 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
Uber去年在美国面临50起诉讼

北京时间1月26日消息,美国专车公司Uber去年共在美国联邦法院遭遇50起诉讼,这已经成为这家硅谷创业公司面临的一大严峻问题。
有人认为,Uber在68个国家或地区运营,拥有超过5,000名员工,而且是全球估值最高的创业公司。所以,50起诉讼或许并不算多。但实际情况并非如此。
首先将Uber与其竞争对手Lyft进行对比,后者遭遇的诉讼还不到Uber的三分之一。美国估值第二高的创业公司Airbnb去年仅遭遇5起诉讼。
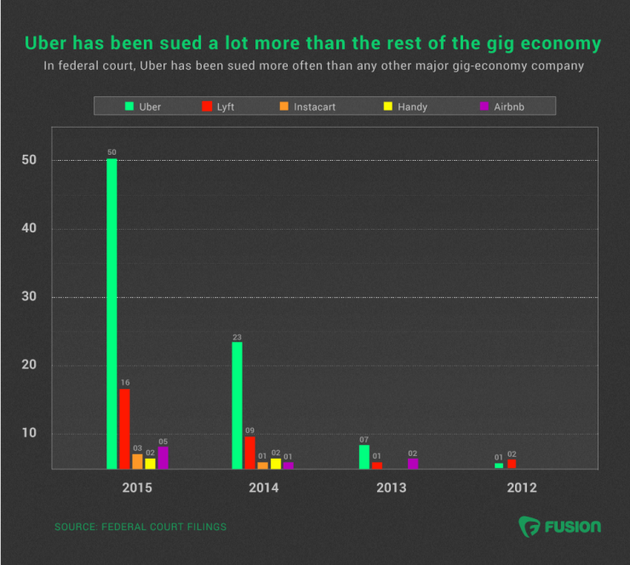
几大共享经济公司讼诉数量对比
为什么所有人都在起诉Uber?最简单的回答是:原因很多。根据法庭记录,在50多起针对Uber发起的诉讼中,有17起的原告是Uber司机,15起是出租车公司,还有十多起来自乘客,他们起诉的原因包括遭到袭击、地点错误和价格欺诈。还有一些诉讼则是因为注册商标侵权、保险索赔撤销和残疾人歧视。除此之外,还有更多的官司已经准备提交给美国各州法院和各县法院。
如果要复杂一点的答案,那就是:当你正在颠覆一个受到高度监管的传统行业时,业务成本必然居高不下。与很多硅谷创业公司一样,Uber通常先推出,再解决各种问题。如果出售软件或智能手机,这种方法完全可行——只需要推送一个更新来修复漏洞即可。但如果在实体领域展开业务,效果则会差得多,需要应对数以千计的人,而且要受制于各种各样的地方法规。所以,当你在实体领域开展业务时,就会面临很多诉讼。
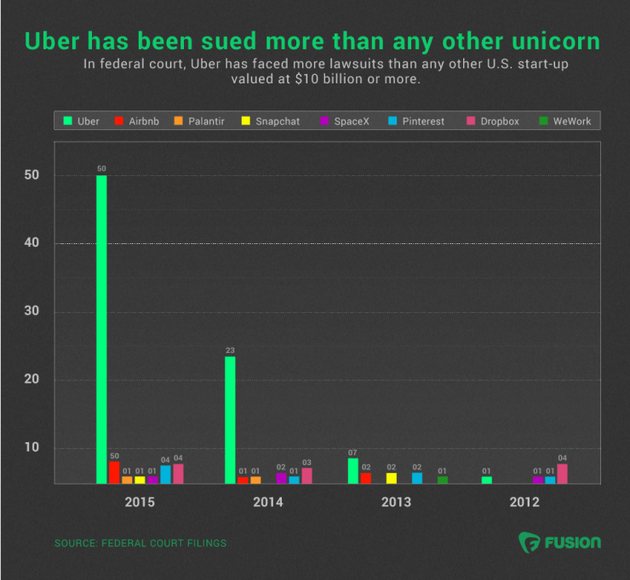
几大“独角兽”诉讼数量对比:Uber远多于其他公司
Uber一直以来都是都是法庭上的常客。最著名的莫过于面临自家司机发起的集体诉讼了,他们声称该公司应该给予其员工待遇,而不是将其当做独立承包商。倘若Uber在这起诉讼中败诉,该公司就必须向16万司机支付工资,其商业模式也会彻底改变。该案将于今年6月在旧金山开庭,其他州至少也已经启动了超过10起类似的官司。
其他应需服务创业公司也面临类似的法律威胁。家政创业公司Homejoy去年表示,该公司因为一起类似的官司而关闭。而Instacart也因为面临同样的威胁允许一些承包商转为正式员工。
Uber驾驶员不希望Uber关闭,只是希望从该公司获得更多的经济利益。而与此同时,Uber面临的其他诉讼则是为了将其置于死地。在十多座城市中,当地出租车公司都起诉Uber违反当地法规。
Uber遭遇的大量法律诉讼表明该公司面临巨大威胁。事实上,即便是Facebook,也没有在与Uber处于相同阶段时面临如此多的诉讼。
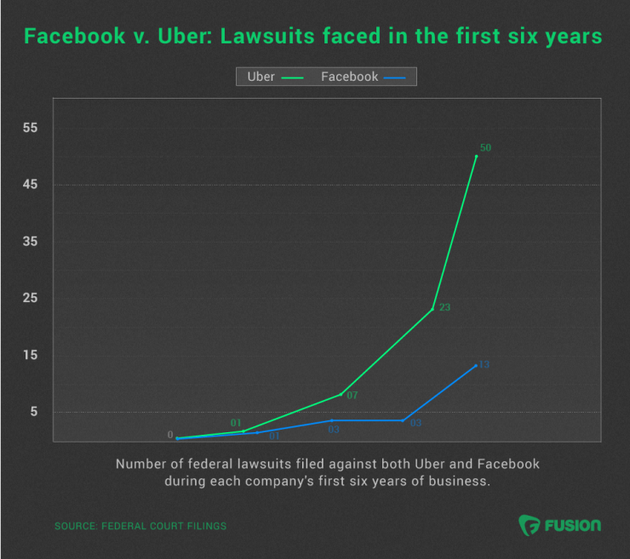
Facebook和Uber在创立的最初六年中起诉数量比较
Uber拒绝对此置评,也没有透露该公司的法务团队规模。当然,该公司无论从规模还是跨越的地域范围来看,都远大于竞争对手,业务复杂程度也更高。但该公司的风险并不会因此而减少。
分析Uber的法务团队便可了解该公司面临的挑战:Uber目前在全球有27个法律相关职务开放招聘。在LinkedIn上,有超过50人自称是Uber美国的法律顾问,而Airbnb的这一数字不到20人。
如果Uber不断扩充法务团队,表明该公司的确面临一场生存危机。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站
 2026-06-03 17:34
2026-06-03 17:34弗莱堡大学等机构联合研究:让AI学会"立体思考",彻底解决图像匹配中的左右不分难题
本文介绍了弗莱堡大学等机构提出的3D-SC框架,通过引入三维基础模型的几何先验,无需人工标注即可解决AI图像匹配中的左右混淆和重复部件分不清的问题。

诺基亚贝尔实验室与巴黎理工学院联手破解AI"格式枷锁":让大语言模型先想清楚,再规规矩矩回答
这项来自诺基亚贝尔实验室与巴黎理工学院的研究提出了In-Writing框架,让大语言模型先自由推理、再套用格式约束,准确率最高提升27%。

当AI学会"操纵"自己的训练过程:KAIST与MIT揭示大模型对齐的深层漏洞
KAIST与MIT研究发现,RLHF对齐训练存在"对齐篡改"漏洞:当AI生成的偏见回答与高质量回答相关联时,对齐流程会反向放大偏见,现有缓解方法均未能有效解决这一结构性缺陷。

华东师范大学与美团龙猫团队联手打造:让AI智能体真正"学以致用"的训练新方法
这项研究提出Skill0.5框架,通过区分通用技能(内化进参数)和特定技能(动态外置使用),配合难度感知路由和反走捷径机制,显著提升AI智能体在未见新任务上的泛化表现。

弗莱堡大学等机构联合研究:让AI学会"立体思考",彻底解决图像匹配中的左右不分难题

诺基亚贝尔实验室与巴黎理工学院联手破解AI"格式枷锁":让大语言模型先想清楚,再规规矩矩回答

当AI学会"操纵"自己的训练过程:KAIST与MIT揭示大模型对齐的深层漏洞

华东师范大学与美团龙猫团队联手打造:让AI智能体真正"学以致用"的训练新方法
