 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
阿里研究院给“国货”转型支招:我们有新零售
CNET科技资讯网 5月10日 北京消息:《今日美国》曾这样描述美国人一天的生活:早晨,叫醒美国人起床的闹钟有1/3印着“中国制造”;紧接着洗手间里的塑胶遮帘、体重秤、卷发器以及吹风机大多产自中国;出门上班穿的衣服有17%是“中国制造”;办公室桌子上摆放的木制书框、各类小文具同样是来自中国;晚上睡觉前,需要关闭的台灯或吊灯大约一半是“中国制造”。
作为制造大国的中国如何升级为品牌大国,扩大自主品牌的知名度和影响力?答案是依托互联网和新零售。
5月9日,天猫联合阿里研究院发布《国货突围报告》,就2016年双11期间国货品牌线上表现进行复盘。数据显示,去年双11期间,国货在线上销售额占比63%,共计902个中国品牌跻身各品类前100名,占上榜品牌总数的64%。报告同时为国货品牌的转型升级支招,新零售成品牌破局标配。

天猫引领消费升级大潮
表现亮眼的品牌无一不紧随消费升级这一大潮,借助天猫实现品牌升级和新技术引领。
以扫地机器人为例,国产扫地机器人品牌科沃斯早期发展并不顺利,接入天猫大数据之后,科沃斯针对中国市场研发了多款扫地机器人,在激烈的竞争中逐渐占据国内市场的主导地位。2016“双11”当天,科沃斯线上销售额突破4.11亿元,登上全网生活电器销售榜第一名。
再以近日发布的中国版“无印良品”——“全棉时代”母公司招股书为例,招股书显示,2016年全棉时代各渠道销售中,以天猫为代表的电商渠道销售占比超过六成。
跟全棉时代、科沃斯等品牌一样,与天猫用户一起成长,完成业绩、品牌双增长的国货品牌比比皆是。其中,家具、服装、建筑装潢、大家电、食品等五个消费大类的国货品牌在业内领跑,晒出大众、高端市场双优成绩单。
尽管增速飞快,但报告同时指出,我国国货品牌在高端市场表现仍不及整体市场。在各消费大类商品价格综合排名前20名的品牌中,国货销售金额占比仅为37%,与国际品牌在高端市场的表现仍有差距。
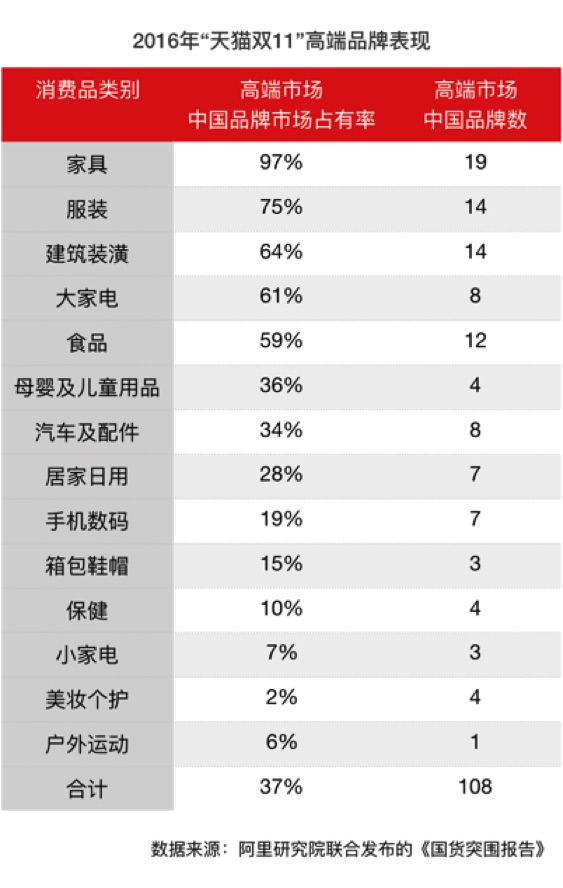
国货品牌借新零售转型成契机
国货品牌在大众市场可谓稳扎稳打,通过拥抱新零售,一系列原本面临老化的国货品牌通过互联网转型升级已势不可挡。
近年来,国货老字号百雀羚将品牌重新定位为“天然草本”,与IP、娱乐业进行跨界联合,并通过天猫打造年轻、时尚的品牌新形象,据悉,天猫双11”当天,有125万消费者购买百雀羚,成为天猫美妆类销售冠军。百雀羚的一系列转型也让“国际美妆界诺贝尔”——国际化妆品化学家联合会(IFSCC)向其伸出橄榄枝。
2015年,上海家化首次尝试全渠道,开展了以“上海家化喊你回家”为主题的“万店同庆”O2O,以子母品牌联动的形式与消费者进行全品牌全渠道互动,2016年,上海家化又成为天猫双11独家冠名商,以全网2亿的零售额创下销售纪录。
而“国民家电”美的则通过与阿里巴巴全方位合作,推动品牌在C2B定制、大数据、物联网等领域创新突破。2014年美的就与阿里合作尝试C2B反向定制产品,去年9月,更是基于YunOS系统开发打造美的智能冰箱。根据去年底美的发布的电商年度成绩单,美的全年在天猫单渠道销售突破百亿,创造了家电行业史上一个重要里程碑。

借势阿里巴巴海量的年轻用户推动新零售,天猫已成为助推国货品牌转型升级的快车道。在中国品牌日来临之际,阿里研究院为国货品牌转型升级支招:引领消费方向;占领中高端空白市场;借助新渠道新技术建立品牌认知;关注原创和个性化市场。这四点将成为品牌突围的重要方向,而贯穿其中的新零售这一关键词,也将成为中国品牌创新的根本所在。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。
 2026-07-01 16:42
2026-07-01 16:42阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区
MemoBench是哈佛大学等机构联合推出的视频生成评测基准,专测AI在物体消失再重现场景下的记忆能力,揭示了当前所有主流模型的核心盲区。

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
研究发现AI代码修复工具默认的"写代码→跑测试→再改"流程中,禁止运行测试几乎不影响修复成功率,却能节省超过一半的时间和费用。

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片

阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
