 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
华为邱隆:云是服务器行业最大变局 变局中找到3个方向

CNET科技资讯网 8月18日 北京消息(文/周雅):每一年,华为服务器都会举行一次媒体沟通会,大家坐在一起聊一聊华为服务器的年度成绩和未来定位,在今年的沟通会上,华为IT服务器产品线总裁邱隆表示,云是现在服务器行业最大的一个变化,有变化就有机会。
未来华为服务器将聚焦3个方向:私有云、公有云、运营商转型。

华为IT服务器产品线总裁邱隆
华为服务器最新成绩单:4321
谈到华为服务器的最新成绩,邱隆用4321概括。
“凭借持续创新和市场份额的不断扩大,华为服务器迈入Gartner魔力四象限挑战者象限。”华为IT服务器产品线总裁邱隆在华为服务器2016媒体沟通会上指出,“近年来,尽管服务器市场格局变化加快,但华为服务器依托底层芯片和解决方案的持续积累和创新,依然保持市场最快增长。”
1、目前,华为服务器全球发货量第四,4P多路服务器增长率全球第二,模块化服务器全球第三,增长率全球第一。
2、根据Gartner报告,截止2016Q1,华为服务器出货量连续十一个月出货量全球第四。在Gartner发布的最新服务器魔力四象限报告中,华为迈入挑战者象限。
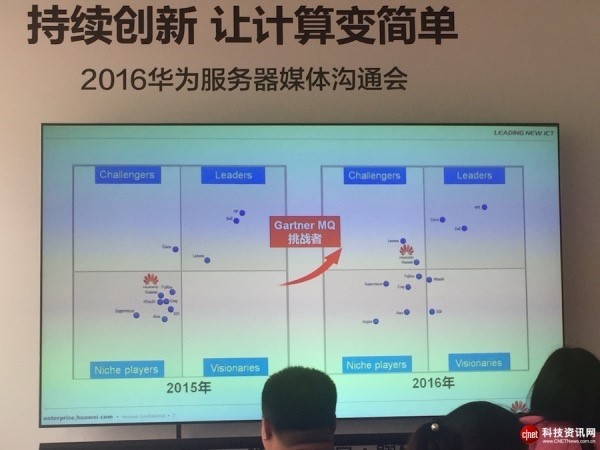
3、关键业务领域,多路服务器增长率达到全球第二,广泛应用在金融、政府的数据库、虚拟化场景。模块化服务器保持全球第三,总体发货量增长率保持业界第一。
未来聚焦3个方向
“未来将全面云化,核心业务从封闭走向开放,私有云兴起,公有云在规模效应的带动下追求极致性价比。服务器行业已经打破过去多年的稳定,加剧创新和变革。”邱隆说。
不过,邱隆话锋一转:有变化就有机会,未来华为服务器将聚焦3个方向:私有云、公有云、运营商转型,凭借长期持续投入的底层芯片到解决方案的端到端创新和积累,要做最具竞争力的计算平台,成为未来服务器行业领导者。
华为服务器内部有四个品牌,从最开始叫FusionServer,后来陆续有了FusionCube、KunLun、TaiShan。

华为服务器家族
私有云IT基础设施中,一部分关键业务会采用专有系统,且长期存在。华为KunLun开放架构小型机凭借开放生态、创新的RAS2.0可靠性和极致性能,可以帮助用户把关键业务从封闭平台部署到开放计算平台上,从而保护投资。华为FusionCube超融合基础设施则凭借深度融合分布式存储、支持混合部署、SSD加速、高速网络等特性,重构云基础设施,帮助用户实现IT转型,快速上云。
规模经济已成为公有云的商业模式和护城河。大吃小,快吃慢。邱隆的建议是,自定义服务器,摒弃一切可摒弃的。FusionServer和TaiShan凭借高质量及一系列基础创新,给计算加速,从而在公有云应用中展示出自己的独特客户价值。
云转型是全球运营商的重要发展战略。过去几年,手机、PAD移动终端快速增长,电子商务、视频、社交等互联网业务极大丰富,运营商网络流量的增长和收入增长进一步拉大差距,NFV成为重要发展方向,NFVI建设进程加快,给x86服务器带来新的增长机会。然而运营商业务对网络转发性能和可靠性要求很高,华为FusionServer凭借对运营商业务需求的深度理解,可提供满足运营商用户体验的最佳计算平台。
坚持研发投入
华为在服务器底层芯片上持续创新,软件创新积累包括:管理软件、虚拟化、大数据、分布式存储、数据库、操作系统、算法等。
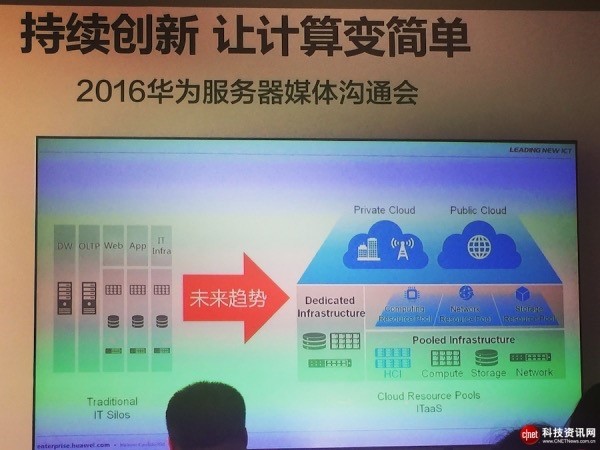
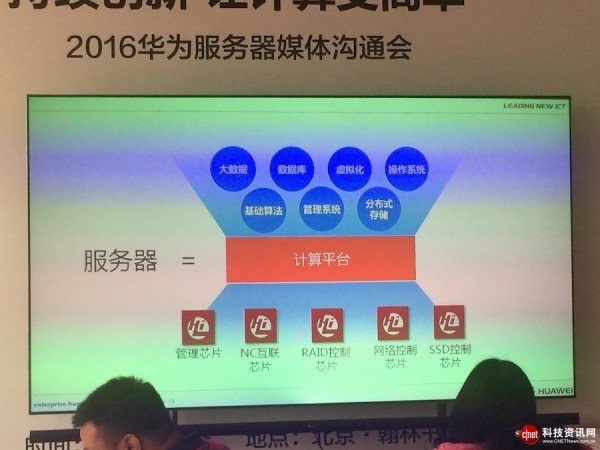
服务器行业从传统的烟囱式架构变成了计算平台
对于服务器的海外拓展之路,邱隆称,日本、西欧、北美,这三个区域将是重点的三个区域,现在发展最好的是日本市场;第二个是西欧市场,而且华为刚刚拿下俄罗斯最大的银行的大订单;北美市场,未来三年,也可能是两年,华为希望在美国做开,完全进入领导层。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。
 2026-07-01 16:42
2026-07-01 16:42阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区
MemoBench是哈佛大学等机构联合推出的视频生成评测基准,专测AI在物体消失再重现场景下的记忆能力,揭示了当前所有主流模型的核心盲区。

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
研究发现AI代码修复工具默认的"写代码→跑测试→再改"流程中,禁止运行测试几乎不影响修复成功率,却能节省超过一半的时间和费用。

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片

阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案

周雅
主编
