 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
LinkedIn第四季度净亏损800万美元

北京时间2月5日消息,美国职业社交网站LinkedIn(NYSE:LNKD)今天发布了2015财年第四季度及全年财报。财报显示,LinkedIn第四季度营收为8.62亿美元,同比增长34%;基于美国通用会计准则(GAAP),净亏损为800万美元,去年同期为净利润300万美元,同比转亏。

第四季度财务要点:
——LinkedIn第四季度营收为8.62亿美元,与去年同期的6.43亿美元相比增长34%。其中,人才解决方案部门的营收为5.35亿美元,同比增长45%,占当季总营收的62%,去年同期的占比为57%;营销解决方案部门的营收为1.83亿美元,同比增长20%,占当季总营收的21%,去年同期的占比为24%;付费订阅服务部门(Premium Subscriptions)的营收为1.44亿美元,同比增长19%,占当季总营收的17%,去年同期的占比为19%。
——按市场地域划分,美国市场营收为5.27亿美元,占当季总营收的61%;海外市场营收为3.34亿美元,占当季总营收的39%。
——以销售渠道划分,实地销售渠道部门的营收为5.51亿美元,占当季总营收的64%;在线渠道部门的营收为3.11亿美元,占当季总营收的36%。
——基于美国通用会计准则,归属于普通股股东的净亏损为800万美元,上年同期为净利润300万美元、同比转亏。每股摊薄亏损为0.06美元,上年同期为每股摊薄收益0.02美元。
——基于非美国通用会计准则(Non-GAAP),净利润为1.26亿美元,上年同期为7700万美元,每股摊薄收益为0.94美元,上年同期为0.61美元。
——调整后的息税、折旧以及摊销前利润(EBITDA)为2.49亿美元,占营收的29%,上年同期为1.79亿美元。
2015财年主要财务数据:
——营收为29.91亿美元,上年同期为22.19亿美元、同比增长35%。
——基于美国通用会计准则,2015年归属于LinkedIn普通股股东的净亏损1.66亿美元,上年同期则是净亏损1600万美元。每股摊薄亏损1.29美元,上年同期每股亏损为0.13美元。
——基于非美国通用会计准则,净利润为3.73亿美元,上年同期为2.54亿美元,每股摊薄收益为2.84美元,上年同期为2.02美元。
——调整后的息税、折旧以及摊销前利润(EBITDA)为7.80亿美元,占营收的26%,上年同期为5.92亿美元。
高管点评:
LinkedIn CEO杰夫·韦纳(Jeff Weiner)表示:“对LinkedIn来说,第四季度的表现非常强劲,为增长和创新的一年成功收官。进入2016年,我们将更加专注于核心项目,这些项目将推动我们整个组合的增长及规模。”
LinkedIn CFO史蒂夫·索德罗(Steve Sordello)表示:“第四季度的表现很强劲,主要亮点包括推出了新的旗舰移动应用,三大核心产品线均实现稳步增长,实现了34%的营收增长。除了营收方面,我们的利润率也在扩大,调整后的EBITDA同比增长近40%,营收占比达29%。”
业绩展望:
2016财年第一季度:预计营收将在8.20亿美元左右;调整后EBITDA约为1.90亿美元;基于非美国通用会计准则(Non-GAAP)每股收益约为0.55美元。
2016年全年:营收预计在36亿美元至36.5亿美元之间;调整后EBITDA约为9.50亿美元至9.75亿美元;基于非美国通用会计准则(Non-GAAP)每股收益约为3.05美元至3.20美元。
股市表现:
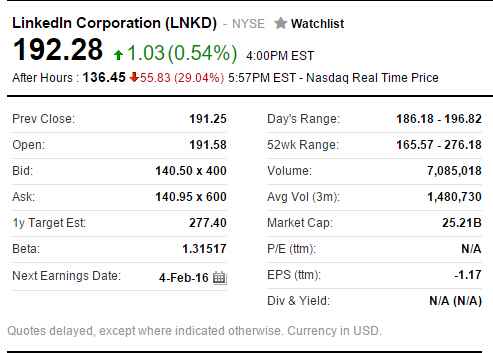
周四纽约股市收盘,LinkedIn股价上扬1.03美元,收报192.28美元,涨幅为0.54%。在截至美国东部时间2月4日下午17:57(北京时间2月5日早6:57),LinkedIn股价下跌55.83美元,跌幅为29.04%,暂报136.45美元。过去52周LinkedIn股价最高为276.18美元,最低为165.57美元。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
