 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
TalkingData、优米、WeMedia推出“2016知识行家排行榜”
作者:CNET科技资讯网
2017-03-24 16:39
分享至:
目前到底有多少知识行家已经入局?各大行业数据表现最好的行家究竟是谁?
----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.-
2017-03-24 16:39 • CNET科技资讯网CNET科技资讯网 3月24日 北京消息:历时两年的发酵、升温,知识付费大幕提前拉开,很多既具有知识性又具备传播能力的“知识行家”抢占了市场先机。目前到底有多少知识行家已经入局?各大行业数据表现最好的行家究竟是谁?知识服务平台优米,第三方数据服务提供商TalkingData,和WeMedia新媒体集团,共同推出《2016知识行家排行榜》,从九大热门知识行业类目入手,评选出各垂直领域内的TOP50知识行家。
排行榜数据基于优米、喜马拉雅等知识分享平台,百度、新浪微博、微信等公开网络平台,从知识专业度、网络影响力和行业潜力多方位,综合计算得出创业、大数据、自媒体三个类别的知识行家Top50。首期对外发布的是创业、大数据、自媒体三大知识行家排行榜。

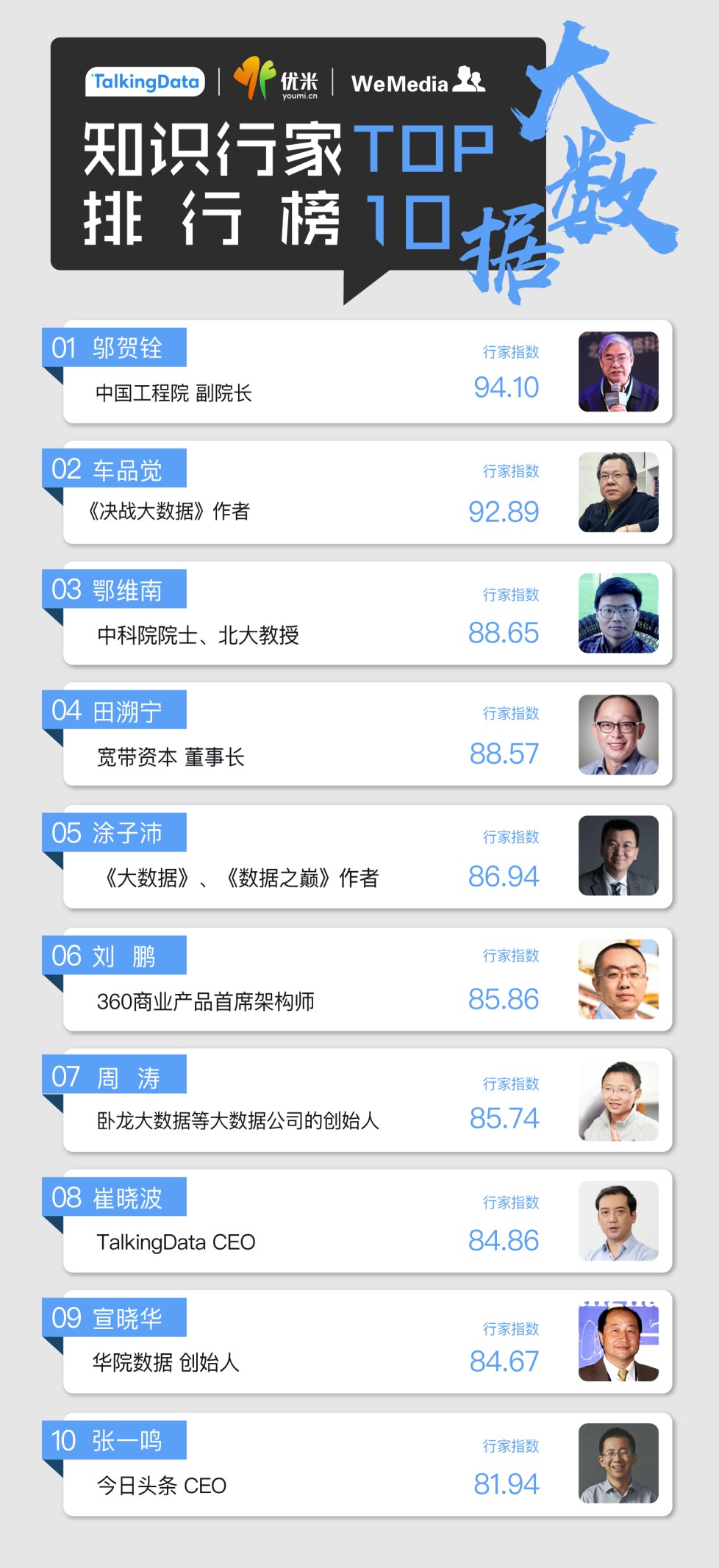

"2016知识行家TOP50"完整榜单另见优米官方网站。
分享至


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏
腾讯混元提出CPPO方法,通过位置权重和累积前缀预算两个机制改进AI强化学习训练,在多个Qwen3模型的数学推理任务上超越现有方法,最大提升达5.56分。

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文
PaperMentor是多伦多大学等机构联合开发的AI论文写作导师,通过12个专业智能体和40余份专家技能文件,在Overleaf中为科研人员提供行内批注式的写作建议。

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"
论文揭示AI安全测试的"审计缺口":模型外表安全但内部可能脆弱,并提出潜在脆弱性分数(LVS)量化内部风险。

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
这项研究提出ICMIL框架,让AI通过在合成数据上预训练,无需针对新任务重新训练即可完成多示例学习分类,在十二个基准上超越需要调参的监督方法。

腾讯混元AI强化学习新突破:让AI学习时"先想后行",避免越学越偏
2026-06-17 17:36

多伦多大学推出AI写作导师,帮你在Overleaf里改出一篇顶会论文
2026-06-17 17:18

斯坦福等高校研究:AI安全"表面过关"背后,可能藏着一颗随时被引爆的"定时炸弹"
2026-06-17 17:08

柏林工业大学团队让AI无需"刷题"就能看懂病理切片——一种全新的"举一反三"医学图像分类方法
2026-06-17 16:50

----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.- ----..---.-...-/--...-.-......./-...-....-..--../-............-.-