 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
小米MIUI 9发布会没讲的五个神秘功能

CNET科技行者 8月2日 北京消息:7月26日,小米正式发布全新MIUI 9手机操作系统,围绕基础体验,通过对系统底层10余项黑科技优化升级,成功打造了“快如闪电”般的全新操作系统。在当天发布会上,小米联合创始人、MIUI负责人洪锋主要介绍了闪电系统和照片查找、信息助手和传送门三大创新功能。

实际上,MIUI 9的升级更新远远不止发布会上提到的内容,下面笔者就带大家去了解MIUI 9在发布会上没有讲到的五大重磅升级。
MIUI 9分屏模式,从此可以“一心两用”
分屏功能用户呼声一直很高,本次MIUI 9系统终于带来全新分屏功能。该功能基于Adroid原生系统开发,操作更加人性化、本土化。MIUI 9分屏默认上方是保持不变的主任务,下方是可以任意替换的副应用,可以让用户在分屏模式下仍然可以切换任务,做其他更多的手机操作。

目前MIUI 9支持分屏的应用包括,但不限于:大部分MIUI系统应用、微信、微博、淘宝、爱奇艺、腾讯视频、优酷、BiliBili、腾 讯新闻、高德地图、QQ 音乐、手机百度、美团、WPS、知乎、QQ 邮箱。随着越来越多开发者支持 Android 分屏, 将来会有越来越多的应用支持MIUI分屏。
MIUI直达服务,不用安装APP也可以“秒开”享受服务
相信不少人会遇到这样的情况,某种情况下突然需要使用一个手机App功能,可是此前并没有下载。这时候就需要现下载应用,然后才可以使用。不着急的情况下还好,如果遇到紧急情况就会很麻烦。而且该应用可能一个月用不了几次,卸载的话日后还要用到;不卸载可是使用频次很低,要占用手机的存储空间,让人左右为难。MIUI 9推出的直达服务功能就可以完美解决这一问题。

比如我们要用快看漫画客户端,但又没有安装它的APP,只需要在全局搜索框输入要查到的App名,很快MIUI 9便会给出搜索结果。在结果栏还提供了“秒开”按钮,点击后不需要进入App直接便可以使用快看漫画。即便是我们此前的手机中没有安装此App,MIUI 9的直达服务功能同样可以正常使用该App,不需要下载安装,对手机的存储压力大大减小。
MIUI 9通知过滤,可以聪明应对各种通知消息打扰
相信很多人每天都会被很多无用的消息推送骚扰,每次下拉菜单看到满屏的推送消息,连看的心情都没有了。MIUI 9对此进行大胆革新,对通知类信息进行过滤,无用的信息会整合到一个菜单中,减少对用户使用手机的垃圾信息困扰。
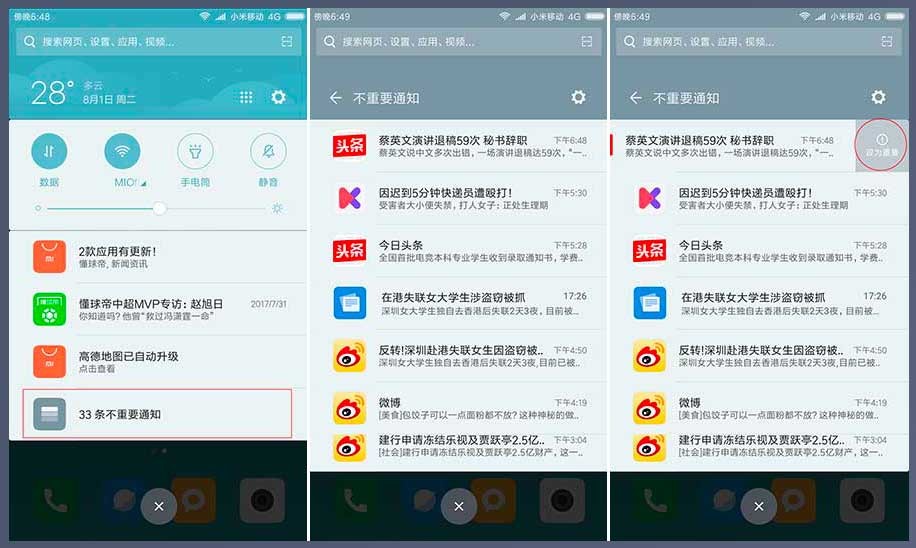
本次MIUI 9的通知过滤并非简单粗暴的简单聚合屏蔽,而是依托智能学习,通过分析通知信息的打开、删除、屏蔽等操作,对各类消息评分,从而推断出对用户有效的信息,日后不会对此类消息屏蔽。
MIUI 9优化静音模式,更贴心更实用
静音模式的优化升级是本次MIUI 9在细节优化上的一个重要体现。全新升级后的MIUI 9静音模式设置更加方便,只需要在解锁状态,轻按音量键,唤出音量控制菜单,便可以直接开启静音或者勿扰模式。
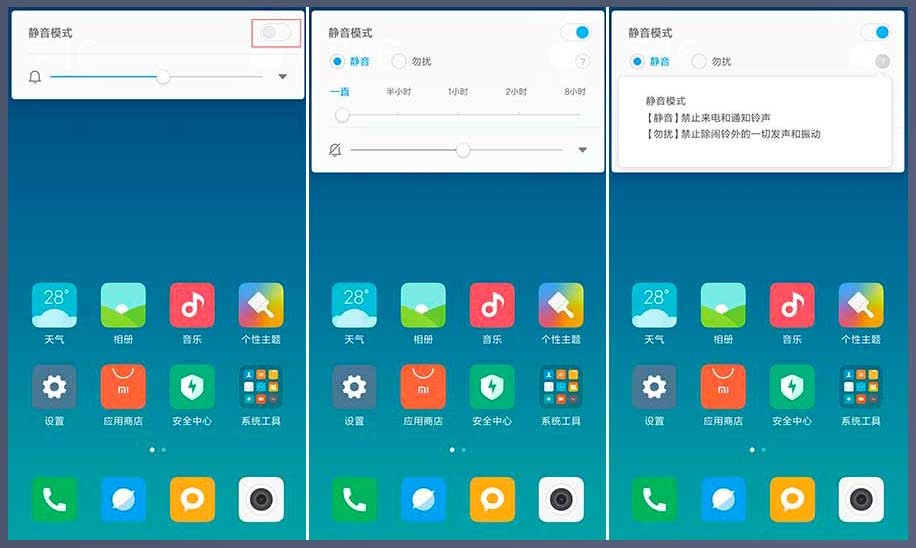
通过上图可以看到,MIUI 9静音模式可以一键开启,并且可以根据需要设置静音时长。开启静音模式后,手机会屏蔽手机来电和通知的铃声。如果是开始勿扰模式,则手机会禁止除了闹钟外的一切声音和振动。除此之外,还可以进入设置菜单,对静音模式进行更加细致的设置,比如每周固定时间段静音或者勿扰,以及静音模式下同一号码重复来电会取消静音等。这些小的细节优化再次彰显MIUI的用心,让你可以应对各种不同的使用场景。
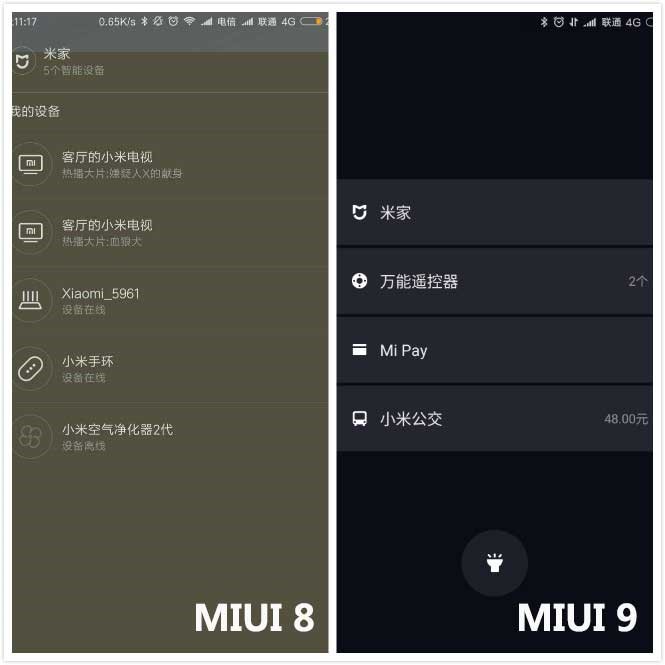
MIUI 9锁屏功能升级 更加实用方便
体验过MIUI 8系统的米粉相信对于MIUI的锁屏功能会有所了解,在锁屏状态下右滑就可以呼出一个全新的界面。MIUI 9系统对于该页面功能进行了重新优化升级,加入了万能遥控器、Mi Pay、小米公交和手电筒功能的入口。如此一来,要使用这几项功能不需要解锁手机,在锁屏状态下向右滑动就可以直接使用,尤其是手电筒功能加入到锁屏界面,更加实用方便。
上面提到的五个功能都是本次发布会上没有重点讲到的,但笔者个人认为这些功能无论从实用性还是细节的人性化处理下都值得我们为MIUI点赞。当然MIUI 9的更新还远不止这些,随着新机型的不断适配,未来除了小米1/1s和小米2A的用户,其他所有用户都将获得MIUI 9开发版的升级推送,届时大家也可以细细体会MIUI的用心之处。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值
芝加哥大学等机构将强化学习引入大型强子对撞机触发系统,用GFPO方法实现阈值自适应调整,显著提升信号效率并保持背景率稳定,首次在真实CMS碰撞数据上完成验证。

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿
英伟达发布Audex多模态大模型,在音频理解与生成达到最优水平的同时,保持文字推理能力几乎零退步,提供完整技术路径。

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节
南加州大学研究揭示语音抑郁检测中"时序聚合"环节的系统性盲点:72个测试组合中三分之一完全失效,骨干网络选择的影响丝毫不亚于聚合架构本身。

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
斯坦福与根特大学联合提出"变化感知最优采样"方法,无需训练模型,通过匹配历史变化模式筛选AI胸片报告候选,印象部分RadGraph F1提升最高达13.6%。

粒子物理学的"门卫"进化了:芝加哥大学等机构用强化学习让大型强子对撞机自动调节探测阈值

英伟达造出了一个"既会说话又会听歌"的超级AI,而且完全不忘记原本的聪明劲儿

当语音测谎仪遇上抑郁筛查:南加州大学的这项研究揭示了一个被忽视的关键环节

斯坦福大学与根特大学联手:让AI读片"懂历史",胸片报告质量大幅提升
