 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
由支付宝引发的“战争”:多活能不能战胜挖掘机?

支付宝昨日发生大面积访问和交易故障的事件令人记忆犹新,在网商银行即将开业之际,对蚂蚁金服来说,无疑迎来当头一棒。因为网商银行声称是中国第一家完全跑在“云”上的银行,这也是蚂蚁金融服务集团积极推动的旗舰业务。
事件一出,支付宝官方称因市政施工导致杭州市某地光缆被挖断,使支付宝一个主要机房被影响,从而出现访问故障。
超过2个小时后,支付宝恢复服务,并称其异地多活的系统架构在此次意外中发挥了巨大作用。
对于此类解释,遭来了众多业内专业人士的质疑。在我们的采访中,不论是IT提供商、企业用户还是分析师,他们都认为,“由链路(所谓的光纤被挖断,戏称挖掘机事件)原因导致的网络中断在大部分IT事故中并不算严重的。”
为什么?因为数据中心的灾备能力,这是很多大型企业构建的IT架构的一部分。对于支付宝来说,更不例外,尤其支付宝还坚称其异地多活发挥作用。
不说全业务恢复,支付宝最起码的做到正常登录总没问题吧?
一位长期观察企业级IT的资深媒体人直言,“RTO(Recovery Time Objective,恢复时间目标)超过两个小时,还能说得上多活,简直笑话。”
这和有观点认为支付宝事件是中国金融史上首次完全意义的灾难恢复案例观点相左。
“多活”如此引人争议,我们就来看一看它的来龙去脉。
我们来说所谓多活本身的概念,一是多中心之间地位均等,正常模式下协同工作,并行的为业务访问提供服务;二是在一个数据中心发生故障或灾难的情况下,其他数据中心可以正常运行并对关键业务或全部业务实现接管,达到互为备份的效果,实现用户的“故障无感知”。
看上去,多活简直简直就是数据中心灾难恢复的救火队长啊!那到底支付宝的灾备建设是什么样子的呢?多活的技术指标是什么?异地多活,异地是什么,多活又是几活呢?支付宝在那两个多小时的时间里又是怎样进行异地多活的呢?
我们迫切想知道这些问题的答案,因为这些答案最能说明真相。
不过我们在对支付宝的采访中,对方并没有给出回复。
在早前我们对某IT提供商的采访中说到,“双活已经部署在了其大型客户的IT架构中,它实现的是一键配置,一键容灾,在分钟内实现。这不是一个概念,而是客户的实际运行状况,两个数据中心融合在一起,并行和双活使用。”
这种灾备级的能力使得用户所有的业务系统在两个或多个数据中心同时运行,同时为用户提供服务,当某个数据中心的单个或整个应用系统出现问题时,都可以由另一个数据中心的对应系统来接管全部业务,实现持续的服务提供,对用户来讲甚至感知不到业务系统的跨数据中心切换。
阿里巴巴技术保障部研究员毕玄在今年四月份接受某技术媒体采访谈到其主导的数据中心异地多活项目说到,“淘宝因为能够做到异地多活,并且流量是可以随时切换的,所以对于我们来讲,如果一地出现故障,不管是什么原因,最容易的解决方案,就是把这一地的流量全部切走。这样可以把故障控制在一分钟以内,整个可用性是非常高的。”
当然这是在进行中的项目,也就是其定的标准目标是这样的,现在看来,这还差点距离。
其实关于灾备,国务院信息化工作办公室在2007年7月将领导编制的《重要信息系统灾难恢复指南》正式升级成为国家标准《信息系统灾难恢复规范》(GB/T 20988-2007 )。这是中国灾难备份与恢复行业的第一个国家标准,并于2007年11月1日开始正式实施,并作为各行业进行灾备建设的重要参考性文件。
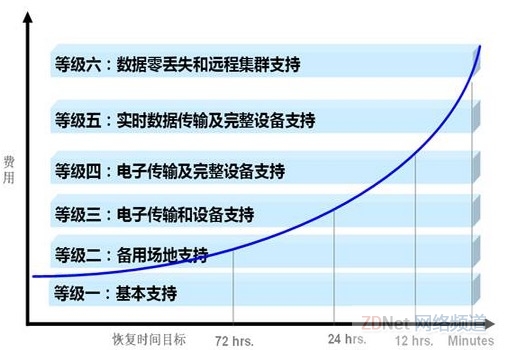
《规范》在附录A对灾难恢复能力作了等级划分,共6级:第1级 基本支持,第2级 备用场地支持,第3级 电子传输和部分设备支持,第4级 电子传输及完整设备支持,第5级 实时数据传输及完整设备支持,第6级 数据零丢失和远程集群支持。
并指出信息系统灾难恢复能力等级与恢复时间目标(RTO)和恢复点目标(RPO)的对应关系。
因为没有得到支付宝的答案,我们不知道支付宝的标准是什么,当然对照此表你可以参考支付宝的灾难恢复能力等级。
其实,也有专业人士指出多活的挑战性:在技术层面,不仅涉及到服务器/虚拟机之间的集群协同,还包括数据的复制与同步,更重要的是涉及到跨数据中心的网络互联互通及分支/Internet用户对DC的访问,因此网络对业务的感知能力及对流量的牵引成为方案设计与部署的重中之重。此外,网络访问控制策略的迁移、服务器网关及数据同步对网络带宽与服务质量的要求、IP地址设置、路由发布控制、网关设计、防火墙状态会话、流量路径规划及迂回控制等技术都是设计上必须要考虑和解决的问题。
反正,我们看下来,多活的最高境界这样子的:如果中断了一个数据中心,其他的数据中心仍可独立响应业务,对用户来说业务切换是无感知的。
再有一个参考,去年笔者曾采访过某IT大型企业,在他们的容灾演练中,两个数据中心相隔1300公里,2小时成功切换关键业务系统,4小时切换全部业务系统,细分下来共包括500多个IT系统,整个切换没有任何数据丢失和不一致。当然那不是双活也不是多活,作为非技术专业人士我不知道这对支付宝事件有什么参考意义。
看了着这么多多活,又加上两个小时,有人直言,“支付宝这次的故障绝非光纤问题那么简单,而是多活切换的技术不过关。”
当然也有业内人士说到,“粗略得看支付宝并没有切换异地容灾,而是恢复了网络,虽然花的时间长了点。”
真相是什么呢,现在不得而知。不过支付宝的反应相对于1月19日微信出现短暂瘫痪时的就是不告诉你已经很有进步了。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏
腾讯混元提出CPPO方法,通过位置权重和累积前缀预算两个机制改进AI强化学习训练,在多个Qwen3模型的数学推理任务上超越现有方法,最大提升达5.56分。

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文
PaperMentor是多伦多大学等机构联合开发的AI论文写作导师,通过12个专业智能体和40余份专家技能文件,在Overleaf中为科研人员提供行内批注式的写作建议。

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"
论文揭示AI安全测试的"审计缺口":模型外表安全但内部可能脆弱,并提出潜在脆弱性分数(LVS)量化内部风险。

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
这项研究提出ICMIL框架,让AI通过在合成数据上预训练,无需针对新任务重新训练即可完成多示例学习分类,在十二个基准上超越需要调参的监督方法。

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
