 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
杨元庆:联想要让所有信息下能接地气 上能传云端

连接和云技术,任何物品都变得鲜活,而联想,想要把这些都承包起来。联想集团董事长兼CEO杨元庆在联想科技创新大会(Lenovo TechWorld)上提出,人、设备、网络、数据、应用、服务之间的无限通联,是联想的智能互联愿景。以设备闻名的联想意识到,仅仅硬件已经远远不够,“未来的设备将是硬件、软件和云服务的完美结合、完美统一。”
随之,联想现场展示了在智能互联领域一部分方面的进展。
下能接地气
“魔幻屏”是全球市场上第一款双屏幕手表。看似只是让智能手表更大屏,实际上背后联想提交了120项专利才做到。它的第二块屏幕能够突破主屏幕外形尺寸的限制,利用光学反射原理,在第二块屏幕上创造一个虚拟图像,可以将图像放大至表盘显示屏的20倍,在智能手表上完成查地图,看照片,甚至是看视频,该技术叫做交互式虚拟显示技术,让虚拟旅行成为可能。
把键盘、乐谱都装进手机投影出来,Smart Cast做到了。现场瞬间切换成朗朗弹奏钢琴,杨元庆在旁翻琴谱的画风,一首名曲“The Entertainer”让人陶醉。不过,翻的不是真琴谱,只是联想“智能投影”:Smart Cast。Smart Cast是一种内置激光投影仪、红外运动检测器和高性能算法的智能功能,只要打开产品的投影仪功能,用户便能将一面墙变成一个放映厅,看视频,做演讲,甚至可以通过手势操作。这样一来,在桌子上切水果,在墙上打枪战,并非难事。
一款不仅可以在屏幕上显示穿戴者的情绪,追踪并分析健身数据,根据健身数据自由定制,甚至提供地图导航服务的智能跑鞋概念同样来自于联想智能云的IoT生态系统愿景。

除了硬件产品,联想还在大会上展示了Cortana+WRITEit技术,该技术结合语音和手写笔两大输入方式,扩展了小娜的搜索能力,使之能够覆盖非微软的服务。通过创建REACHit账户,能迅速搜索到谷歌云端硬盘、Dropbox、Box、OneDrive、远程PC及平板电脑的资料与文件。
人机交互的方式很多种,识别算一个。识别技术让手势、语言和面部表情都在成为了输入方式。杨元庆与英特尔CEO科再奇(BrianKrzanich)一同展示了新一代英特尔RealSense Camera ,这款摄像头专为平板电脑和移动机身设计,可实现3D扫描。现在,该功能将成为联想设备上的可选项。
作为人机交互的另一种方式,会话功能同样重要。计算机可根据自身对图片的认知,理解用户的问题,并自行组织语言作答是百度人工智能的最新技术成果。百度董事长兼CEO李彦宏表示,基于人工智能的图片语音识别技术已经广泛应用,从看到一件漂亮的衣服,经拍照得到购买路径;到通过游客所拍摄的照片,虚拟还原震前景况,技术创新在改变生活。此外,百度翻译APP即将上线新功能:用户用手机拍摄外文菜单,百度就能立刻将其翻译为中文,让不同语言的人直接交流。
上能传云端
联想期望打造的是一个开阔的平台,在这个平台上,联想通过云把全球的创新牛人集中在一起,借助联想的资源优势,打造一个基于联想云基础架构的物联网生态系统。该系统包括SDK平台、拥有不同领域专家的创新孵化器、智能设备、供应链以及强大的后端云基础架构。
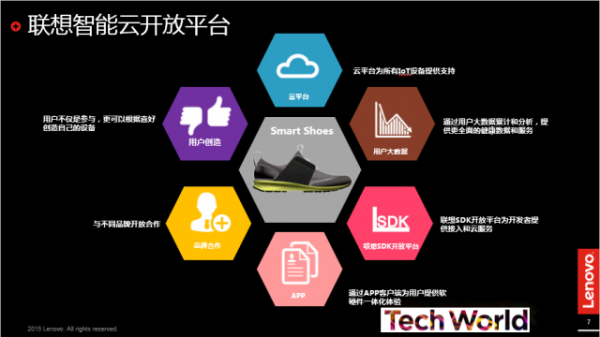
同样在这个平台上,联想云服务的使命就是以‘设备+云服务’的模式,聚焦个人云和企业云服务,开拓联网服务。为了粘住用户,联想有三招:第一招是安全和系统优化,通过大数据,对用户设备的系统安全、性能、体验持续优化,好比乐安全,坐拥用户超过1亿;第二招是个人数据和连接管理,通过搭建跨设备的用户管理平台,对用户关系进行管理,茄子快传就是数据传输工具的成功应用;第三招是应用和内容分发,用户可以在联想乐商店、游戏中心随心所欲下载各种内容。
在“互联网+”的使命下,杨元庆解读智能互联为5个环节:把人和设备以更自然的方式连接在一起;让设备和网络之间的连接更牢固;让设备和设备在共同的平台下互联;通过个人云和大数据实现用户之间的连接;实现设备与应用与服务的无缝互联。并用获取、分享、输入、交互四种技术总结了信息流通的所有方面。
这份新鲜出炉的“智能互联”(IoT)引人遐想,这不是天马行空的睡前故事,可以预见的是,在不久的将来,这些或许都将实现。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
