joe Macri,他表示,HBM在整个功耗降低方面做的非常好,它把所有节省的功耗用于补偿GPU核心的功耗;另外,数据传输的带宽大约是每秒100GB。

图为AMD事业群首席技术官(Business Unit CTO) Joe Macri
AMD开发HBM已经有7年的历史了,是什么原因使得AMD对HBM产生了这么大的兴趣?Joe Macri表示,如今很多系统的问题是功耗较大,很多高端显卡的功耗在250w-300w之间。有时会碰到一种极限,当GPU性能已经很高时,功耗也非常高,内存的功耗也变得非常高,那是一个非常可怕的事情,会造成整个系统热量非常大,功耗很高,但是性能提升却有限。很多时候为了保持系统功耗的平衡,内存功耗很高的话,GPU的功耗就不可以很高,这样会直接影响到GPU的性能。而AMD就想要生产出高带宽、低功耗的内存,这样就可以平衡整个系统的性能和功耗。
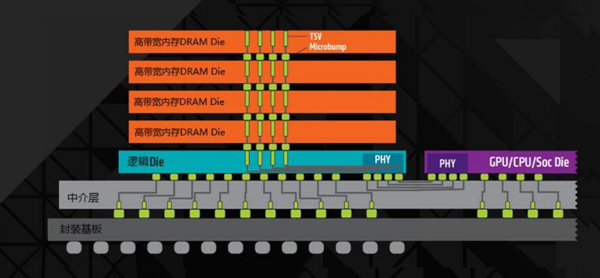
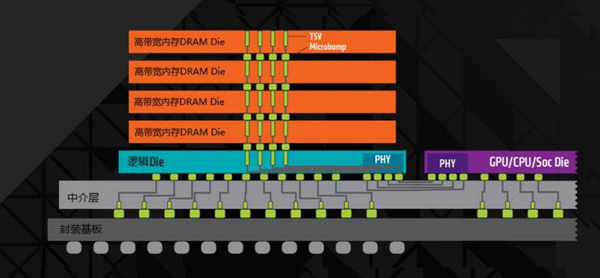
如上图所示,垂直的“四条线”是比较有功能性的DRAM的堆栈,这也是HBM整个内存的晶片构造,出自SK Hynix。左边蓝色的是整套SK Hynix内存的HBM晶片,右边是AMD GPU的晶片。Joe Macri表示,通过1024位连线进行联系,有非常高速的硅晶片的铜联线来进行数据交互,数据非常大且速度非常快,这是不能通过主板来解决的,必须通过这种联线来做到,另外,HBM能够与CPU/GPU封装在一起。
HBM真正实现了低功耗和高带宽,它的外形很小,并且可以把更多的功耗转移到GPU,而且很多用途可以并到HBM,除了独立显卡和游戏以外,像HPC超级计算机、高性能计算、电信、服务器、还有所有类型的PC都会从中受益。
我们所熟悉的DDR5与HBM相比有很大的区别,就是带宽上很不一样,DDR5是32位,HBM则是1024位。Joe Macri解释道,最重要的是它的时钟频率,DDR5是1750兆赫兹,每秒7GB的数据传输量;HBM的整个速度降低得非常快,最高才到500兆赫兹,1GB数据传输量,速率的降低大量地节省了功耗,这是最重要的一点。而整个数据传输的带宽,DDR5是28GB每秒每个芯片,HBM大约是每秒100GB,它的功耗也大大降低了,但是由于整个位宽比较高,所以整个数据传输的带宽是非常高的,大概是过去的5倍。
Joe Macri表示,AMD在建立一个HBM的完整的生态系统,主要包括DRAM、组装和封装、芯片测试。AMD是第一家开始做HBM的公司,不过随后一定也会有其他公司陆续加入。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

南方科技大学等机构联手破解AI推理训练难题:让大模型"一次思考"就学会解题
本文介绍了由南方科技大学等机构于2026年4月发表的研究(arXiv:2604.08865),提出了名为SPPO的大模型推理训练新方法。该方法将推理任务重新建模为"序列级情境赌博机",用一个轻量级价值模型预测题目难度,以单次采样替代GRPO的多次采样,解决了标准PPO的"尾部效应"问题。实验显示,SPPO在数学基准测试上超越GRPO,训练速度提升约5.9倍,配合小尺寸价值模型还能显著降低显存占用。

香港科技大学数学系研究者:扩散模型原来是一个"魔法恒等式"拆成了两半
这项由香港科技大学数学系完成的研究(arXiv:2604.10465,2026年ICLR博客论文赛道)提出了一种从朗之万动力学视角理解扩散模型的统一框架。研究指出,扩散模型的前向加噪和逆向去噪过程,本质上是朗之万动力学这一"分布恒等操作"被拆成了两半。在这个视角下,VP、VE-Karras和Flow Matching等不同参数化的模型可被精确互译,SDE与ODE版本可被统一解释,扩散模型相对VAE的理论优势得以阐明,Flow Matching与得分匹配的等价性也得到了严格论证。

中国人民大学研究团队打造的"AI科学家":让机器自主完成几十小时的科研工程,它是怎么做到的?
中国人民大学高岭人工智能学院等机构联合开发了AiScientist系统,旨在让AI自主完成机器学习研究的完整工程流程,包括读论文、搭环境、写代码、跑实验和迭代调试,全程无需人工干预。系统核心设计是"薄控制、厚状态":由轻量指挥官协调专业代理团队,通过"文件即通道"机制将所有中间成果持久化存储,使每轮工作都能建立在前一轮积累的基础上。在PaperBench和MLE-Bench Lite两个基准上,系统表现显著优于现有最强对比系统,论文发布于2026年4月。

字节跳动发布GRN:像人类画家一样"边画边改"的AI图像生成新范式
这项由字节跳动发布的研究(arXiv:2604.13030)提出了生成式精化网络(GRN),一套模仿人类画家"边画边改"直觉的视觉生成新框架。其核心包括两项创新:层级二进制量化(HBQ)通过多轮二分逼近实现近乎无损的离散图像编码,以及全局精化机制允许模型在每一步对整张图像的所有位置重新预测并随时纠错,从根本上解决了自回归模型的误差积累问题。配合基于熵值的自适应步数调度,GRN在ImageNet图像重建(rFID 0.56)和生成(gFID 1.81)上均创下新纪录,并在文本生成图像和视频任务上以20亿参数达到同等规模方法的领先水平。

南方科技大学等机构联手破解AI推理训练难题:让大模型"一次思考"就学会解题

香港科技大学数学系研究者:扩散模型原来是一个"魔法恒等式"拆成了两半

中国人民大学研究团队打造的"AI科学家":让机器自主完成几十小时的科研工程,它是怎么做到的?

字节跳动发布GRN:像人类画家一样"边画边改"的AI图像生成新范式
