 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
《中国城市夜宵消费趋势大数据报告》出炉:90后是主力
CNET科技资讯网 7月6日 北京消息:7月6日,“国民幸福家轿”吉利新远景联合高德地图共同发布了《中国城市夜宵消费趋势大数据报告》(以下简称《报告》)。

《报告》主题为“谁在深夜寻找幸福的味道?”,从夜宵消费群体的性别、年龄、星座、出行范围、喜好品类等多个维度,呈现中国城市夜宵消费趋势。《报告》结果显示,目前夜宵人群近一半是“90后”,以男性居多,且超过7成为已婚人士;在品类上,以小龙虾为代表的小吃成为全国夜宵消费的首选。

随着夏季的来临,尤其是中国版《深夜食堂》的热播,夜宵以及夜宵中的温情故事成为时下的热点话题,夜宵已经成为极具幸福感的生活场景。主张“让幸福更进一步”的吉利新远景此次携手高德地图发布的《报告》,基于高德积累的海量出行数据,通过对全国重要城市的大数据进行计算、分析,揭晓“谁在深夜寻找幸福的味道”的答案。

《报告》显示,我国城市夜宵消费人群中,六成以上是男性,女性比例仅占38.78%,但长沙女性夜宵比例较为突出,占长沙总消费人群的44.35%,高于其他城市。
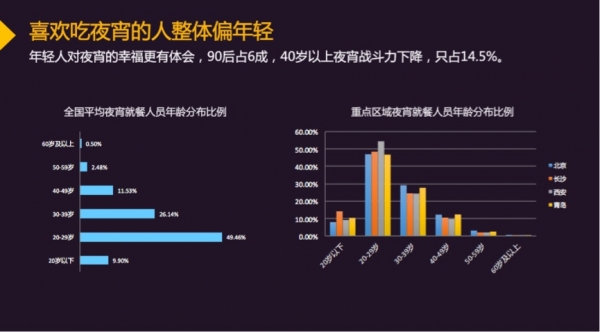
从年龄分布来看,夜宵主力为“90后”,“00后”和“90后”的总数占比达59.36%,“80后”占比26.14%。其中, 西安“90后”最为突出,占西安整体消费人群的54.47%。
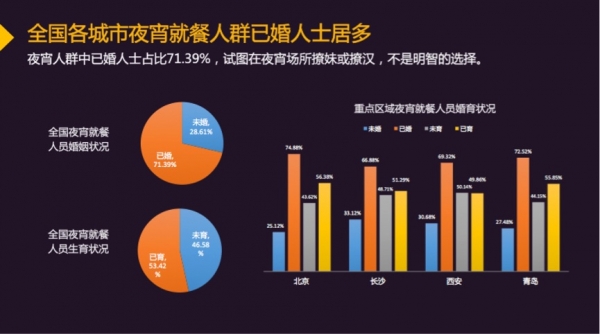
此外,数据显示已婚人士占比超过七成,其中以北京最为突出,比例到达74.88%。同时,已育人群占比53.42%高于未育人群。

天秤座成为最爱吃夜宵的星座,占比达到10.41%,成为12星座之首,处女座紧随其后,占比为9.05%,第三名是天蝎座,占比8.98%;最不爱吃夜宵的星座前三名分别为白羊座、金牛座和双子座。
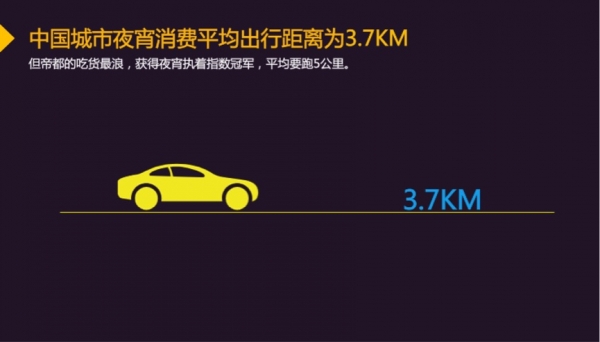
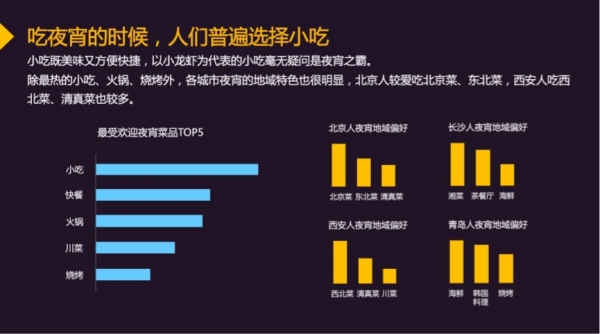
我国“吃货”为了一顿幸福佳肴可以接受的平均距离为3764米,其中北京人吃夜宵可接受的平均距离达到4984米。在夜宵品类中,以小龙虾为代表的小吃成为夜宵的首选, 其次是各类快餐,火锅位列第三。
《报告》结果显示,夜宵消费金额和人次正在逐年攀升,90后、已婚、男性、天秤座成为最喜欢在深夜找寻幸福美味的人群标签。吉利汽车销售公司副总经理宋军说:“吉利新远景作为一款“国民幸福家轿”一直致力于打造幸福的体验。这次新远景联手高德地图发布《报告》,是为了让人们知道:在深夜里通过‘夜宵’满足味觉的幸福、进而追寻更大幸福的人,还有千千万万。虽然大家的‘幸福’各自不同,但都走在‘让幸福更进一步’的路上。”
高德地图大数据研究院高级专家宋国龙表示:“通过这次《报告》的发布,我们发现虽然人们的年龄、性别、行业不同,但在同一座城市里,会有一段相近的生活轨迹,这段轨迹就是大家借助美食寻找幸福的路。不管大家的口味有什么样的差异,都希望‘幸福’是可以被感知的存在。”
关于吉利新远景
作为“国民幸福家轿”的吉利新远景是拥有近百万用户的中国轿车畅销品牌,每一辆新远景都在凭实力守护、创造用户的幸福。2017款新远景针对造型、操控、配置、安全等方面进行39项优化,让用户及其家人能够在舒适、便利、安全的用车环境中,触碰到切实的幸福感。此外吉利新远景还不断推出“买远景看海景”、“我带爸妈去看海”、“幸福家庭Party”、“幸福回家路”等一系列直击消费者心灵的“幸福拳”。以产品力为“幸福基石”、以系列“幸福拳”作为“幸福之翼”、以百万用户口碑作为“幸福薪火”,吉利新远景虽然不能满足用户对“幸福”的全部理解,却在“让幸福更进一步”的道路上不断向上进取。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。
 2026-07-01 16:42
2026-07-01 16:42阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区
MemoBench是哈佛大学等机构联合推出的视频生成评测基准,专测AI在物体消失再重现场景下的记忆能力,揭示了当前所有主流模型的核心盲区。

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
研究发现AI代码修复工具默认的"写代码→跑测试→再改"流程中,禁止运行测试几乎不影响修复成功率,却能节省超过一半的时间和费用。

当望远镜遇上"翻译官":加州大学河滨分校等机构揭秘AI如何"读懂"星系照片

阿里Qwen团队教机器人"举一反三":当AI大模型遇上机械臂,泛化能力的秘密在哪里?

当AI的"记忆"在转身瞬间消失——哈佛等联合研究团队揭开视频生成模型的致命盲区

AI代码修复工具真的需要每次都"跑一遍程序"吗?北航等机构的最新研究给出了颠覆性答案
