 微信扫一扫,关注公众号
微信扫一扫,关注公众号

科技行者

算力行者
见证连接与计算的「力量」
英伟达掌舵人黄仁勋 :人工智能计算的新纪元,就是要省钱!(附演讲PPT)

英伟达掌舵人黄仁勋,在GTC2017上再掀京城“AI风云”。

▲ NVIDIA CEO 黄仁勋
上场后“老黄”直接开怼,终于说出了人们憋在心中许久的结论——摩尔定律已终结。
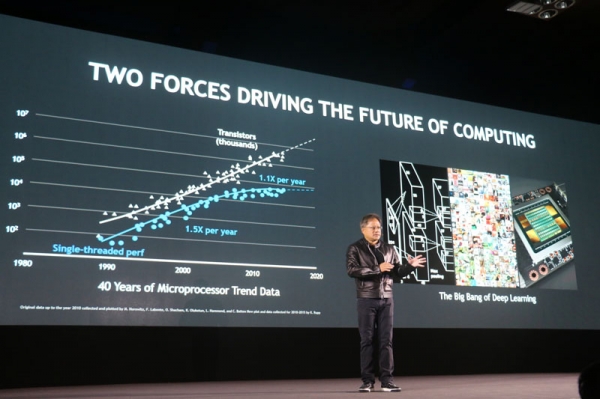
▲ 两股力量推动计算领域的未来
但,NVIDIA的GPU计算为整个行业指出了前进的道路。
他指出,设计人员无法再创造出可以实现更高之灵系并行性的CPU架构;晶体管数每年增长50%,但CPU的性能每年仅增长10%。而NVIDIA的GPU弥补CPU的不足,加速处理高强度计算负载。
深度学习另一大“杀伤性武器”:CUDA
CUDA是一种革命性的计算架构,它将专用功能ASIC的性能与通用编程模型相结合,使开发人员实现多种算法。目前CUDA开发人员的数量在5年里增长了14倍超过60万,下载量达到180万。

▲ 适用于全球开发人员的NVIDIA AI
AI是NVIDIA CUDA GPU的“杀手级应用”,AI取得惊人进步。
阿里巴巴、百度和腾讯已在各自的云服务中采用NVIDIA Volta GPU。
华为、浪潮和联想已采用NVIDIA基于HGX的GPU服务器。
此外,NVIDIA还在为全球开发员人配置强大AI工具,全力推进“统一架构”CUDA GPU计算。
AI推理是下一个巨大挑战,重磅发布 TensorRT 3
AI推理平台必须具备可编程性,高性能,且支持庞大和复杂的网络。
随着智能机器的爆发性增长,AI会将智能注入到2000万台云服务器、上亿台汽车和制造机器人中。所以,AI推理平台必须可扩展,以解决海量计算的性能、功耗和成本需求。

▲ 宣布NVIDIA TensorRT 3
于是,老黄又来搞事了。
宣布NVIDIA TensorRT 3,全球首款可编程AI推理加速器。
TensorRT是一款适用于CUDA GPU的优化神经网络编译器,它可利用CUDA深度学习指令集创建运行时。从云、数据中心、PC、汽车到机器人,TensorRT皆能在NVIDIA全系列平台便宜出最优运行时。

▲ 运行在 V100上的 TensorRT在处理图像时可实现7ms的延时
运行的Volta上的TensorRT3在图像分类方面,比最快的CPU还要快40倍,在语言翻译方面则要快140倍。
搭配 Tesla V100 GPU 加速器的 TensorRT 每秒能够识别多达 5700 张图片,而如今所用的 CPU 则每秒仅能识别 140 张图片。
AI城市是一个巨大的AI推理挑战,它可能需要使用大约1000万个Tesla V100 GPUs来监控10亿台摄像头。

▲ NVIDIA AI城市-助力中国建设更智慧、更安全的城市
NVIDIA将携手海康威视共建AI城市。此外,大华、华为和阿里巴巴都提供基于NVIDIA平台的AI视频解决方案。
AI另一重头戏:自动驾驶汽车
NVIDIA DRIVE是一个为自动驾驶行业带来变革的端到端平台。NV自动驾驶计算机可以支持L3、L4和L5级。开放软件栈包含从ASIL-D OS、深度学习、计算机视觉 SDK 到自动驾驶应用。

▲ 开放的自动驾驶计算平台
DRIVE AV是NVIDIA开发的自动驾驶应用,环绕摄像头、雷达和激光雷达的传感数据融合。多种深度学习和计算机视觉将为L4和L5级别自动回家是技术提供所需的多样性和冗余性。
目前,145家初创公司正在研制基于NVIDIA DRIVE的自动驾驶汽车、卡车、高清制图及服务。
推全球首款自主机器处理器 Xavier
NVIDIA设计了全球首款自主机器的处理器,命名Xavier。

▲ 全球首款自主机器处理器
它是迄今为止最为复杂的片上系统,将于18年第一季度早期接触合作伙伴提供,在第四季度全面推出。
京东X选择 NVIDIA实现其自主机器,采用Jetson平台。而Xavier将成为下一代Jetson的片上系统(SOC)。

▲ 最后,谢谢各位合作伙伴AND老板们的支持!
老黄Keynote总结:计算新纪元,就是要省钱!
NVIDIA Tesla V100AI平台已经被中国领军的IT公司采用,包括阿里巴巴、百度、腾讯、华为、浪潮和联想。
业内首创的NVIDIA可编程推理加速平台已被阿里巴巴、百度、腾讯、科大讯飞和京东采用。
NVIDIA AI城市平台已被阿里巴巴、海康威视、大华和华为采用,以解决最大规模的AI和推理难题之一。
NVIDIA DRIVE——引领自动驾驶变革的开放平台,已被145家自动驾驶初创公司采用。
NVIDIA“Xavier”——全球首款自主机器处理器将在第一季度发布样片,并将揭开人工智能时代的新篇章。
关注科技行者微信账号(微信号:itechwalker),打开对话界面回复“黄仁勋”,可获得【GTC2017黄仁勋演讲】完整版高清PPT。


好文章,需要你的鼓励

至顶头条

科技行者

码客人生

奇客Solidot

高飞的电子替身

奇客情报站

南方科技大学等机构联手破解AI推理训练难题:让大模型"一次思考"就学会解题
本文介绍了由南方科技大学等机构于2026年4月发表的研究(arXiv:2604.08865),提出了名为SPPO的大模型推理训练新方法。该方法将推理任务重新建模为"序列级情境赌博机",用一个轻量级价值模型预测题目难度,以单次采样替代GRPO的多次采样,解决了标准PPO的"尾部效应"问题。实验显示,SPPO在数学基准测试上超越GRPO,训练速度提升约5.9倍,配合小尺寸价值模型还能显著降低显存占用。

香港科技大学数学系研究者:扩散模型原来是一个"魔法恒等式"拆成了两半
这项由香港科技大学数学系完成的研究(arXiv:2604.10465,2026年ICLR博客论文赛道)提出了一种从朗之万动力学视角理解扩散模型的统一框架。研究指出,扩散模型的前向加噪和逆向去噪过程,本质上是朗之万动力学这一"分布恒等操作"被拆成了两半。在这个视角下,VP、VE-Karras和Flow Matching等不同参数化的模型可被精确互译,SDE与ODE版本可被统一解释,扩散模型相对VAE的理论优势得以阐明,Flow Matching与得分匹配的等价性也得到了严格论证。

中国人民大学研究团队打造的"AI科学家":让机器自主完成几十小时的科研工程,它是怎么做到的?
中国人民大学高岭人工智能学院等机构联合开发了AiScientist系统,旨在让AI自主完成机器学习研究的完整工程流程,包括读论文、搭环境、写代码、跑实验和迭代调试,全程无需人工干预。系统核心设计是"薄控制、厚状态":由轻量指挥官协调专业代理团队,通过"文件即通道"机制将所有中间成果持久化存储,使每轮工作都能建立在前一轮积累的基础上。在PaperBench和MLE-Bench Lite两个基准上,系统表现显著优于现有最强对比系统,论文发布于2026年4月。

字节跳动发布GRN:像人类画家一样"边画边改"的AI图像生成新范式
这项由字节跳动发布的研究(arXiv:2604.13030)提出了生成式精化网络(GRN),一套模仿人类画家"边画边改"直觉的视觉生成新框架。其核心包括两项创新:层级二进制量化(HBQ)通过多轮二分逼近实现近乎无损的离散图像编码,以及全局精化机制允许模型在每一步对整张图像的所有位置重新预测并随时纠错,从根本上解决了自回归模型的误差积累问题。配合基于熵值的自适应步数调度,GRN在ImageNet图像重建(rFID 0.56)和生成(gFID 1.81)上均创下新纪录,并在文本生成图像和视频任务上以20亿参数达到同等规模方法的领先水平。

南方科技大学等机构联手破解AI推理训练难题:让大模型"一次思考"就学会解题

香港科技大学数学系研究者:扩散模型原来是一个"魔法恒等式"拆成了两半

中国人民大学研究团队打造的"AI科学家":让机器自主完成几十小时的科研工程,它是怎么做到的?

字节跳动发布GRN:像人类画家一样"边画边改"的AI图像生成新范式
